En cliquant sur « Accepter tous les cookies », vous acceptez le stockage de cookies sur votre appareil pour améliorer la navigation sur le site, analyser son utilisation et contribuer à nos efforts de marketing. Plus d’infos
Paramètres des cookies
En cliquant sur « Accepter tous les cookies », vous acceptez le stockage de cookies sur votre appareil pour améliorer la navigation sur le site, analyser son utilisation et contribuer à nos efforts de marketing. Plus d’infos
Explorez les différents types de techniques d'apprentissage automatique et d'apprentissage profond utilisées dans les applications de vision par ordinateur, de l'apprentissage supervisé à l'apprentissage par transfert.
L'apprentissage automatique est un type d'intelligence artificielle (IA) qui aide les ordinateurs à apprendre des données afin qu'ils puissent prendre des décisions par eux-mêmes, sans avoir besoin d'une programmation détaillée pour chaque tâche. Il implique la création de modèles algorithmiques capables d'identifier des schémas dans les données. En identifiant les schémas dans les données et en apprenant d'eux, ces algorithmes peuvent progressivement améliorer leurs performances au fil du temps.
L'un des domaines où l 'apprentissage automatique joue un rôle crucial est celui de la vision artificielle, un domaine de l'intelligence artificielle qui se concentre sur les données visuelles. La vision par ordinateur utilise l'apprentissage automatique pour aider les ordinateurs à detect et à reconnaître des modèles dans les images et les vidéos. Grâce aux progrès de l'apprentissage automatique, la valeur du marché mondial de la vision par ordinateur est estimée à environ 175,72 milliards de dollars d'ici à 2032.
Dans cet article, nous allons examiner les différents types d'apprentissage automatique utilisés dans la vision par ordinateur, y compris l'apprentissage supervisé, non supervisé, par renforcement et par transfert, et comment chacun joue un rôle dans différentes applications. Commençons !
Aperçu de l'apprentissage automatique dans le domaine de la vision par ordinateur
En fait, de nombreux modèles avancés de vision par ordinateur, tels que Ultralytics YOLO11sont basés sur des réseaux neuronaux.
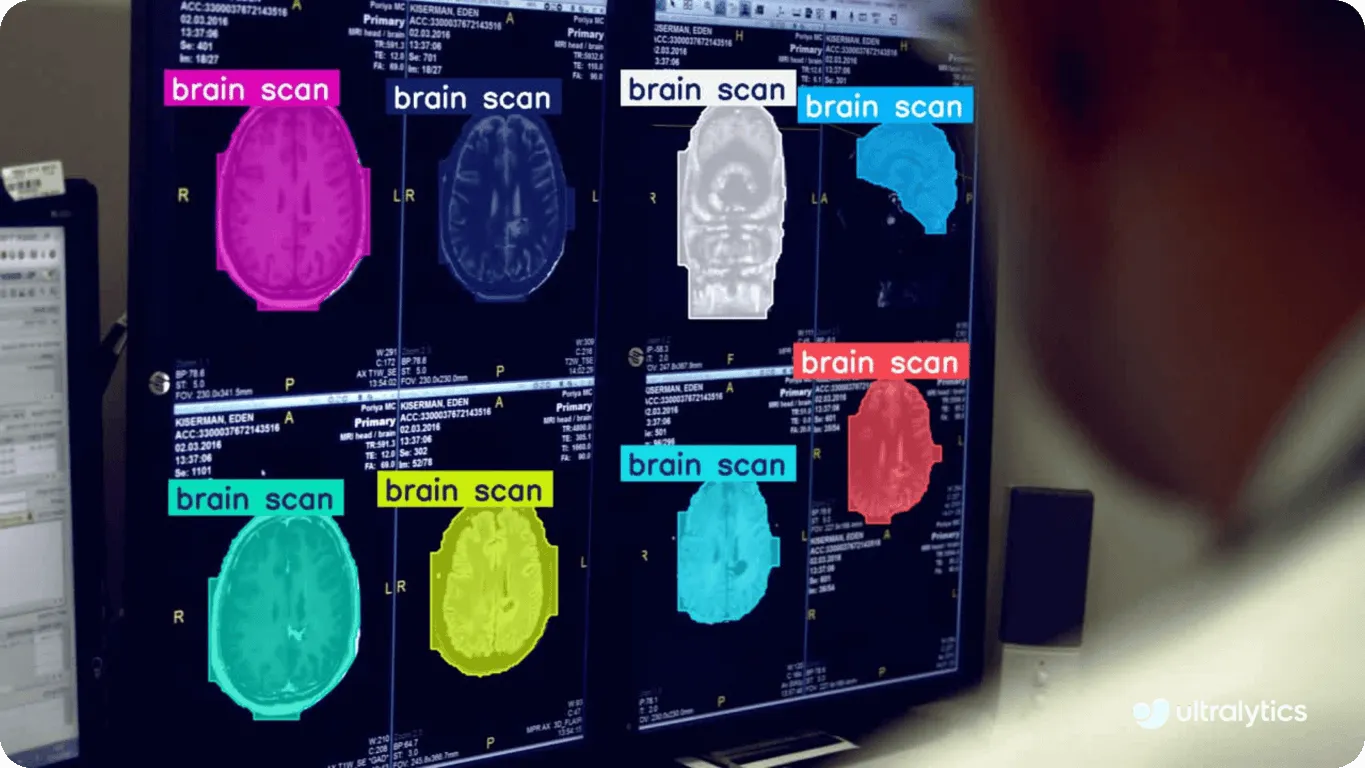
Fig. 1. Segmentation de scans cérébraux à l'aide d'Ultralytics YOLO11.
Il existe plusieurs types de méthodes d'apprentissage dans l'apprentissage automatique, comme l'apprentissage supervisé, l'apprentissage non supervisé, l'apprentissage par transfert et l'apprentissage par renforcement, qui repoussent les limites de ce qui est possible en vision artificielle. Dans les sections suivantes, nous explorerons chacun de ces types pour comprendre comment ils contribuent à la vision artificielle.
Exploration de l'apprentissage supervisé
L'apprentissage supervisé est le type d'apprentissage automatique le plus couramment utilisé. Dans l'apprentissage supervisé, les modèles sont entraînés à l'aide de données étiquetées. Chaque entrée est étiquetée avec la sortie correcte, ce qui aide le modèle à apprendre. Semblable à un étudiant qui apprend d'un enseignant, ces données étiquetées servent de guide ou de superviseur.
Pendant l'entraînement, le modèle reçoit à la fois des données d'entrée (les informations qu'il doit traiter) et des données de sortie (les réponses correctes). Cette configuration aide le modèle à apprendre le lien entre les entrées et les sorties. L'objectif principal de l'apprentissage supervisé est que le modèle découvre une règle ou un modèle qui relie avec précision chaque entrée à sa sortie correcte. Grâce à cette mise en correspondance, le modèle peut faire des prédictions précises lorsqu'il rencontre de nouvelles données. Par exemple, la reconnaissance faciale en vision par ordinateur repose sur l'apprentissage supervisé pour identifier les visages en fonction de ces modèles appris.
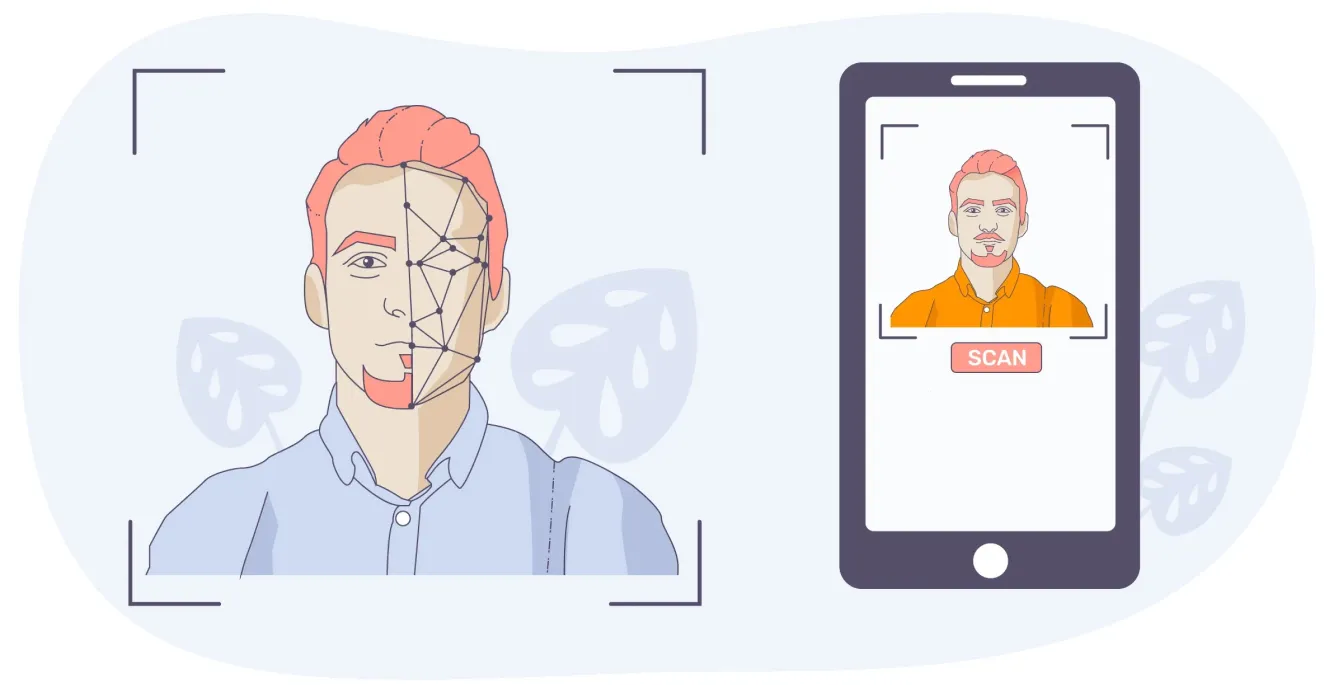
Une utilisation courante de cette technologie est le déverrouillage de votre smartphone grâce à la reconnaissance faciale. Le modèle est entraîné sur des images étiquetées de votre visage, de sorte que, lorsque vous déverrouillez votre téléphone, il compare l'image en direct avec ce qu'il a appris. S'il détecte une correspondance, votre téléphone se déverrouille.
Fig 2. La reconnaissance faciale peut être utilisée pour déverrouiller votre smartphone.
Comment fonctionne l'apprentissage non supervisé dans l'IA ?
L'apprentissage non supervisé est un type d'apprentissage automatique qui utilise des données non étiquetées - le modèle ne reçoit aucune indication ni réponse correcte pendant l'entraînement. Au lieu de cela, il apprend à découvrir des modèles et des informations par lui-même.
L'apprentissage non supervisé identifie les modèles en utilisant trois méthodes principales :
Clustering : Regroupe les points de données similaires. Il est utile pour des tâches telles que la segmentation de la clientèle, où des clients similaires peuvent être regroupés en fonction de leurs comportements ou de leurs attributs.
Association : Elle est utilisée pour identifier les relations entre les éléments, aidant à découvrir les liens au sein des données (par exemple, trouver les produits souvent achetés ensemble dans le cadre de l’analyse du panier de marché).
Réduction de la dimensionnalité : Simplifie les ensembles de données en supprimant les caractéristiques redondantes, ce qui facilite la visualisation et le traitement.
Une application clé de l'apprentissage non supervisé est la compression d'image, où des techniques comme le clustering k-means réduisent la taille de l'image sans affecter la qualité visuelle. Les pixels sont regroupés en clusters, et chaque cluster est représenté par une couleur moyenne, ce qui donne une image avec moins de couleurs et une taille de fichier plus petite.
Fig 3. Un exemple de compression d'image non supervisée.
Cependant, l'apprentissage non supervisé fait face à certaines limites. Sans réponses prédéfinies, il peut avoir du mal avec la précision et l'évaluation des performances. Il nécessite souvent un effort manuel pour interpréter les résultats et étiqueter les groupes, et il est sensible aux problèmes tels que les valeurs manquantes et le bruit, ce qui peut avoir un impact sur la qualité des résultats.
Explication de l'apprentissage par renforcement
Contrairement à l'apprentissage supervisé et non supervisé, l'apprentissage par renforcement ne repose pas sur des données d'entraînement. Il utilise plutôt des agents de réseau neuronal pour interagir avec un environnement afin d'atteindre un objectif spécifique.
Le processus implique trois composantes principales :
Agent : L'apprenant ou le décideur.
Environnement : Tout ce avec quoi l'agent interagit, qu'il soit réel ou virtuel.
Signal de récompense : Une valeur numérique donnée après chaque action, guidant l'agent vers l'objectif.
Au fur et à mesure que l'agent agit, il affecte l'environnement, qui réagit ensuite par un retour d'information. Ce retour d'information aide l'agent à évaluer ses choix et à ajuster son comportement. Le signal de récompense aide l'agent à comprendre quelles actions le rapprochent de la réalisation de son objectif.
L'apprentissage par renforcement est essentiel pour les cas d'utilisation tels que la conduite autonome et la robotique. Dans la conduite autonome, les tâches telles que les commandes du véhicule, la détection et l'évitement d'objets apprennent en fonction du retour d'information. Des modèles sont formés à l'aide d'agents de réseaux neuronaux pour detect piétons ou d'autres objets et prendre les mesures appropriées pour éviter les collisions. De même, en robotique, l'apprentissage par renforcement permet d'accomplir des tâches telles que la manipulation d'objets et le contrôle des mouvements.
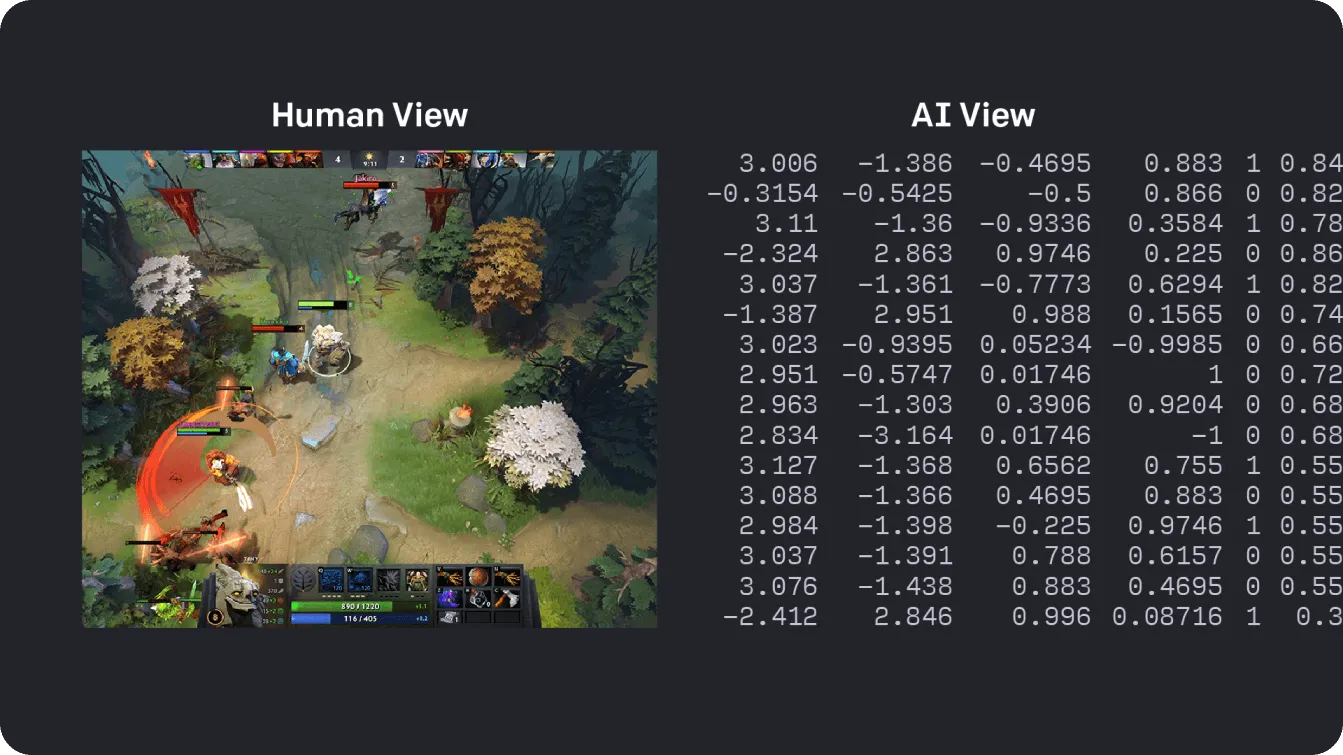
Un excellent exemple d'apprentissage par renforcement en action est un projet d'OpenAI, où des chercheurs ont entraîné des agents d'IA pour jouer au populaire jeu vidéo multijoueur, Dota 2. En utilisant des réseaux de neurones, ces agents ont traité d'immenses quantités d'informations provenant de l'environnement du jeu pour prendre des décisions rapides et stratégiques. Grâce à une rétroaction continue, les agents ont appris et se sont améliorés au fil du temps, atteignant finalement un niveau de compétence suffisamment élevé pour battre certains des meilleurs joueurs du jeu.
Fig 4. Interprétation de la matrice Dota par l'humain et l'IA.
Comprendre les bases de l'apprentissage par transfert
L'apprentissage par transfert est différent des autres types d'apprentissage. Au lieu d'entraîner un modèle à partir de zéro, il utilise un modèle pré-entraîné sur un grand ensemble de données et l'affine pour une nouvelle tâche connexe. Les connaissances acquises lors de l'entraînement initial sont utilisées pour améliorer la performance de la nouvelle tâche. L'apprentissage par transfert réduit le temps nécessaire à l'entraînement pour une nouvelle tâche, en fonction de sa complexité. Il fonctionne en conservant les couches initiales du modèle qui capturent les caractéristiques générales et en remplaçant les couches finales par celles de la nouvelle tâche spécifique.
Le transfert de style artistique est une application intéressante de l'apprentissage par transfert dans la vision par ordinateur. Cette technique permet à un modèle de transformer une image pour qu'elle corresponde au style de différentes œuvres d'art. Pour ce faire, un réseau neuronal est d'abord entraîné sur un vaste ensemble de données d'images associées à leurs styles artistiques. Grâce à ce processus, le modèle apprend à identifier les caractéristiques générales de l'image et les motifs de style.
Une fois le modèle entraîné, il peut être affiné pour appliquer le style d'une peinture spécifique à une nouvelle image. Le réseau s'adapte à la nouvelle image tout en préservant les caractéristiques de style apprises, ce qui lui permet de créer un résultat unique qui combine le contenu original avec le style artistique sélectionné. Par exemple, vous pouvez prendre une photo d'une chaîne de montagnes et appliquer le style du Cri d'Edvard Munch, ce qui donne une image qui capture la scène mais avec le style audacieux et expressif de la peinture.
Fig 5. Un exemple de transfert de style artistique utilisant l'apprentissage par transfert.
Un aperçu des différences entre les types d'apprentissage machine
Maintenant que nous avons couvert les principaux types d'apprentissage automatique, examinons de plus près chacun d'eux pour vous aider à comprendre ce qui convient le mieux aux différentes applications.
Apprentissage supervisé : Ce type d'apprentissage est très précis lorsqu'il est utilisé avec des données étiquetées, mais il nécessite une grande quantité de données et peut être sensible au bruit.
Apprentissage non supervisé : Il est utile pour explorer des données non étiquetées afin de trouver des schémas cachés, bien que les résultats puissent être moins précis et plus difficiles à interpréter.
Apprentissage par renforcement : Il forme les agents à prendre des décisions étape par étape dans des environnements complexes, mais nécessite souvent une puissance de calcul importante.
Apprentissage par transfert : Cette approche utilise des modèles pré-entraînés pour accélérer l'entraînement et améliorer les performances sur de nouvelles tâches, en particulier lorsque les données sont limitées.
Fig 6. Une comparaison de tous les types d'apprentissage automatique. Image de l'auteur.
Le choix du bon type d'apprentissage automatique dépend de plusieurs facteurs. L'apprentissage supervisé fonctionne bien si vous disposez de nombreuses données étiquetées et d'une tâche claire. L'apprentissage non supervisé est utile pour l'exploration de données ou lorsque les exemples étiquetés sont rares. L'apprentissage par renforcement est idéal pour les tâches complexes nécessitant une prise de décision étape par étape, tandis que l'apprentissage par transfert est idéal lorsque les données sont limitées ou que les ressources sont contraintes. En tenant compte de ces facteurs, vous pouvez sélectionner l'approche la plus appropriée pour votre projet de vision par ordinateur.
Conclusion
Les techniques d'apprentissage automatique peuvent s'attaquer à divers défis, en particulier dans des domaines comme la vision par ordinateur. En comprenant les différents types d'apprentissage (supervisé, non supervisé, par renforcement et par transfert), vous pouvez choisir la meilleure approche pour vos besoins.
L'apprentissage supervisé est idéal pour les tâches nécessitant une grande précision et des données étiquetées, tandis que l'apprentissage non supervisé est idéal pour trouver des modèles dans des données non étiquetées. L'apprentissage par renforcement fonctionne bien dans des contextes complexes basés sur la prise de décision, et l'apprentissage par transfert est utile lorsque vous souhaitez vous appuyer sur des modèles pré-entraînés avec des données limitées.
Chaque méthode a des forces et des applications uniques, de la reconnaissance faciale à la robotique en passant par le transfert de style artistique. Le choix du bon type peut ouvrir de nouvelles possibilités dans des secteurs tels que la santé, l'automobile et le divertissement.