



ビジョンモデルの歴史、成果、課題、および将来の方向性を探ります。

ビジョンモデルの歴史、成果、課題、および将来の方向性を探ります。
カメラがあなたの顔を識別し、気分を分析し、あなたの好みに合わせた製品をリアルタイムで提案する店に足を踏み入れることを想像してみてください。これはSFではなく、最新のビジョンモデルによって実現された現実です。Fortune Business Insightによるレポートによると、世界のコンピュータビジョン市場規模は2023年に203億1000万米ドルと評価され、2024年の254億1000万米ドルから2032年までに1757億2000万米ドルに成長すると予測されており、これはさまざまな業界での急速な進歩とこの技術の採用の増加を反映しています。
コンピュータビジョンの分野は、コンピュータが画像内の物体をdetect、識別、分析することを可能にする。他のAI関連分野と同様に、コンピュータビジョンも過去数十年の間に急速な進化を遂げ、目覚ましい進歩を遂げてきた。
コンピュータビジョンの歴史は広範囲に及びます。初期の頃、コンピュータビジョンモデルは単純な形状やエッジを検出することができましたが、多くの場合、幾何学的パターンの認識や明暗領域の区別などの基本的なタスクに限定されていました。しかし、今日のモデルは、リアルタイムの物体検出、顔認識、さらには顔の表情から感情を解釈するなど、非常に正確かつ効率的に複雑なタスクを実行できます。この劇的な進歩は、計算能力、アルゴリズムの洗練、およびトレーニングに使用できる大量のデータの利用可能性における信じられないほどの進歩を浮き彫りにしています。
この記事では、コンピュータビジョンの進化における主要なマイルストーンを探ります。その初期の始まりをたどり、畳み込みニューラルネットワーク(CNN)の変革的な影響を掘り下げ、その後に続く重要な進歩を検証します。
他のAI分野と同様に、コンピュータビジョンの初期の開発は、基礎研究と理論的研究から始まりました。重要なマイルストーンは、ローレンス・G・ロバーツによる3D物体認識に関する先駆的な研究であり、彼の論文「Machine Perception of Three-Dimensional Solids」(1960年代初頭)に記録されています。彼の貢献は、この分野における将来の進歩の基礎を築きました。
初期のコンピュータビジョンの研究は、エッジ検出や特徴抽出などの画像処理技術に焦点を当てていた。1960年代後半に開発されたソーベル演算子のようなアルゴリズムは、画像強度の勾配を計算することによってエッジをdetect する最初のもののひとつであった。

SobelやCannyのエッジ検出器のような技術は、画像内の境界を識別する上で重要な役割を果たしました。これらは、オブジェクトを認識し、シーンを理解するために不可欠です。
1970年代には、パターン認識がコンピュータビジョンの重要な分野として登場しました。研究者たちは、画像内の形状、テクスチャ、およびオブジェクトを認識する方法を開発し、より複雑なビジョンタスクへの道を開きました。

パターン認識の初期の方法の1つに、テンプレートマッチングがあります。これは、画像をテンプレートのセットと比較して、最適な一致を見つける方法です。このアプローチは、スケール、回転、およびノイズの変動に敏感であるという制限がありました。
初期のコンピュータビジョンシステムは、当時の限られた計算能力によって制約されていました。1960年代と1970年代のコンピュータは、かさばり、高価で、処理能力が限られていました。
ディープラーニングと畳み込みニューラルネットワーク(CNN)は、コンピュータビジョンの分野において極めて重要な転換点となりました。これらの進歩は、コンピュータが視覚データを解釈および分析する方法を劇的に変革し、以前は不可能と考えられていた幅広いアプリケーションを可能にしました。
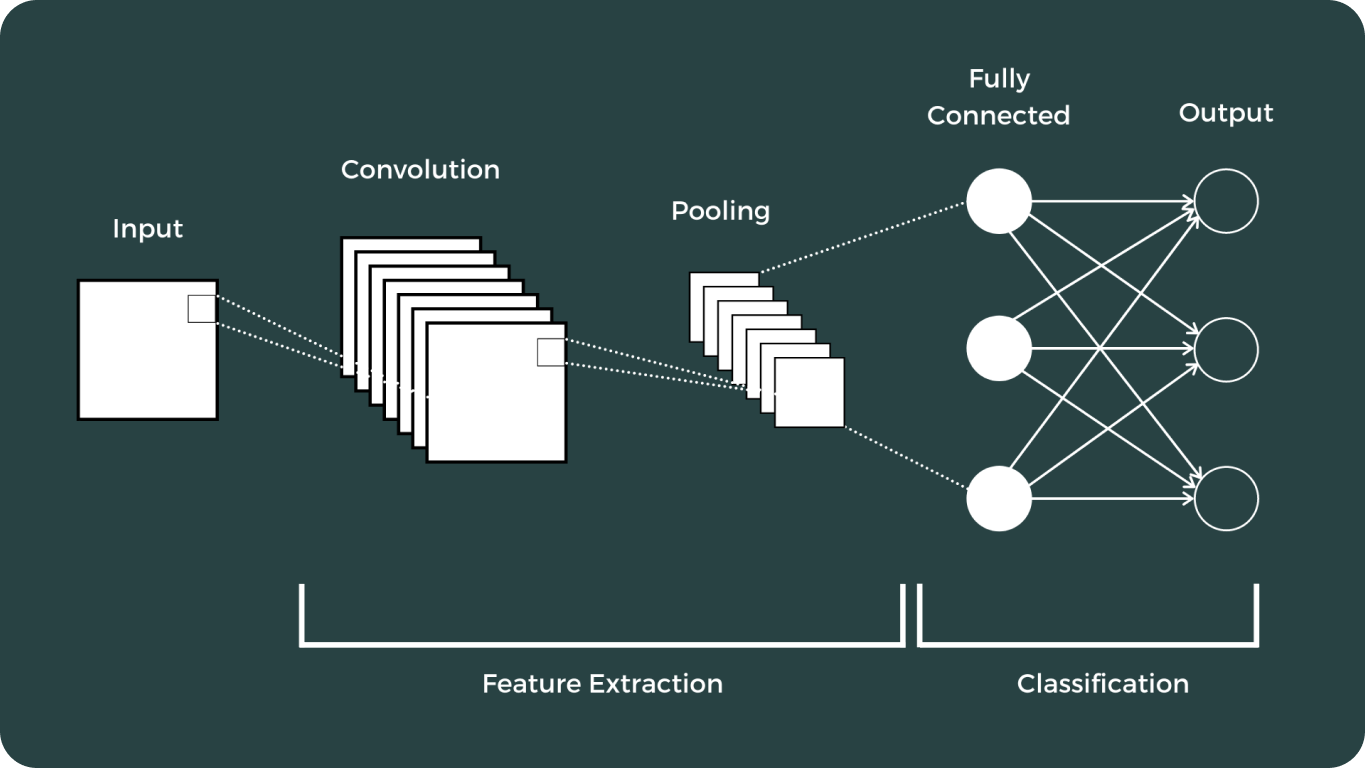
ビジョンモデルの道のりは長く、最も注目すべきものをいくつか紹介します。
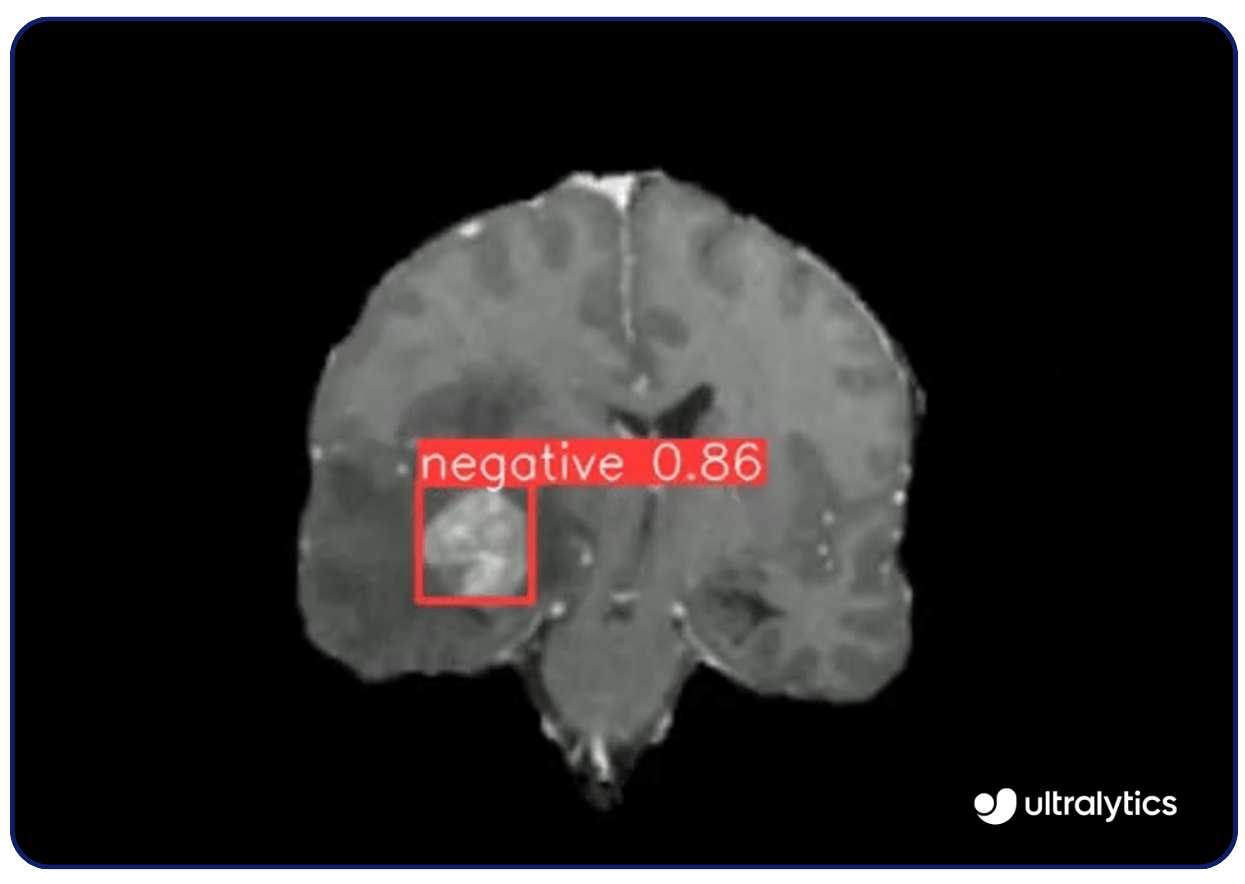
コンピュータ・ビジョンの用途は数多くあります。例えば Ultralytics YOLOv8のようなビジョンモデルは、ガンや糖尿病性網膜症などの病気をdetect するための医療画像診断に利用されている。X線、MRI、CTスキャンを高精度で解析し、早期に異常を特定する。この早期発見能力により、タイムリーな介入が可能になり、患者の転帰が改善される。
コンピュータ・ビジョンのモデルは、野生動物の生息地から画像やビデオを分析することによって、絶滅危惧種の監視と保護に役立っている。動物の行動を識別・track し、個体数や移動に関するデータを提供する。この技術は、トラやゾウのような種を保護するための保護戦略や政策決定に役立っている。
ビジョンAIの助けを借りて、山火事や森林破壊などの他の環境的脅威を監視し、地方自治体からの迅速な対応を確保できます。

すでに大きな成果を上げているにもかかわらず、ビジョンモデルは、その極度の複雑さと開発の要求の厳しい性質のために、継続的な研究と将来の進歩を必要とする多くの課題に直面しています。
ビジョンモデル、特に深層学習モデルは、多くの場合、透明性の低い「ブラックボックス」と見なされます。これは、そのようなモデルが非常に複雑であるためです。解釈可能性の欠如は、特に医療などの重要なアプリケーションにおいて、信頼と説明責任を妨げます。
最先端のAIモデルのトレーニングと展開には、多大な計算リソースが必要です。これは特に、大量の画像およびビデオデータの処理を必要とするビジョンモデルに当てはまります。高解像度の画像とビデオは、最もデータ集約的なトレーニング入力の1つであり、計算負荷を増大させます。たとえば、1つのHD画像で数メガバイトのストレージを占有する可能性があり、トレーニングプロセスがリソースを消費し、時間がかかります。
これには、効果的なビジョンモデルの開発に関わる広範なデータと複雑な計算を処理するための、強力なハードウェアと最適化されたコンピュータビジョンアルゴリズムが必要です。より効率的なアーキテクチャ、モデル圧縮、およびGPUやTPUなどのハードウェアアクセラレータの研究は、ビジョンモデルの将来を前進させるための重要な分野です。
これらの改善は、計算負荷を軽減し、処理効率を高めることを目的としている。さらに、次のような高度な事前学習済みモデルを活用する。 YOLOv8のような高度な事前学習済みモデルを活用することで、大規模なトレーニングの必要性を大幅に減らし、開発プロセスを合理化し、効率を高めることができます。
今日、ビジョンモデルのアプリケーションは、腫瘍検出などのヘルスケアから、交通監視のような日常的な用途まで、広範囲に及んでいます。これらの高度なモデルは、これまで想像もできなかった精度、効率、および機能を提供することにより、数え切れないほどの業界に革新をもたらしました。
テクノロジーが進化し続けるにつれて、ビジョンモデルが生活と産業のさまざまな側面を革新し、改善する可能性は無限に残されています。この継続的な進化は、コンピュータビジョンの分野における継続的な研究開発の重要性を強調しています。
ビジョンAIの未来に興味がありますか?Ultralytics ドキュメントや、Ultralytics GitHubや YOLOv8 GitHubのプロジェクトをご覧ください。さらに、様々な業界におけるAIアプリケーションの洞察については、自動運転車と 製造業のソリューションページが特に有益な情報を提供しています。


