



Claude 3モデルカードと、それがVision AI開発に与える影響をご覧ください。

Claude 3モデルカードと、それがVision AI開発に与える影響をご覧ください。
近年、Vision AIは大きな進歩を遂げ、ヘルスケアから小売まで、さまざまな業界に革命をもたらしています。これらの進歩を効果的に活用するには、基盤となるモデルとそのドキュメントを理解することが重要です。人工知能(AI)開発者の武器庫におけるそのような不可欠なツールの1つは、AIモデルの特性とパフォーマンスの包括的な概要を提供するモデルカードです。
この記事では、Anthropic社によって開発された Claude 3モデルカードと、Vision AI開発へのその影響について探る。 Claude 3は、3つのバリエーションからなる大型マルチモーダルモデルの新しいファミリーである:最も高性能な「Claude 3 Opus」、性能とスピードのバランスが取れた「Claude 3 Sonnet」、最も高速でコスト効率の良い「Claude 3 Haiku」です。各モデルには新たにビジョン機能が搭載され、画像データの処理と解析が可能になった。
モデルカードとは一体何でしょうか?モデルカードとは、機械学習モデルの開発、トレーニング、評価に関する洞察を提供する詳細なドキュメントです。モデルの機能、意図されたユースケース、潜在的な制限に関する明確な情報を提供することにより、透明性、説明責任、AIの倫理的な使用を促進することを目的としています。これは、評価指標、以前のモデルや他の競合他社との比較など、モデルに関するより詳細なデータを提供することで実現できます。
評価指標は、モデルの性能を評価するために重要です。 Claude 3のモデルカードには、精度、適合率、再現率、F1スコアなどの指標が記載されており、モデルの強みと改善の余地が明確に示されています。 これらの指標は業界標準に対してベンチマークされており、Claude 3の競争力のある性能を示しています。
さらに、Claude 3は、アーキテクチャとトレーニング技術の進歩を取り入れ、前モデルの強みを活かしています。モデルカードでは、Claude 3と以前のバージョンを比較し、精度、効率、および新しいユースケースへの適用性の向上を強調しています。
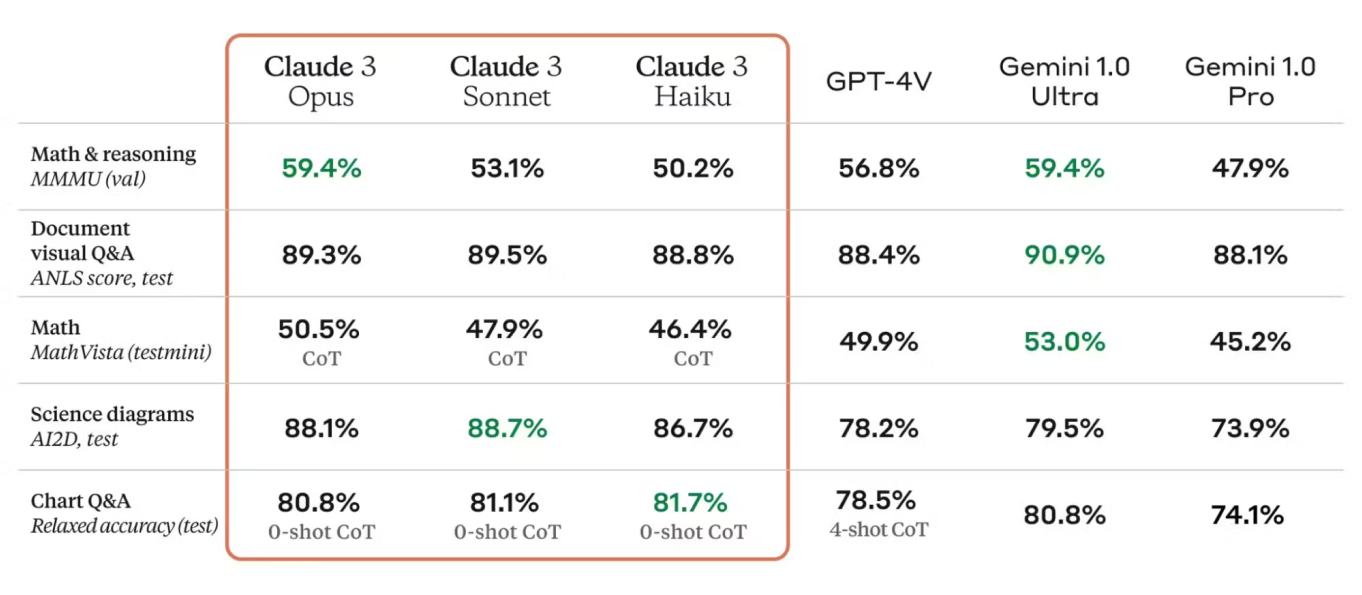
Claude 3のアーキテクチャとトレーニングプロセスにより、さまざまな自然言語処理(NLP)および視覚タスクで信頼性の高いパフォーマンスが得られます。ベンチマークで一貫して優れた結果を達成し、複雑な言語分析を効果的に実行する能力を示しています。
Claude 3は、多様なデータセットでのトレーニングとデータ拡張技術の使用により、その堅牢性とさまざまなシナリオにわたって一般化する能力を保証します。これにより、モデルは汎用性が高く、幅広いアプリケーションで効果的です。
その結果は注目に値するが、Claude 3は基本的に大規模言語モデル(LLM)である。Claude 3のようなLLMは様々なコンピュータビジョンタスクを実行できるが、物体検出、境界ボックスの作成、画像セグメンテーションなどのタスクのために特別に設計されたものではない。そのため、これらの分野での精度は、以下のようなコンピュータビジョン用に特別に作られたモデルには及ばないかもしれません。 Ultralytics YOLOv8.とはいえ、LLMは他の領域、特に自然言語処理(NLP)において優れており、クロード3は単純な視覚タスクと人間の推論を融合させることで、大きな強みを発揮している。

NLP(自然言語処理)の能力とは、AIモデルが人間の言語を理解し、応答する能力を指します。この能力は、Claude 3の視覚分野におけるアプリケーションで高度に活用されており、文脈に沿った豊富な説明の提供、複雑な視覚データの解釈、Vision AIタスクにおける全体的なパフォーマンスの向上を可能にします。
Claude 3の優れた機能の1つは、特にVision AIタスクに活用した場合、判読が難しい手書きの低品質画像を処理してテキストに変換できることです。この機能は、モデルの高度な処理能力とマルチモーダル推論能力を示しています。このセクションでは、Claude 3がこのタスクをどのように実行するかを探り、Vision AI開発の基盤となるメカニズムと影響を強調します。
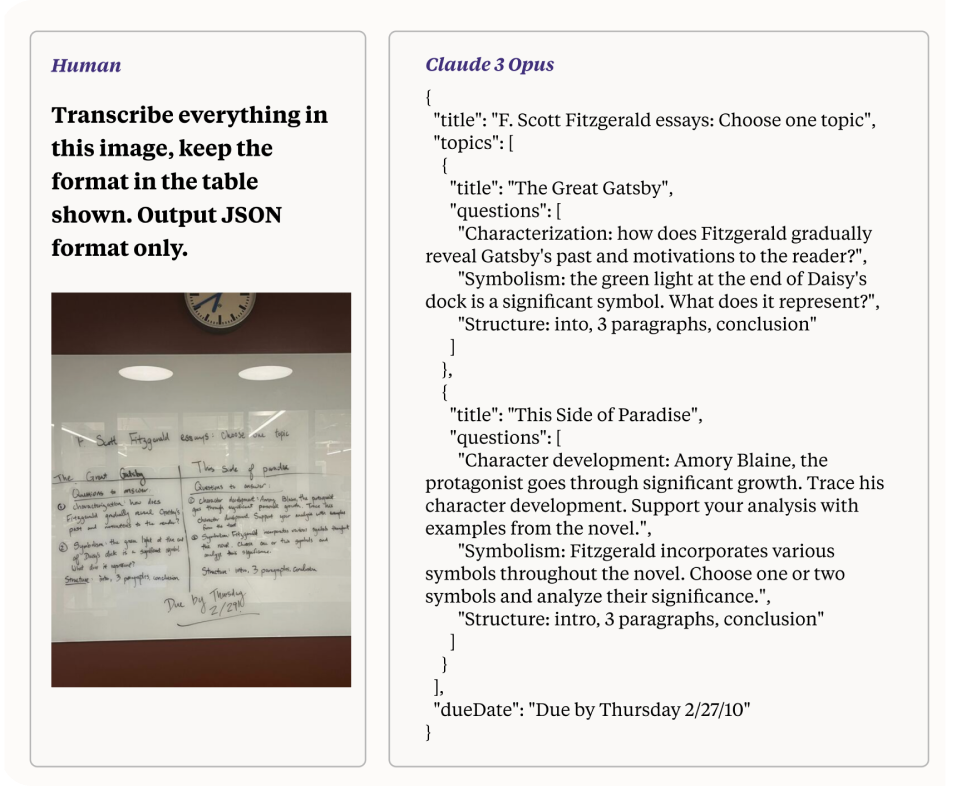
判読が難しい手書きの低品質な写真をテキストに変換することは、いくつかの課題を伴う複雑なタスクです。
前述のように、Claude 3モデルは、コンピュータビジョンと自然言語処理(NLP)の高度な技術を組み合わせることで、これらの課題に対処します。
Claude 3のアーキテクチャにより、視覚的な入力を使用して複雑な推論タスクを実行できます。たとえば、図1に示すように、モデルはインターネット利用に関するグラフなどのチャートやグラフを解釈し、G7諸国を識別し、関連データを抽出し、傾向を分析するための計算を実行できます。年齢層間のインターネット利用の統計的差異を計算するなどのこの複数ステップの推論により、モデルの精度と実際のアプリケーションでの有用性が向上します。

Claude 3は、画像を詳細な説明に変換することに優れており、コンピュータビジョンと自然言語処理の両方におけるその強力な能力を示しています。画像が与えられると、Claude 3はまず、畳み込みニューラルネットワーク(CNN)を使用して、主要な特徴を抽出し、視覚データ内のオブジェクト、パターン、およびコンテキスト要素を識別します。
次に、Transformerレイヤーがこれらの特徴を分析し、注意機構を活用して画像内の異なる要素間の関係とコンテキストを理解します。このマルチモーダルなアプローチにより、Claude 3はオブジェクトを識別するだけでなく、シーン内での相互作用や重要性を理解することで、正確で文脈に富んだ記述を生成できます。

Claude 3のような大規模言語モデル(LLM)は、コンピュータ・ビジョンではなく、自然言語処理を得意とする。画像を記述することはできるが、物体検出や画像セグメンテーションのようなタスクは、YOLOv8ようなビジョン指向のモデルの方がうまく処理できる。これらの特化されたモデルは、視覚タスクに最適化されており、画像を分析するのに優れた性能を発揮する。さらに、このモデルはバウンディングボックスの作成などのタスクを実行することはできない。
Claude 3をコンピュータビジョンシステムと組み合わせることは複雑になる可能性があり、テキストデータと視覚データのギャップを埋めるために追加の処理手順が必要になる場合があります。
Claude 3は主に大量のテキストデータでトレーニングされているため、コンピュータビジョンタスクで高いパフォーマンスを達成するために必要な広範な視覚データセットが不足しています。その結果、Claude 3はテキストの理解と生成に優れていますが、視覚データ用に特別に設計されたモデルに見られるのと同じレベルの習熟度で画像を処理または分析する機能はありません。この制限により、視覚コンテンツの解釈または生成を必要とするアプリケーションでは、効果が低下します。
他の大規模言語モデルと同様に、Claude 3は継続的な改善が見込まれています。今後の機能強化は、画像検出や物体認識などの視覚タスクの改善、および自然言語処理タスクの進歩に重点が置かれる可能性があります。これにより、他の同様のタスクの中でも、物体やシーンをより正確かつ詳細に記述できるようになります。
最後に、Claude 3に関する継続的な研究では、解釈可能性の向上、バイアスの軽減、および多様なデータセットにわたる一般化の改善を優先します。これらの取り組みにより、モデルのさまざまなアプリケーションにおける堅牢なパフォーマンスが保証され、その出力に対する信頼性と信頼性が高まります。
Claude 3のモデルカードは、Vision AIの開発者および関係者にとって貴重なリソースであり、モデルのアーキテクチャ、パフォーマンス、および倫理的考慮事項に関する詳細な洞察を提供します。透明性と説明責任を促進することにより、AI技術の責任ある効果的な使用を保証するのに役立ちます。Vision AIが進化し続けるにつれて、Claude 3のようなモデルカードの役割は、開発を導き、AIシステムへの信頼を育む上で非常に重要になります。
Ultralytics、AI技術の発展に情熱を注いでいます。私たちのAIソリューションを探求し、最新のイノベーションの最新情報を入手するには、GitHubリポジトリをご覧ください。Discordのコミュニティに参加して、自動運転車や 製造業などの業界をどのように変革しているかをご覧ください!🚀


