



Metaの新しいLlama 3.1オープンソースモデルファミリーをご覧ください。汎用性の高い8B、万能型の70B、そして最大かつ最先端のフラッグシップモデルである405Bが特徴です。

Metaの新しいLlama 3.1オープンソースモデルファミリーをご覧ください。汎用性の高い8B、万能型の70B、そして最大かつ最先端のフラッグシップモデルである405Bが特徴です。
2024年7月23日、Metaは新しいLlama 3.1オープンソースモデルファミリーをリリースしました。汎用性の高い8B、高性能な70B、そして最新のLlama 3.1 405Bモデルが特徴で、これは現在最大のオープンソース大規模言語モデル(LLM)として際立っています。
これらの新しいモデルが以前のモデルと何が違うのか疑問に思われるかもしれません。この記事を読み進めていくうちに、Llama 3.1モデルのリリースがAI技術における重要なマイルストーンであることがわかるでしょう。新しくリリースされたモデルは、自然言語処理において大幅な改善を提供します。さらに、以前のバージョンにはなかった新機能と拡張機能が導入されています。このリリースは、複雑なタスクにAIを活用する方法を変革し、研究者や開発者にとって強力なツールセットとなることが期待されます。
この記事では、Llama 3.1モデルファミリーのアーキテクチャ、主な改良点、実用的な用途、そしてパフォーマンスの詳細な比較について解説します。
Metaの最新の大規模言語モデルであるLlama 3.1は、 OpenAIのChat GPT-4oや Anthropic Claude 3.5 Sonnetのようなトップクラスのモデルに匹敵する能力を持ち、AIの分野で大きな進歩を遂げている。
以前のLlama 3モデルのマイナーアップデートと見なされるかもしれませんが、Metaは新しいモデルファミリーにいくつかの重要な改良を加え、次のような機能を提供することで、さらに一歩前進しました:
上記に加え、新しいLlama 3.1モデルファミリーは、4,050億パラメータという驚異的なモデルで大きな進歩を遂げました。この膨大なパラメータ数は、AI開発における大きな飛躍を意味し、複雑なテキストを理解し生成するモデルの能力を大幅に向上させます。405Bモデルには広範なパラメータが含まれ、各パラメータは学習中にモデルが学習するニューラルネットワークのweights and biases 相当します。これにより、モデルはより複雑な言語パターンを捉えることができ、大規模言語モデルの新たな基準を設定し、AI技術の将来の可能性を示している。この大規模モデルは、幅広いタスクのパフォーマンスを向上させるだけでなく、テキスト生成と理解という点で、AIが達成できることの限界を押し広げる。
Llama 3.1は、最新の大規模言語モデルの基礎となるデコーダー専用のTransformerモデルアーキテクチャを活用しています。このアーキテクチャは、複雑な言語タスクを処理する際の効率と有効性で知られています。Transformerを使用することで、Llama 3.1は人間のようなテキストの理解と生成に優れており、LSTMやGRUなどの古いアーキテクチャを使用するモデルよりも大きな利点があります。
さらに、Llama 3.1モデルファミリーは、トレーニングの効率と安定性を高めるMixture of Experts (MoE)アーキテクチャを利用しています。MoEアーキテクチャを回避することで、MoEがモデルの安定性とパフォーマンスに影響を与える可能性のある複雑さをもたらすことがあるため、より一貫性のある信頼性の高いトレーニングプロセスが保証されます。
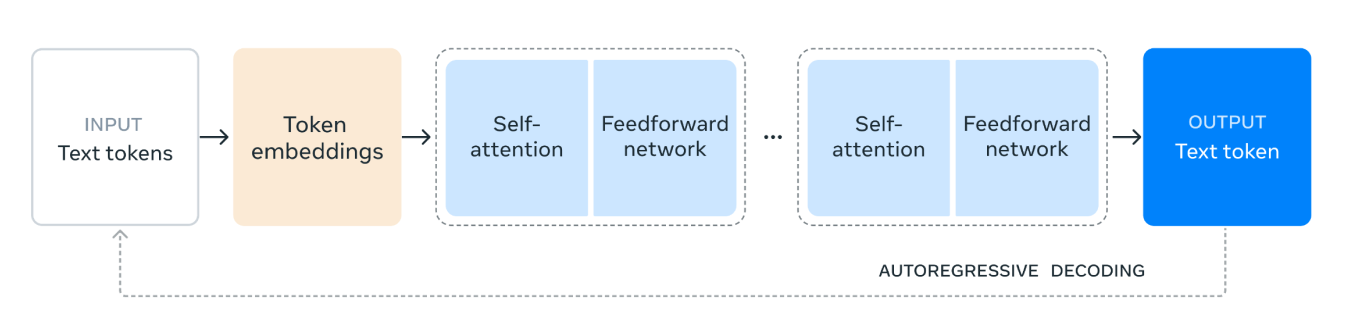
Llama 3.1モデルアーキテクチャは、次のように機能します。
1. 入力テキストトークン: プロセスは、テキストトークンで構成される入力から始まります。これらのトークンは、モデルが処理する単語やサブワードなどのテキストの個々の単位です。
2. トークン埋め込み: 次に、テキストトークンはトークン埋め込みに変換されます。埋め込みは、テキスト内のトークンの意味的意味と関係を捉えたトークンの密なベクトル表現です。この変換は、モデルが数値データを処理できるようにするために重要です。
3. セルフアテンションメカニズム: セルフアテンションにより、モデルは各トークンをエンコードする際に、入力シーケンス内の異なるトークンの重要度を評価できます。このメカニズムは、モデルがシーケンス内の位置に関係なく、トークン間のコンテキストと関係を理解するのに役立ちます。セルフアテンションメカニズムでは、入力シーケンス内の各トークンは数値のベクトルとして表されます。これらのベクトルは、クエリ、キー、値の3つの異なるタイプの表現を作成するために使用されます。
モデルは、クエリベクトルとキーベクトルを比較することにより、各トークンが他のトークンにどれだけ注意を払う必要があるかを計算します。この比較により、他のトークンとの関係における各トークンの関連性を示すスコアが得られます。
4.フィードフォワードネットワーク:自己注意プロセスの後、データはフィードフォワードネットワークを通過する。このネットワークは完全連結ニューラルネットワークであり、データに非線形変換を適用し、モデルが複雑なパターンを認識し、学習するのを助ける。
5. 繰り返しレイヤー: セルフアテンションレイヤーとフィードフォワードネットワークレイヤーは、複数回積み重ねられます。この繰り返しの適用により、モデルはデータ内のより複雑な依存関係とパターンを捉えることができます。
6. 出力テキストトークン: 最後に、処理されたデータを使用して、出力テキストトークンが生成されます。このトークンは、入力コンテキストに基づいて、シーケンス内の次の単語またはサブワードに対するモデルの予測です。
ベンチマークテストでは、Llama 3.1はこれらの最先端モデルに対抗できるだけでなく、特定のタスクではそれらを上回り、その優れたパフォーマンスを実証しています。
Llama 3.1モデルは、150以上のベンチマークデータセットで広範な評価を受けており、他の主要な大規模言語モデルと比較されています。新しくリリースされたシリーズで最も有能であると認識されているLlama 3.1 405Bモデルは、OpenAIのGPT-4やClaude 3.5 Sonnetなどの業界の巨人に対してベンチマークされています。これらの比較の結果から、Llama 3.1は競争力を示しており、さまざまなタスクにおいて優れたパフォーマンスと能力を発揮していることが明らかになりました。
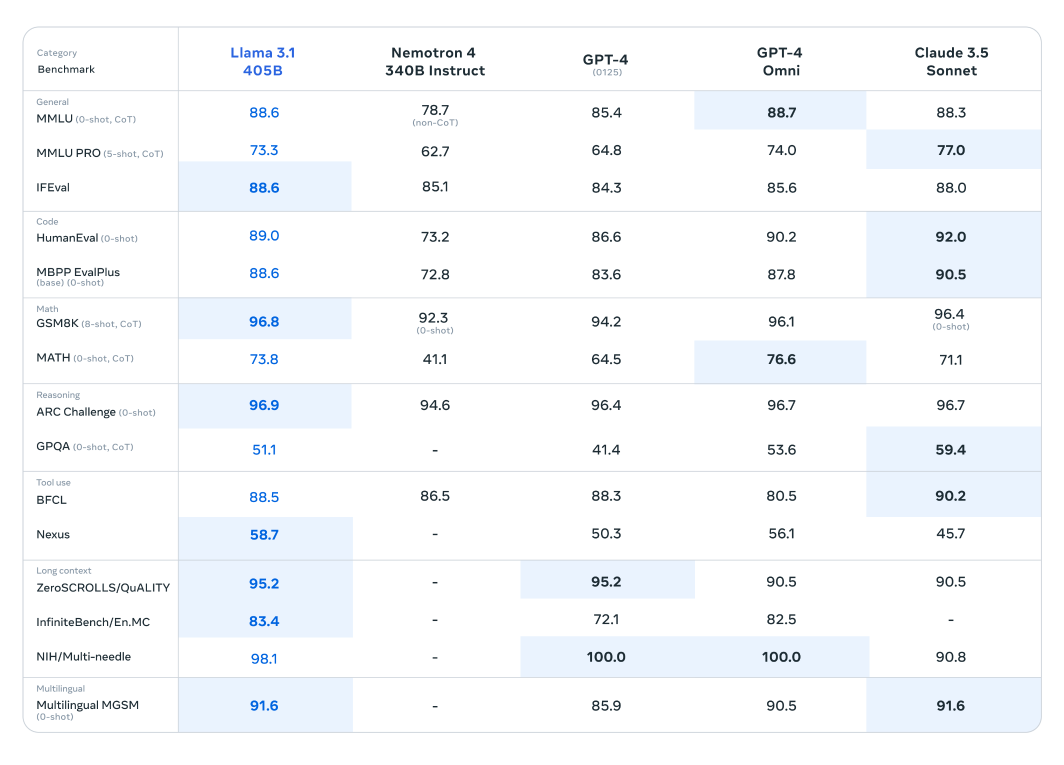
このモデルは、その優れたパラメータ数と高度なアーキテクチャにより、複雑な理解とテキスト生成において卓越した能力を発揮し、特定のベンチマークでは競合モデルを凌駕することがよくあります。これらの評価は、大規模言語モデルの分野で新たな標準を打ち立てるLlama 3.1の可能性を強調しており、研究者や開発者に多様なアプリケーションのための強力なツールを提供します。
より小型で軽量なLlamaモデルも、同様のモデルと比較して優れた性能を発揮します。Llama 3.1 70Bモデルは、Mistral 8x22BやGPT-3.5 Turboなどの大型モデルと比較評価されています。例えば、Llama 3.1 70Bモデルは、ARC Challengeデータセットなどの推論データセットや、HumanEvalデータセットなどのコーディングデータセットにおいて、一貫して優れた性能を示しています。これらの結果は、異なるモデルサイズにおけるLlama 3.1シリーズの多様性と堅牢性を強調しており、幅広いアプリケーションにとって価値のあるツールとなっています。
さらに、Llama 3.1 8Bモデルは、Gemma 2 9BやMistral 7Bなどの同程度のサイズのモデルと比較されています。これらの比較から、Llama 3.1 8Bモデルは、推論のためのGPQAデータセットやコーディングのためのMBPP EvalPlusなど、さまざまなジャンルのベンチマークデータセットにおいて競合モデルを上回る性能を示しており、その少ないパラメータ数にもかかわらず、効率性と能力を発揮しています。

Metaは、新しいモデルがユーザーにとってさまざまな実用的かつ有益な方法で応用できるようにしました。
ユーザーは、特定のユースケースに合わせて最新のLlama 3.1モデルをファイン・チューニングできるようになりました。このプロセスでは、モデルが以前に触れたことのない新しい外部データでモデルをトレーニングし、それによって、対象とするアプリケーションに対する性能と適応性を向上させます。ファイン・チューニングにより、特定のドメインまたはタスクに関連するコンテンツをより良く理解し、生成できるようになるため、モデルに大きな優位性がもたらされます。
Llama 3.1モデルは、Retrieval-Augmented Generation (RAG)システムにシームレスに統合できるようになりました。この統合により、モデルは外部データソースを動的に活用できるようになり、正確で文脈に関連した応答を提供する能力が向上します。Llama 3.1は、大規模なデータセットから情報を取得し、それを生成プロセスに組み込むことで、知識集約型のタスクにおける性能を大幅に向上させ、ユーザーにより正確で情報に基づいたアウトプットを提供します。
4050億のパラメータを持つモデルを利用して、高品質な合成データを生成し、特定のユースケース向けの特殊モデルの性能を向上させることもできます。このアプローチは、Llama 3.1の広範な能力を活用して、ターゲットを絞った関連性の高いデータを生成し、それによって、調整されたAIアプリケーションの精度と効率を向上させます。
Llama 3.1のリリースは、大規模言語モデルの分野における大きな飛躍を意味し、AI技術の進歩に対するMetaのコミットメントを示しています。
Llama 3.1は、その膨大なパラメータ数、多様なデータセットでの広範なトレーニング、そして堅牢で安定したトレーニングプロセスに重点を置くことで、自然言語処理における性能と能力の新たなベンチマークを打ち立てます。テキスト生成、要約、または複雑な会話タスクのいずれにおいても、Llama 3.1は他の主要モデルよりも競争力のある優位性を示しています。このモデルは、今日のAIが達成できることの限界を押し広げるだけでなく、絶え間なく進化する人工知能の状況における将来のイノベーションの舞台を設定します。
Ultralytics、AI技術の限界を押し広げることに専念しています。当社の最先端AIソリューションを探求し、最新のイノベーションをキャッチアップするには、当社の GitHubリポジトリをご覧ください。 Discordの活気あるコミュニティに参加して、私たちが 自動運転車や 製造業などの業界にどのような革命を起こしているかをご覧ください!🚀


