



Google新しいビジョン言語モデルを詳しく見ていきましょう:PaliGemma 2です。これらのモデルは、画像とテキストの両方の理解と分析に役立ちます。

Google新しいビジョン言語モデルを詳しく見ていきましょう:PaliGemma 2です。これらのモデルは、画像とテキストの両方の理解と分析に役立ちます。
2024年12月5日、Google 最先端の視覚言語モデル(VLM)の最新版であるPaliGemma 2を発表した。PaliGemma 2は、キャプションの生成、視覚的な質問への回答、視覚内のオブジェクトの検出など、画像とテキストを組み合わせたタスクを処理するように設計されている。
多言語キャプション作成と物体認識ですでに強力なツールであったオリジナルのPaliGemmaを基盤として、PaliGemma 2ではいくつかの重要な改善が加えられています。これには、モデルサイズの拡大、高解像度画像のサポート、および複雑な視覚タスクにおけるパフォーマンスの向上が含まれます。これらのアップグレードにより、幅広い用途でさらに柔軟かつ効果的に使用できます。
この記事では、PaliGemma 2について、その仕組み、主な機能、そしてその強みを発揮するアプリケーションについて詳しく見ていきます。それでは始めましょう!
PaliGemma 2は、SigLIP vision encoderとGemma 2 language modelという2つの主要なテクノロジーを基盤として構築されています。SigLIPエンコーダーは、画像や動画などの視覚データを処理し、モデルが分析できる特徴に分解します。一方、Gemma 2はテキストを処理し、モデルが多言語を理解し、生成できるようにします。これらが連携してVLM(Vision Language Model)を形成し、視覚情報とテキスト情報をシームレスに解釈し、接続するように設計されています。
PaliGemma 2が大きく前進した理由は、そのスケーラビリティと汎用性です。オリジナルのバージョンとは異なり、PaliGemma 2には、30億(3B)、100億(10B)、280億(28B)のパラメータの3つのサイズがあります。これらのパラメータは、モデルの内部設定のようなもので、モデルがデータを効果的に学習および処理するのに役立ちます。また、さまざまな画像解像度(たとえば、迅速なタスクには224 x 224ピクセル、詳細な分析には896 x 896ピクセル)をサポートしているため、さまざまなアプリケーションに適応できます。
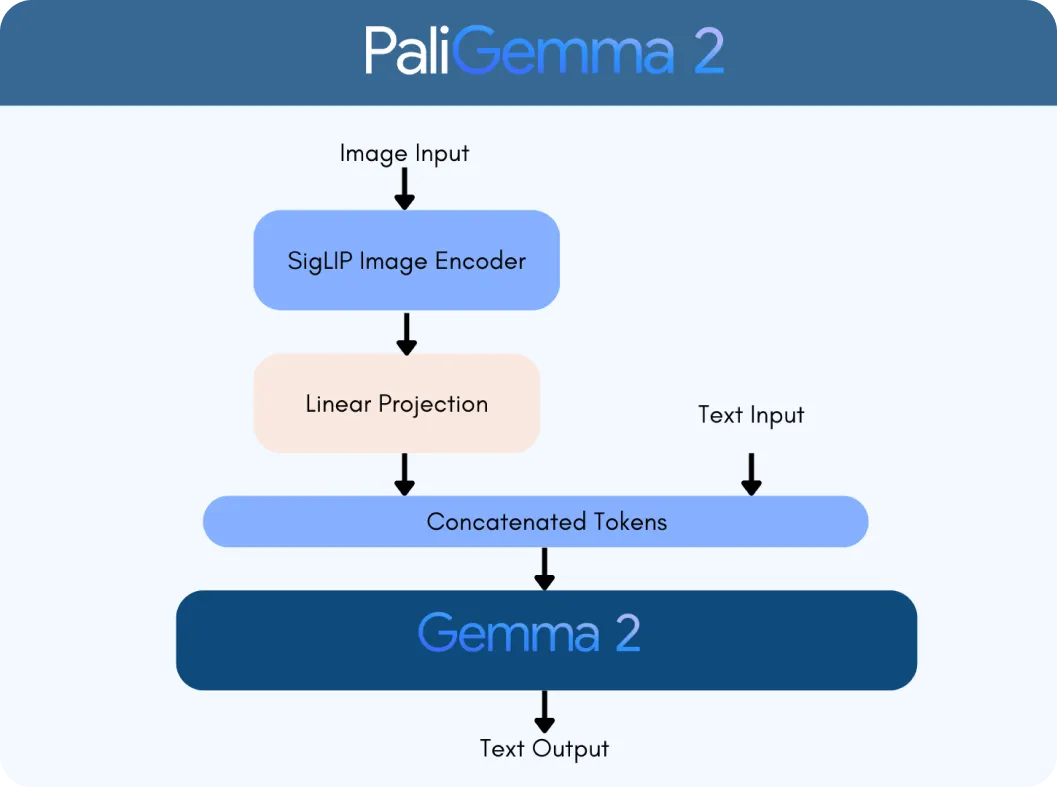
Gemma 2の高度な言語機能とSigLIPの画像処理を統合すると、PaliGemma 2が大幅にインテリジェントになります。次のようなタスクを処理できます。
PaliGemma 2は、画像とテキストを別々に処理するだけでなく、意味のある方法でそれらを統合します。例えば、「猫がテーブルの上に座っている」というシーンの関係性を理解したり、有名なランドマークを認識するなど、コンテキストを追加しながらオブジェクトを識別したりできます。
次に、以下の画像に示すグラフを使用して、PaliGemma 2が視覚データとテキストデータをどのように処理するかをより深く理解するための例を説明します。このグラフをアップロードして、モデルに「このグラフは何を表していますか?」と尋ねるとします。

このプロセスは、PaliGemma 2のSigLIPビジョンエンコーダで画像を解析し、主要な特徴を抽出することから始まります。グラフの場合、軸、データ点、ラベルなどの要素を識別します。このエンコーダーは、大まかなパターンと細かいディテールの両方を捉えるように訓練されています。また、光学式文字認識(OCR)を使用して、画像に埋め込まれたテキストをdetect 処理する。これらの視覚的特徴は、モデルが処理できる数値表現であるトークンに変換される。これらのトークンは、線形投影レイヤーを使用して調整されます。これは、テキストデータとシームレスに結合できるようにする技術です。
同時に、Gemma 2言語モデルは、付属のクエリを処理して、その意味と意図を判断します。クエリからのテキストはトークンに変換され、これらはSigLIPからの視覚トークンと組み合わされて、マルチモーダル表現(視覚データとテキストデータをリンクする統一された形式)が作成されます。
この統合された表現を用いて、PaliGemma 2は自己回帰復号を通じて段階的に応答を生成します。これは、モデルがすでに処理したコンテキストに基づいて、一度に答えの一部を予測する手法です。
その仕組みを理解したところで、PaliGemma 2を信頼できるビジョン言語モデルにする主要な機能を見ていきましょう。
PaliGemmaの最初のバージョンのアーキテクチャを見てみると、PaliGemma 2の機能強化がよくわかります。最も注目すべき変更点の1つは、元のGemma言語モデルがGemma 2に置き換えられたことであり、パフォーマンスと効率の両方が大幅に向上しています。
9Bと27Bのパラメータサイズで利用可能なGemma 2は、クラス最高の精度と速度を実現しつつ、導入コストを削減するように設計されました。これは、強力なGPUから、よりアクセスしやすい構成まで、さまざまなハードウェア設定で推論効率を最適化するために再設計されたアーキテクチャによって実現されています。
その結果、PaliGemma 2は非常に正確なモデルとなっています。PaliGemma 2の10Bバージョンは、元のモデルの34.3と比較して、より低い非包含文(NES)スコア20.3を達成しており、出力のエラーが少ないことを意味します。これらの進歩により、PaliGemma 2は、詳細なキャプション作成から視覚的な質問応答まで、よりスケーラブルで正確になり、より幅広いアプリケーションに適応できるようになります。
PaliGemma 2は、視覚と言語の理解をシームレスに組み合わせることで、業界を再定義する可能性を秘めています。例えば、アクセシビリティに関して言えば、オブジェクト、シーン、空間関係の詳細な説明を生成し、視覚障碍者の方々に重要な支援を提供できます。この機能により、ユーザーは自分の環境をより良く理解し、日常のタスクにおいてより自立できるようになります。

アクセシビリティに加えて、PaliGemma 2は、次のようなさまざまな業界に影響を与えています。
PaliGemma 2を試すには、Hugging Faceインタラクティブデモから始めることができます。このデモでは、画像のキャプション付けや視覚的な質問応答などのタスクでその機能を試すことができます。画像をアップロードし、それについてモデルに質問したり、シーンの説明を要求するだけです。
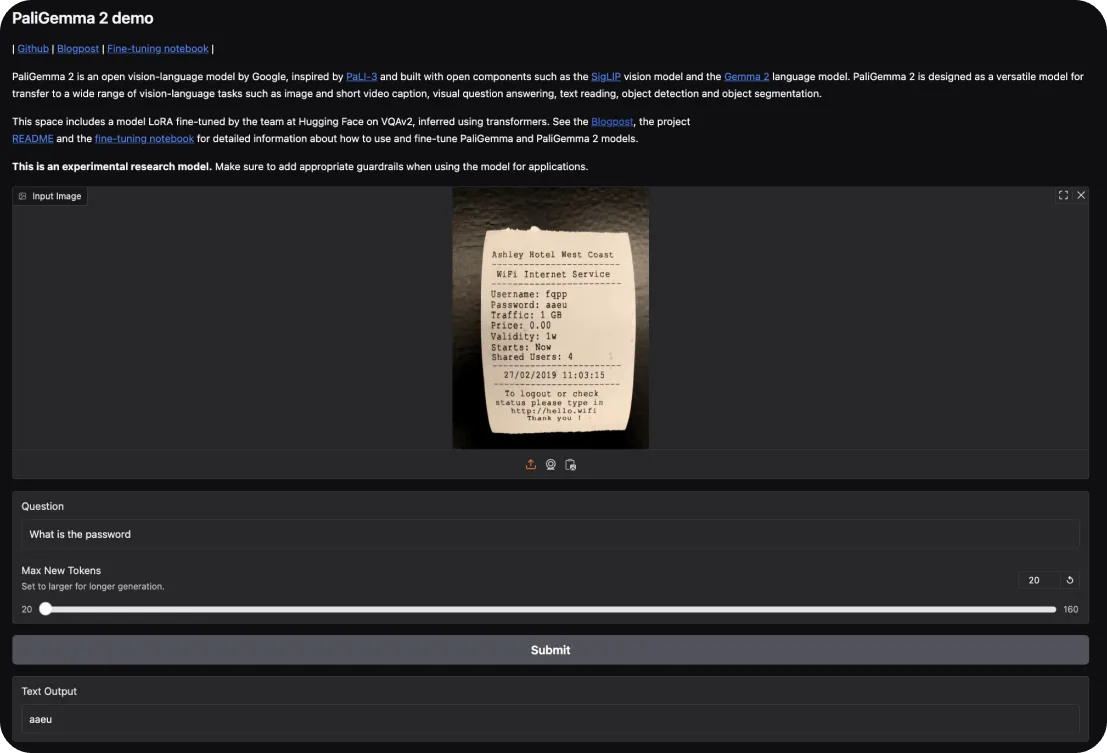
さらに詳しく知りたい場合は、こちらで実際に体験できます。
PaliGemma 2の始め方を理解したところで、これらのモデルを使用する際に留意すべき主な強みと弱みを詳しく見ていきましょう。
PaliGemma 2がビジョン・言語モデルとして際立っている理由を以下に示します。
一方、PaliGemma 2が直面する可能性のある制限事項を以下に示します。
PaliGemma 2は、視覚言語モデリングにおける目覚ましい進歩であり、スケーラビリティ、ファインチューニングの柔軟性、および精度が向上しています。アクセシビリティソリューションやeコマースから、ヘルスケア診断や教育まで、幅広いアプリケーションにとって価値のあるツールとなります。
計算要件や高品質のデータへの依存など、制限はありますが、その強みにより、視覚データとテキストデータを統合する複雑なタスクに取り組むための実用的な選択肢となります。PaliGemma 2は、研究者や開発者がマルチモーダルアプリケーションにおけるAIの可能性を探求し、拡大するための強固な基盤を提供できます。
GitHubリポジトリとコミュニティをチェックして、AIに関する会話に参加しましょう。農業とヘルスケアでAIがどのように進歩しているかをご覧ください!🚀


