



オブジェクト検出の進化を振り返りましょう。YOLO Only Look Once)モデルがここ数年でどのように進化したかに焦点を当てます。

オブジェクト検出の進化を振り返りましょう。YOLO Only Look Once)モデルがここ数年でどのように進化したかに焦点を当てます。
コンピュータビジョンは、人工知能(AI)のサブフィールドであり、人間が現実世界を認識するのと同じように、マシンに画像やビデオを見て理解させることに焦点を当てています。オブジェクトを認識することやアクションを識別することは人間にとってごく自然なことですが、これらのタスクには、マシンに関しては特定の専門的なコンピュータビジョン技術が必要です。たとえば、コンピュータビジョンの重要なタスクの1つは物体検出であり、画像またはビデオ内のオブジェクトを識別して特定することを含みます。
1960年代から、研究者たちはコンピューターが物体をdetect する方法の改良に取り組んできた。テンプレートマッチングのような初期の手法は、あらかじめ定義されたテンプレートを画像上でスライドさせ、一致するものを見つけるというものだった。革新的ではあったが、これらのアプローチは物体の大きさ、向き、照明の変化に苦戦していた。今日では Ultralytics YOLO11のような高度なモデルがあり、オクルード・オブジェクトと呼ばれる、小さくて部分的に隠れたオブジェクトでさえも、驚くほどの精度でdetect ことができる。
コンピュータビジョンが進化し続ける中で、これらの技術がどのように発展してきたかを振り返ることは重要である。この記事では、物体検出の進化を探り、YOLO (You Only Look Once)モデルの変容に光を当てます。始めよう!
物体検出に入る前に、コンピュータ・ビジョンがどのように始まったかを見てみよう。コンピュータビジョンの起源は、科学者たちが脳が視覚情報をどのように処理するかを探求し始めた1950年代後半から1960年代前半にさかのぼる。研究者のデイビッド・ヒューベルとトーステン・ヴィーゼルは、猫を使った実験で、脳がエッジや線のような単純なパターンに反応することを発見した。これが特徴抽出の考え方の基礎となった。視覚システムは、より複雑なパターンに移る前に、エッジのような画像内の基本的な特徴をdetect 認識するという概念である。

ほぼ同時期に、物理的な画像をデジタル形式に変換できる新しい技術が登場し、機械がどのように視覚情報を処理できるかに関心が集まりました。1966年、マサチューセッツ工科大学(MIT)のSummer Vision Projectは、さらに研究を推し進めました。このプロジェクトは完全には成功しませんでしたが、画像内の前景を背景から分離できるシステムの構築を目指しました。Vision AIコミュニティの多くの人々にとって、このプロジェクトはコンピュータビジョンが科学分野として正式に始まったことを示すものとなっています。
1990年代後半から2000年代前半にかけてコンピュータビジョンが進歩するにつれ、物体検出の手法はテンプレートマッチングのような基本的な手法から、より高度なアプローチへと変化していった。よく使われる手法のひとつがハールカスケードで、顔検出などのタスクに広く使われるようになった。スライディングウィンドウで画像をスキャンし、画像の各セクションでエッジやテクスチャなどの特定の特徴をチェックし、これらの特徴を組み合わせて顔などのオブジェクトをdetect する。Haar Cascadeは、以前の方法よりもはるかに高速だった。
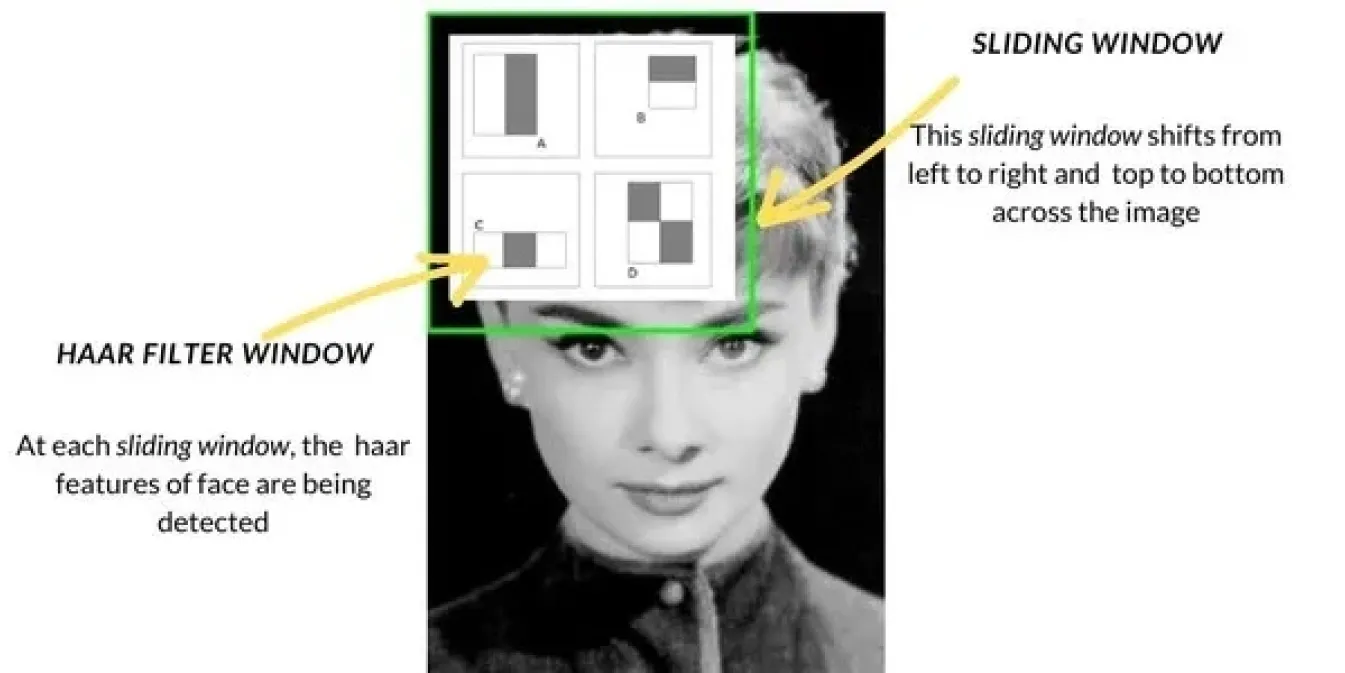
これらに加えて、Histogram of Oriented Gradients (HOG) や Support Vector Machines (SVMs) などの手法も導入されました。HOGは、スライディングウィンドウ技術を使用して、画像の小さなセクションでの光と影の変化を分析し、形状に基づいてオブジェクトを識別するのに役立ちました。次に、SVMはこれらの特徴を分類して、オブジェクトの識別を決定しました。これらの手法は精度を向上させましたが、依然として現実世界の環境では苦戦し、今日の技術と比較して低速でした。
2010年代には、ディープラーニングと畳み込みニューラルネットワーク(CNN)の台頭により、物体検出に大きな変化がもたらされました。CNNにより、コンピューターは大量のデータから重要な特徴を自動的に学習できるようになり、検出がはるかに正確になりました。
R-CNN(領域ベースの畳み込みニューラルネットワーク)のような初期のモデルは、精度が大幅に向上し、以前の方法よりもより正確にオブジェクトを識別するのに役立ちました。
ただし、これらのモデルは画像を複数の段階で処理するため、処理速度が遅く、自動運転車やビデオ監視などのリアルタイムアプリケーションには実用的ではありませんでした。
高速化に重点を置くことで、より効率的なモデルが開発されました。Fast R-CNNやFaster R-CNNのようなモデルは、関心領域の選択方法を改良し、検出に必要なステップ数を削減することで貢献しました。これにより物体検出は高速化されましたが、即時の結果を必要とする多くの現実世界のアプリケーションにとっては、まだ十分な速度ではありませんでした。リアルタイム検出への需要の高まりが、速度と精度の両方を両立できる、より高速で効率的なソリューションの開発を後押ししました。

YOLOは、画像や動画中の複数の物体のリアルタイム検出を可能にすることで、コンピュータ・ビジョンを再定義した物体検出モデルであり、従来の検出方法とはまったく異なる。YOLOアーキテクチャは、検出された各物体を個別に分析する代わりに、物体検出を単一のタスクとして扱い、CNNを使用して物体の位置とクラスの両方を一度に予測する。
このモデルは、画像をグリッドに分割し、各部分がそれぞれの領域内のオブジェクトを検出する役割を担うことによって機能します。各セクションに対して複数の予測を行い、信頼度の低い結果を除外し、正確な結果のみを保持します。

YOLO コンピュータ・ビジョン・アプリケーションに導入されたことで、物体検出は以前のモデルよりもはるかに高速かつ効率的になった。その速度と正確さから、YOLO 製造、ヘルスケア、ロボット工学などの産業におけるリアルタイム・ソリューションとして急速に普及した。
もうひとつ重要な点は、YOLO オープンソースであったため、開発者や研究者が継続的に改良を加え、さらに進化したバージョンを生み出すことができたということだ。
YOLO モデルは、バージョンアップを重ねるごとに着実に進化してきた。性能の向上とともに、これらの改良により、さまざまな技術経験レベルの人々にとって使いやすいモデルとなっている。
例えば Ultralytics YOLOv5が導入されたとき、モデルのデプロイはPyTorchを使うことで、より幅広いユーザーが高度なAIを扱えるようになりました。PyTorchは精度と使いやすさを両立させ、コーディングの専門家でなくても、より多くの人が物体検出を実装できるようにした。
Ultralytics YOLOv8 は、インスタンスのセグメンテーションのようなタスクのサポートを追加し、モデルをより柔軟にすることで、この進歩を継続した。基本的なアプリケーションにも、より複雑なアプリケーションにもYOLO 使いやすくなり、さまざまなシナリオで役立つようになった。
最新モデルで Ultralytics YOLO11では、さらなる最適化が行われました。精度を向上させながらパラメーターの数を減らすことで、リアルタイムのタスクに対してより効率的になりました。経験豊富な開発者でも、AI初心者でも、YOLO11 11は簡単に利用できる物体検出への高度なアプローチを提供します。
Ultralytics年次ハイブリッドイベント、YOLO Vision 2024(YV24)で発表されたYOLO11、物体検出、インスタンス分割、画像分類、姿勢推定など、YOLOv8同じコンピュータビジョンタスクをサポートしています。そのため、ユーザーはワークフローを調整することなく、この新モデルに簡単に切り替えることができる。さらに、YOLO11アップグレードされたアーキテクチャは、予測をより正確にします。実際、YOLO11mはCOCO データセットにおいて、YOLOv8m22%少ないパラメータで、より高い平均精度mAP)を達成しています。
YOLO11 また、スマートフォンやその他のエッジデバイスから、より強力なクラウドシステムまで、さまざまなプラットフォーム上で効率的に動作するように構築されている。この柔軟性により、リアルタイム・アプリケーションのさまざまなハードウェア・セットアップでスムーズなパフォーマンスが保証される。その上、YOLO11 11はより高速で効率的で、計算コストを削減し、推論時間を短縮します。Ultralytics Python パッケージまたはコード不要のUltralytics HUBのいずれを使用していても、YOLO11 既存のワークフローに統合するのは簡単です。
リアルタイム・アプリケーションやエッジAIにおける高度な物体検出の影響は、すでに業界全体で感じられるようになっている。石油・ガス、ヘルスケア、小売などの分野でAIへの依存度が高まる中、高速かつ高精度な物体検出への需要は高まり続けている。YOLO11 、コンピューティング・パワーが限られたデバイスでも高性能な検出を可能にすることで、この需要に応えることを目指している。
エッジAIが成長するにつれて、YOLO11 ような物体検出モデルは、スピードと精度が重要な環境におけるリアルタイムの意思決定にさらに不可欠になると思われる。設計と適応性の継続的な改善により、物体検出の未来は、さまざまなアプリケーションにさらなる革新をもたらすことになりそうだ。
物体検出は、シンプルな手法から今日のような高度なディープラーニング技術へと進化し、長い道のりを歩んできました。YOLO モデルはこの進歩の中核を担い、さまざまな業界でより高速で正確なリアルタイム検出を実現してきました。YOLO11 、この遺産を基に、効率を改善し、計算コストを削減し、精度を向上させることで、さまざまなリアルタイム・アプリケーションにとって信頼できる選択肢となっています。AIとコンピュータ・ビジョンの継続的な進歩により、物体検出の未来は明るく、速度、精度、適応性においてさらなる改善の余地がある。
AIにご興味がありますか?コミュニティと繋がり、学習を続けましょう!当社のGitHubリポジトリをチェックして、製造業やヘルスケアなどの業界で、AIをどのように活用して革新的なソリューションを生み出しているかをご覧ください。🚀
.webp)

.webp)