Bằng cách nhấp vào “Chấp nhận tất cả Cookie”, bạn đồng ý với việc lưu trữ cookie trên thiết bị của mình để tăng cường khả năng điều hướng trang web, phân tích việc sử dụng trang web và hỗ trợ các nỗ lực tiếp thị của chúng tôi. Thêm thông tin
Cài đặt Cookie
Bằng cách nhấp vào “Chấp nhận tất cả Cookie”, bạn đồng ý với việc lưu trữ cookie trên thiết bị của mình để tăng cường khả năng điều hướng trang web, phân tích việc sử dụng trang web và hỗ trợ các nỗ lực tiếp thị của chúng tôi. Thêm thông tin
Tìm hiểu cách AI hiến pháp giúp các mô hình tuân theo các quy tắc đạo đức, đưa ra các quyết định an toàn hơn và hỗ trợ tính công bằng trong các hệ thống ngôn ngữ và thị giác máy tính.
Trí tuệ nhân tạo (AI) đang nhanh chóng trở thành một phần quan trọng trong cuộc sống hàng ngày của chúng ta. Nó đang được tích hợp vào các công cụ được sử dụng trong các lĩnh vực như chăm sóc sức khỏe, tuyển dụng, tài chính và an toàn công cộng. Khi các hệ thống này mở rộng, những lo ngại về đạo đức và độ tin cậy của chúng cũng đang được lên tiếng.
Ví dụ: đôi khi các hệ thống AI được xây dựng mà không xem xét đến tính công bằng hoặc an toàn có thể tạo ra các kết quả bị sai lệch hoặc không đáng tin cậy. Điều này là do nhiều mô hình vẫn chưa có một cách rõ ràng để phản ánh và phù hợp với các giá trị của con người.
Để giải quyết những thách thức này, các nhà nghiên cứu hiện đang khám phá một phương pháp được gọi là AI hiến pháp. Nói một cách đơn giản, nó giới thiệu một bộ nguyên tắc bằng văn bản vào quá trình huấn luyện của mô hình. Các nguyên tắc này giúp mô hình đánh giá hành vi của chính nó, ít phụ thuộc hơn vào phản hồi của con người và đưa ra các phản hồi an toàn hơn và dễ hiểu hơn.
Cho đến nay, phương pháp này chủ yếu được sử dụng đối với các mô hình ngôn ngữ lớn (LLM). Tuy nhiên, cấu trúc tương tự có thể giúp hướng dẫn các hệ thống thị giác máy tính đưa ra các quyết định có đạo đức khi phân tích dữ liệu trực quan.
Trong bài viết này, chúng ta sẽ khám phá cách thức hoạt động của AI tuân thủ hiến pháp, xem xét các ví dụ thực tế và thảo luận về các ứng dụng tiềm năng của nó trong các hệ thống thị giác máy tính.
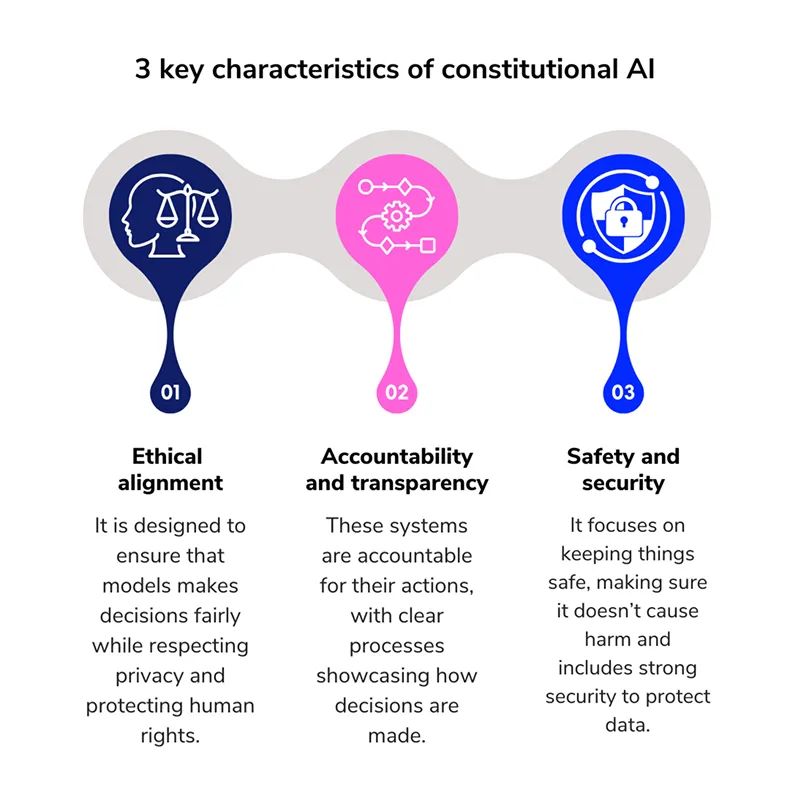
Hình 1. Các đặc điểm của AI tuân thủ hiến pháp. Hình ảnh của tác giả.
AI tuân thủ hiến pháp là gì?
AI tuân thủ hiến pháp là một phương pháp huấn luyện mô hình hướng dẫn cách các mô hình AI hoạt động bằng cách cung cấp một bộ quy tắc đạo đức rõ ràng. Các quy tắc này hoạt động như một quy tắc ứng xử. Thay vì dựa vào mô hình để suy luận điều gì là chấp nhận được, nó tuân theo một bộ nguyên tắc bằng văn bản định hình các phản hồi của nó trong quá trình huấn luyện.
Khái niệm này được giới thiệu bởi Anthropic , một công ty nghiên cứu tập trung vào an toàn AI, đã phát triển chương trình LLM Claude như một phương pháp giúp các hệ thống AI tự giám sát tốt hơn trong quá trình ra quyết định.
Thay vì chỉ dựa vào phản hồi của con người, mô hình học cách phê bình và tinh chỉnh các phản hồi của chính nó dựa trên một bộ nguyên tắc được xác định trước. Cách tiếp cận này tương tự như một hệ thống pháp luật, trong đó một thẩm phán tham khảo hiến pháp trước khi đưa ra phán quyết.
Trong trường hợp này, mô hình vừa là giám khảo vừa là học viên, sử dụng cùng một bộ quy tắc để xem xét và tinh chỉnh hành vi của chính nó. Quá trình này củng cố sự đồng bộ của mô hình AI và hỗ trợ phát triển các hệ thống AI an toàn, có trách nhiệm .
AI tuân thủ hiến pháp hoạt động như thế nào?
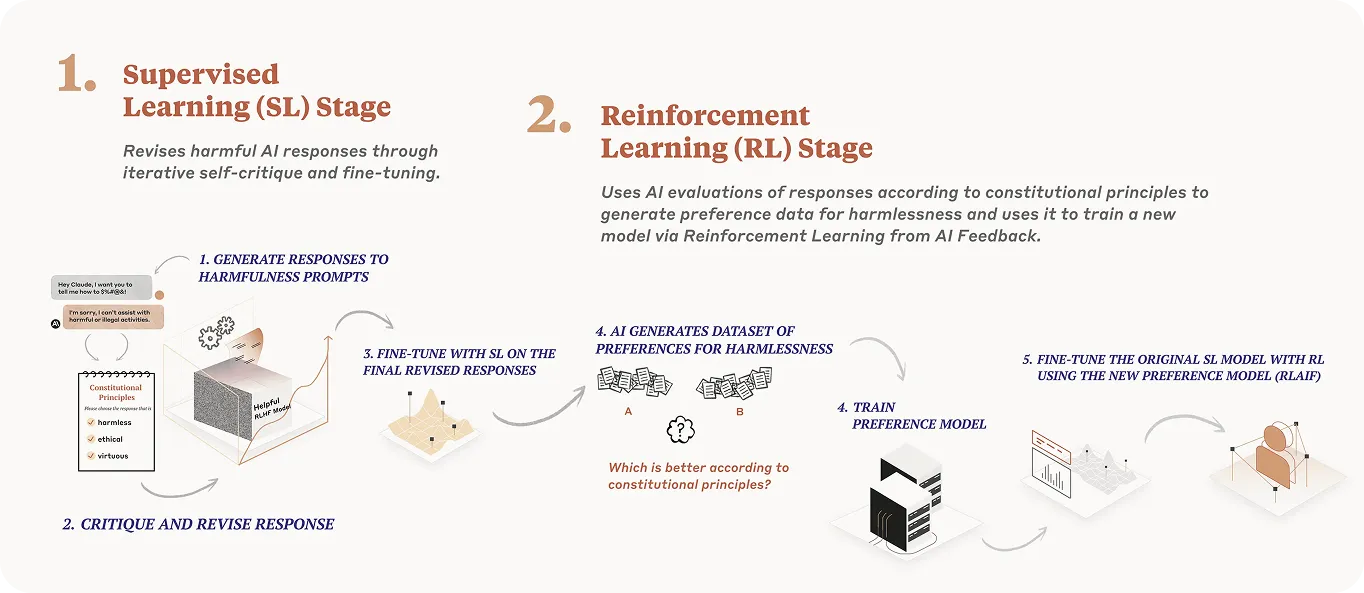
Mục tiêu của AI tuân thủ hiến pháp là dạy một mô hình AI cách đưa ra các quyết định an toàn và công bằng bằng cách tuân theo một bộ quy tắc bằng văn bản rõ ràng. Dưới đây là một phân tích đơn giản về cách thức hoạt động của quy trình này:
Xác định hiến pháp: Một danh sách bằng văn bản về các nguyên tắc đạo đức mà mô hình nên tuân theo được tạo ra. Hiến pháp vạch ra những gì AI nên tránh và những giá trị mà nó nên phản ánh.
Huấn luyện với các ví dụ có giám sát: Mô hình được hiển thị các phản hồi mẫu tuân theo cấu trúc. Những ví dụ này giúp AI hiểu được hành vi được chấp nhận trông như thế nào.
Nhận biết và áp dụng các mẫu: Theo thời gian, mô hình bắt đầu nhận ra các mẫu này. Nó học cách áp dụng các giá trị tương tự khi trả lời các câu hỏi mới hoặc xử lý các tình huống mới.
Phê bình và tinh chỉnh đầu ra: Mô hình xem xét các phản hồi của chính nó và điều chỉnh chúng dựa trên hiến pháp. Giai đoạn tự xem xét này giúp nó cải thiện mà không chỉ dựa vào phản hồi của con người.
Tạo ra các phản hồi phù hợp và an toàn hơn: Mô hình học hỏi từ các quy tắc nhất quán, giúp giảm thiểu sự thiên vị và cải thiện độ tin cậy trong sử dụng thực tế. Cách tiếp cận này làm cho nó phù hợp hơn với các giá trị của con người và dễ quản lý hơn.
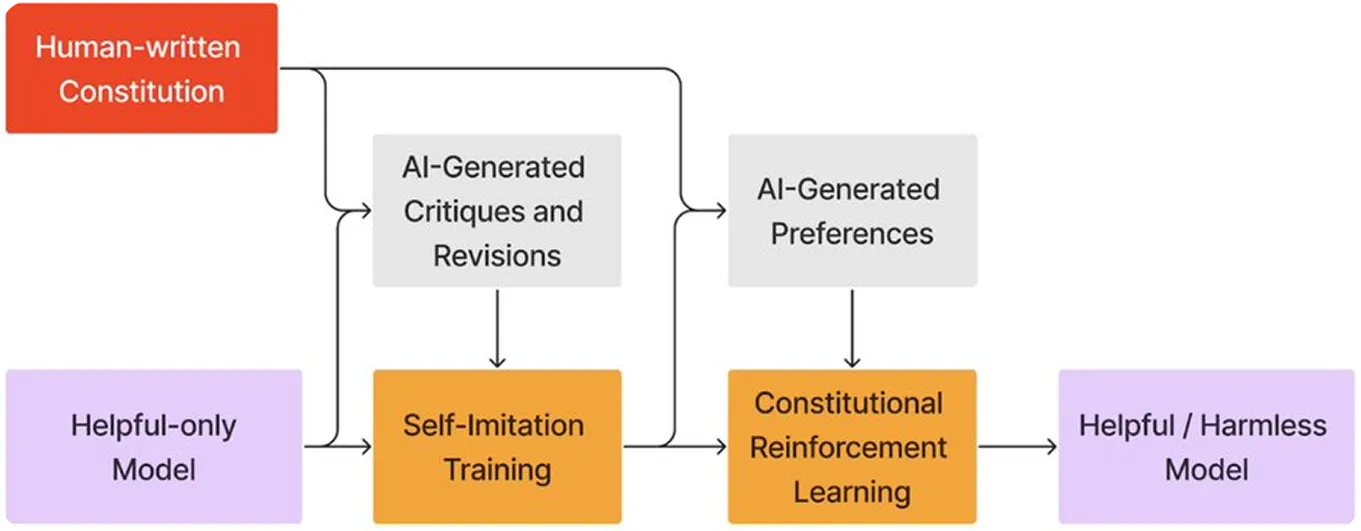
Hình 2. Tổng quan về việc sử dụng AI theo hiến pháp để đào tạo mô hình.
Các nguyên tắc cốt lõi của thiết kế AI có đạo đức
Để một mô hình AI tuân theo các quy tắc đạo đức, trước tiên các quy tắc đó cần được xác định rõ ràng. Khi nói đến AI tuân thủ hiến pháp, các quy tắc này dựa trên một bộ nguyên tắc cốt lõi.
Ví dụ: đây là bốn nguyên tắc tạo nên nền tảng của một hiến pháp AI hiệu quả:
Tính minh bạch: Nên dễ dàng hiểu được cách một mô hình đưa ra câu trả lời. Nếu một phản hồi dựa trên các sự kiện, ước tính hoặc mẫu, nó sẽ minh bạch với người dùng. Điều này xây dựng lòng tin và giúp mọi người đánh giá xem họ có thể dựa vào đầu ra của mô hình hay không.
Tính bình đẳng: Các phản hồi nên nhất quán giữa những người dùng khác nhau. Mô hình không nên thay đổi đầu ra của nó dựa trên tên, lý lịch hoặc vị trí của một người. Tính bình đẳng giúp ngăn ngừa sự thiên vị và thúc đẩy sự đối xử bình đẳng.
Tính trách nhiệm giải trình: Nên có một cách để theo dõi cách một mô hình được huấn luyện và những gì đã ảnh hưởng đến hành vi của nó. Khi có điều gì đó không ổn, các nhóm nên có thể xác định nguyên nhân và cải thiện nó. Điều này hỗ trợ tính minh bạch và trách nhiệm giải trình lâu dài.
An toàn: Mô hình cần tránh tạo ra nội dung có thể gây hại. Nếu một yêu cầu dẫn đến kết quả đầu ra rủi ro hoặc không an toàn, hệ thống nên nhận ra điều đó và dừng lại. Điều này bảo vệ cả người dùng và tính toàn vẹn của hệ thống.
Các ví dụ về AI tuân thủ hiến pháp trong các mô hình ngôn ngữ lớn
Trí tuệ nhân tạo Hiến pháp đã chuyển từ lý thuyết sang thực hành và hiện đang dần được ứng dụng trong các mô hình lớn tương tác với hàng triệu người dùng. Hai ví dụ phổ biến nhất là các chương trình Thạc sĩ Luật (LLM) của OpenAI và Anthropic .
Mặc dù cả hai tổ chức đã áp dụng các phương pháp khác nhau để tạo ra các hệ thống AI đạo đức hơn, nhưng họ có chung một ý tưởng: dạy mô hình tuân theo một bộ nguyên tắc chỉ đạo bằng văn bản. Hãy xem xét kỹ hơn những ví dụ này.
Phương pháp AI theo hiến pháp của OpenAI
OpenAI đã giới thiệu một tài liệu có tên là Model Spec như một phần của quá trình đào tạo cho ChatGPT Mô hình. Tài liệu này hoạt động như một bản hiến pháp. Nó phác thảo những gì mô hình nên hướng đến trong các phản hồi của mình, bao gồm các giá trị như sự hữu ích, trung thực và an toàn. Nó cũng xác định những gì được coi là đầu ra có hại hoặc gây hiểu lầm.
Khung này đã được sử dụng để tinh chỉnh các mô hình của OpenAI bằng cách đánh giá phản hồi dựa trên mức độ phù hợp của chúng với các quy tắc. Theo thời gian, điều này đã giúp định hình ChatGPT để nó tạo ra ít kết quả có hại hơn và phù hợp hơn với những gì người dùng thực sự mong muốn.
Hình 3. Một ví dụ về ChatGPT sử dụng Model Spec của OpenAI để phản hồi.
Anthropic các mô hình AI đạo đức của
Hiến pháp đó Anthropic Mô hình của Claude dựa trên các nguyên tắc đạo đức từ các nguồn như Tuyên ngôn Quốc tế Nhân quyền, các hướng dẫn nền tảng như điều khoản dịch vụ của Apple và nghiên cứu từ các phòng thí nghiệm AI khác. Những nguyên tắc này giúp đảm bảo rằng các phản hồi của Claude là an toàn, công bằng và phù hợp với các giá trị nhân văn quan trọng.
Claude cũng sử dụng Reinforcement Learning from AI Feedback (RLAIF), trong đó nó xem xét và điều chỉnh các phản hồi của chính mình dựa trên các nguyên tắc đạo đức này, thay vì dựa vào phản hồi của con người. Quá trình này cho phép Claude cải thiện theo thời gian, giúp nó có khả năng mở rộng tốt hơn và cung cấp các câu trả lời hữu ích, đạo đức và không gây hại tốt hơn, ngay cả trong những tình huống khó khăn.
Hình 4. Hiểu biết Anthropic cách tiếp cận của 's đối với AI theo hiến pháp.
Áp dụng AI theo hiến pháp vào thị giác máy tính
Vì AI theo hiến pháp đang ảnh hưởng tích cực đến cách các mô hình ngôn ngữ hoạt động, nên nó tự nhiên dẫn đến câu hỏi: Liệu một phương pháp tương tự có thể giúp các hệ thống dựa trên thị giác phản hồi công bằng và an toàn hơn không?
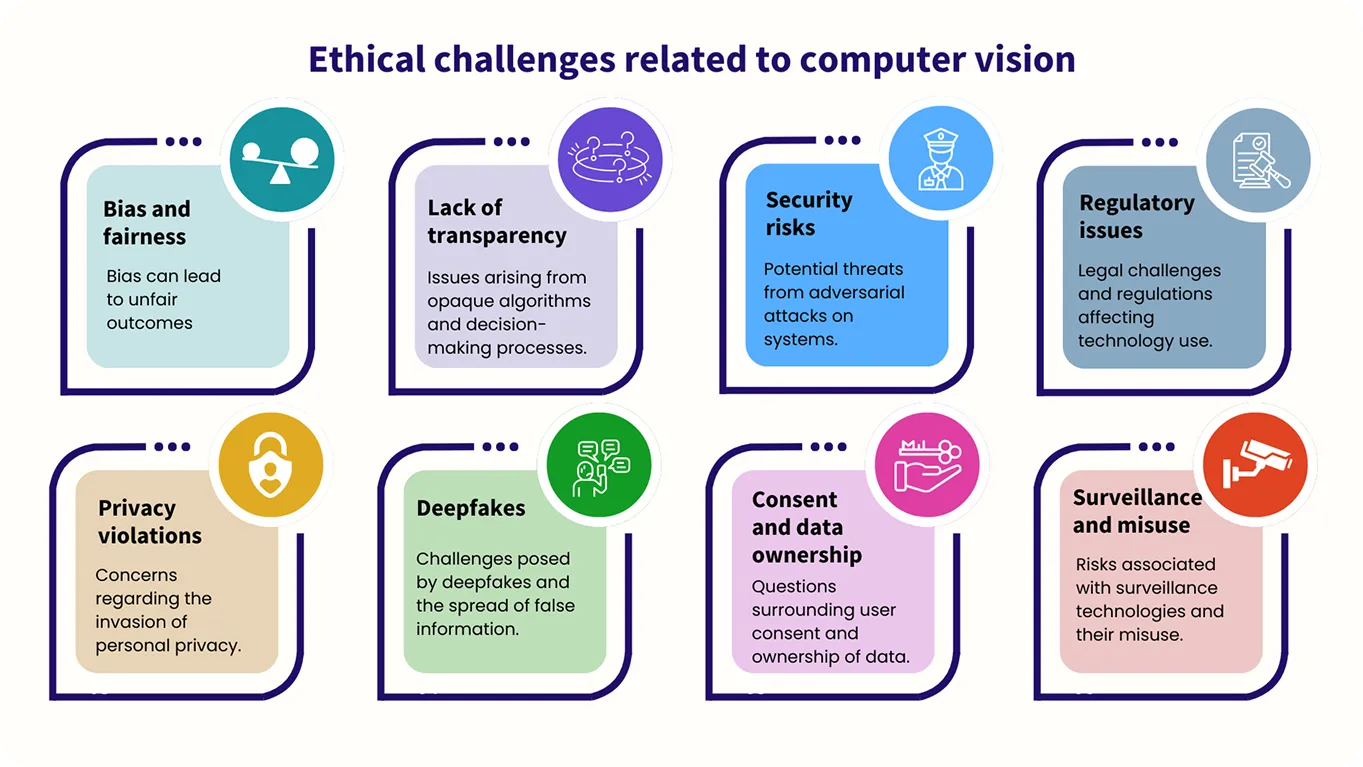
Mặc dù các mô hình thị giác máy tính làm việc với hình ảnh thay vì văn bản, nhưng nhu cầu về hướng dẫn đạo đức cũng quan trọng không kém. Ví dụ: tính công bằng và sự thiên vị là những yếu tố quan trọng cần xem xét, vì các hệ thống này cần được huấn luyện để đối xử bình đẳng với mọi người và tránh các kết quả có hại hoặc không công bằng khi phân tích dữ liệu trực quan.
Hình 5. Các thách thức đạo đức liên quan đến thị giác máy tính. Hình ảnh của tác giả.
Hiện tại, việc sử dụng các phương pháp AI theo hiến pháp trong thị giác máy tính vẫn đang được khám phá và đang ở giai đoạn đầu, với các nghiên cứu đang diễn ra trong lĩnh vực này.
Ví dụ: gần đây, Meta đã giới thiệu CLUE, một khuôn khổ áp dụng lý luận giống như hiến pháp cho các tác vụ an toàn hình ảnh. Nó biến các quy tắc an toàn rộng rãi thành các bước chính xác mà AI đa phương thức (hệ thống AI xử lý và hiểu nhiều loại dữ liệu) có thể tuân theo. Điều này giúp hệ thống lý luận rõ ràng hơn và giảm các kết quả có hại.
Ngoài ra, CLUE giúp việc đánh giá an toàn hình ảnh hiệu quả hơn bằng cách đơn giản hóa các quy tắc phức tạp, cho phép các mô hình AI hành động nhanh chóng và chính xác mà không cần nhiều đầu vào của con người. Bằng cách sử dụng một bộ nguyên tắc chỉ đạo, CLUE giúp các hệ thống kiểm duyệt hình ảnh có khả năng mở rộng tốt hơn đồng thời đảm bảo kết quả chất lượng cao.
Những điều cần nhớ
Khi các hệ thống AI đảm nhận nhiều trách nhiệm hơn, trọng tâm đang chuyển từ chỉ những gì chúng có thể làm sang những gì chúng nên làm. Sự thay đổi này là chìa khóa vì các hệ thống này được sử dụng trong các lĩnh vực tác động trực tiếp đến cuộc sống của mọi người, chẳng hạn như chăm sóc sức khỏe, thực thi pháp luật và giáo dục.
Để đảm bảo các hệ thống AI hành động phù hợp và có đạo đức, chúng cần một nền tảng vững chắc và nhất quán. Nền tảng này nên ưu tiên tính công bằng, an toàn và tin cậy.
Một bản hiến pháp bằng văn bản có thể cung cấp nền tảng đó trong quá trình huấn luyện, hướng dẫn quá trình ra quyết định của hệ thống. Nó cũng có thể cung cấp cho các nhà phát triển một khuôn khổ để xem xét và điều chỉnh hành vi của hệ thống sau khi triển khai, đảm bảo nó tiếp tục phù hợp với các giá trị mà nó được thiết kế để duy trì và giúp dễ dàng thích ứng khi có những thách thức mới phát sinh.
Tham gia cộng đồng đang phát triển của chúng tôi ngay hôm nay! Tìm hiểu sâu hơn về AI bằng cách khám phá kho lưu trữ GitHub của chúng tôi. Bạn đang muốn xây dựng các dự án thị giác máy tính của riêng mình? Khám phá các tùy chọn cấp phép của chúng tôi. Tìm hiểu cách thị giác máy tính trong chăm sóc sức khỏe đang cải thiện hiệu quả và khám phá tác động của AI trong sản xuất bằng cách truy cập các trang giải pháp của chúng tôi!








.webp)