


Khám phá thẻ mô hình Claude 3: Ý nghĩa của nó đối với AI Tầm Nhìn

Khám phá thẻ mô hình Claude 3 và tác động của nó đối với sự phát triển của AI Tầm Nhìn.

Khám phá thẻ mô hình Claude 3 và tác động của nó đối với sự phát triển của AI Tầm Nhìn.
Trong những năm gần đây, AI Tầm Nhìn đã có những bước tiến đáng kể, cách mạng hóa nhiều ngành công nghiệp khác nhau từ chăm sóc sức khỏe đến bán lẻ. Việc hiểu các mô hình cơ bản và tài liệu của chúng là rất quan trọng để tận dụng những tiến bộ này một cách hiệu quả. Một công cụ thiết yếu như vậy trong kho vũ khí của nhà phát triển Trí tuệ Nhân tạo (AI) là thẻ mô hình, cung cấp một cái nhìn tổng quan toàn diện về các đặc điểm và hiệu suất của mô hình AI.
Trong bài viết này, chúng ta sẽ khám phá thẻ mô hình Claude 3 , được phát triển bởi Anthropic và những tác động của nó đối với sự phát triển của Vision AI. Claude 3 là một dòng mô hình đa phương thức lớn mới bao gồm ba biến thể: Claude 3 Opus, mô hình mạnh mẽ nhất; Claude 3 Sonnet, cân bằng giữa hiệu suất và tốc độ; và Claude 3 Haiku, lựa chọn nhanh nhất và tiết kiệm chi phí nhất. Mỗi mô hình đều được trang bị các chức năng thị giác mới, cho phép chúng xử lý và phân tích dữ liệu hình ảnh.
Thẻ mô hình chính xác là gì? Thẻ mô hình là một tài liệu chi tiết cung cấp thông tin chi tiết về quá trình phát triển, đào tạo và đánh giá một mô hình học máy. Nó nhằm mục đích thúc đẩy tính minh bạch, trách nhiệm giải trình và sử dụng AI một cách đạo đức bằng cách trình bày thông tin rõ ràng về chức năng, các trường hợp sử dụng dự kiến và các hạn chế tiềm ẩn của mô hình. Điều này có thể đạt được bằng cách cung cấp dữ liệu chi tiết hơn về mô hình, chẳng hạn như các số liệu đánh giá của nó và so sánh nó với các mô hình trước đó và các đối thủ cạnh tranh khác.
Các số liệu đánh giá rất quan trọng để đánh giá hiệu suất của mô hình. Thẻ mô hình Claude 3 liệt kê các số liệu như độ chính xác, độ chuẩn xác, độ phủ và điểm F1, cung cấp một bức tranh rõ ràng về điểm mạnh và các lĩnh vực cần cải thiện của mô hình. Các số liệu này được so sánh với các tiêu chuẩn ngành, thể hiện hiệu suất cạnh tranh của Claude 3.
Hơn nữa, Claude 3 xây dựng dựa trên những điểm mạnh của các phiên bản tiền nhiệm, kết hợp những tiến bộ trong kiến trúc và kỹ thuật đào tạo. Thẻ mô hình so sánh Claude 3 với các phiên bản trước đó, làm nổi bật những cải tiến về độ chính xác, hiệu quả và khả năng áp dụng cho các trường hợp sử dụng mới.
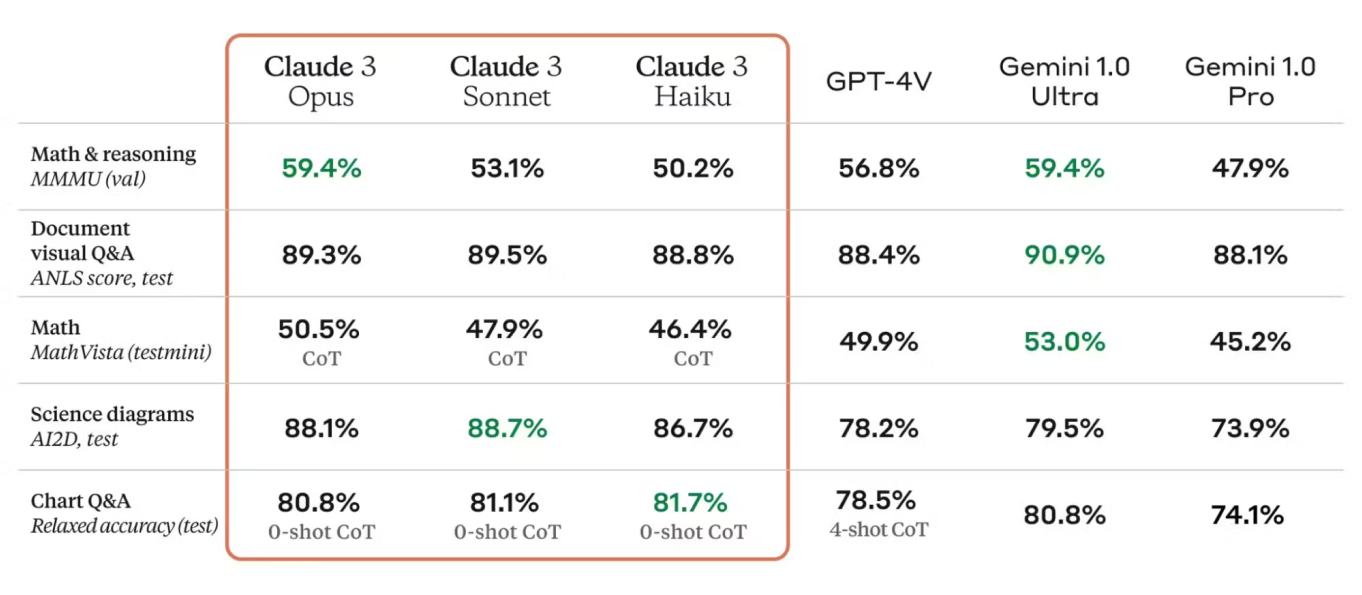
Kiến trúc và quy trình huấn luyện của Claude 3 mang lại hiệu suất đáng tin cậy trong nhiều tác vụ Xử lý Ngôn ngữ Tự nhiên (NLP) và thị giác. Nó liên tục đạt được kết quả tốt trong các bài kiểm tra chuẩn, thể hiện khả năng thực hiện các phân tích ngôn ngữ phức tạp một cách hiệu quả.
Việc huấn luyện Claude 3 trên nhiều bộ dữ liệu đa dạng và sử dụng các kỹ thuật tăng cường dữ liệu đảm bảo tính mạnh mẽ và khả năng khái quát hóa của nó trong các tình huống khác nhau. Điều này làm cho mô hình trở nên linh hoạt và hiệu quả trong một loạt các ứng dụng.
Mặc dù kết quả của nó rất đáng chú ý, nhưng Claude 3 về cơ bản là một Mô hình Ngôn ngữ Lớn (LLM). Mặc dù các LLM như Claude 3 có thể thực hiện nhiều tác vụ thị giác máy tính khác nhau, chúng không được thiết kế riêng cho các tác vụ như phát hiện đối tượng , tạo hộp ranh giới và phân đoạn ảnh . Do đó, độ chính xác của chúng trong các lĩnh vực này có thể không bằng các mô hình được xây dựng riêng cho thị giác máy tính, chẳng hạn như Ultralytics YOLOv8 . Tuy nhiên, LLM lại vượt trội trong các lĩnh vực khác, đặc biệt là Xử lý Ngôn ngữ Tự nhiên (NLP), nơi Claude 3 thể hiện sức mạnh đáng kể bằng cách kết hợp các tác vụ thị giác đơn giản với khả năng suy luận của con người.

Khả năng NLP đề cập đến khả năng của một mô hình AI trong việc hiểu và phản hồi ngôn ngữ của con người. Khả năng này được tận dụng cao trong các ứng dụng của Claude 3 trong lĩnh vực thị giác, cho phép nó cung cấp các mô tả phong phú về mặt ngữ cảnh, diễn giải dữ liệu thị giác phức tạp và nâng cao hiệu suất tổng thể trong các tác vụ AI Thị giác.
Một trong những khả năng ấn tượng của Claude 3, đặc biệt khi được tận dụng cho các tác vụ AI Thị giác, là khả năng xử lý và chuyển đổi hình ảnh chất lượng thấp với chữ viết tay khó đọc thành văn bản. Tính năng này thể hiện sức mạnh xử lý tiên tiến và khả năng suy luận đa phương thức của mô hình. Trong phần này, chúng ta sẽ khám phá cách Claude 3 hoàn thành nhiệm vụ này, làm nổi bật các cơ chế cơ bản và ý nghĩa đối với sự phát triển của AI Thị giác.
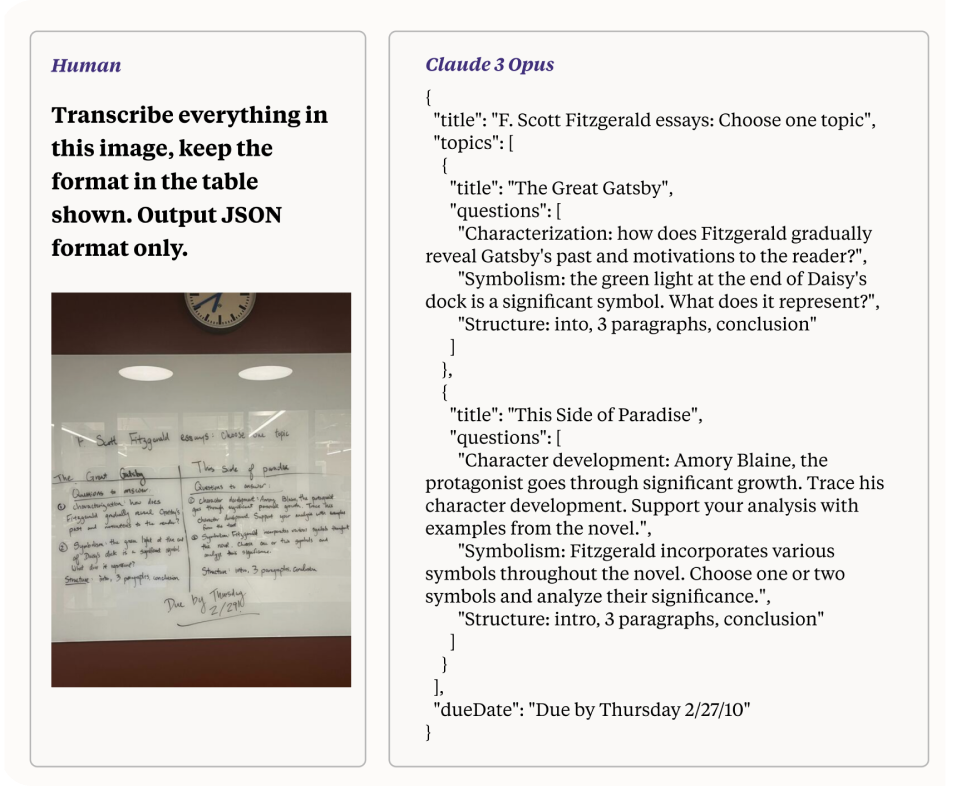
Chuyển đổi một bức ảnh chất lượng thấp với chữ viết tay khó đọc thành văn bản là một nhiệm vụ phức tạp bao gồm một số thách thức:
Như đã đề cập trước đó, các mô hình Claude 3 giải quyết những thách thức này thông qua sự kết hợp của các kỹ thuật tiên tiến trong thị giác máy tính và xử lý ngôn ngữ tự nhiên (NLP).
Kiến trúc của Claude 3 cho phép nó thực hiện các tác vụ suy luận phức tạp bằng cách sử dụng đầu vào trực quan. Ví dụ: như trong Hình 1, mô hình có thể diễn giải các biểu đồ và đồ thị, chẳng hạn như xác định các quốc gia G7 trong biểu đồ về mức sử dụng internet, trích xuất dữ liệu liên quan và thực hiện các phép tính để phân tích xu hướng. Khả năng suy luận đa bước này, như tính toán sự khác biệt thống kê về mức sử dụng internet giữa các nhóm tuổi, nâng cao độ chính xác và tính hữu ích của mô hình trong các ứng dụng thực tế.

Claude 3 vượt trội trong việc chuyển đổi hình ảnh thành các mô tả chi tiết, thể hiện khả năng mạnh mẽ của nó trong cả thị giác máy tính và xử lý ngôn ngữ tự nhiên. Khi được cung cấp một hình ảnh, Claude 3 trước tiên sử dụng các mạng nơ-ron tích chập (CNN) để trích xuất các đặc trưng chính và xác định các đối tượng, mẫu và yếu tố ngữ cảnh trong dữ liệu trực quan.
Sau đó, các lớp transformer phân tích các đặc trưng này, tận dụng các cơ chế chú ý để hiểu các mối quan hệ và ngữ cảnh giữa các yếu tố khác nhau trong hình ảnh. Cách tiếp cận đa phương thức này cho phép Claude 3 tạo ra các mô tả chính xác, phong phú về mặt ngữ cảnh bằng cách không chỉ xác định các đối tượng mà còn hiểu được sự tương tác và ý nghĩa của chúng trong cảnh.

Các mô hình ngôn ngữ lớn (LLM) như Claude 3 vượt trội về xử lý ngôn ngữ tự nhiên, không phải về thị giác máy tính. Mặc dù chúng có thể mô tả hình ảnh, các tác vụ như phát hiện đối tượng và phân đoạn hình ảnh được xử lý tốt hơn bởi các mô hình hướng thị giác như YOLOv8 . Các mô hình chuyên biệt này được tối ưu hóa cho các tác vụ trực quan và mang lại hiệu suất phân tích hình ảnh tốt hơn. Hơn nữa, mô hình này không thể thực hiện các tác vụ như tạo khung giới hạn.
Việc kết hợp Claude 3 với các hệ thống thị giác máy tính có thể phức tạp và đòi hỏi các bước xử lý bổ sung để thu hẹp khoảng cách giữa dữ liệu văn bản và dữ liệu hình ảnh.
Claude 3 chủ yếu được huấn luyện trên một lượng lớn dữ liệu văn bản, điều này có nghĩa là nó thiếu các bộ dữ liệu hình ảnh mở rộng cần thiết để đạt được hiệu suất cao trong các tác vụ thị giác máy tính. Do đó, mặc dù Claude 3 vượt trội trong việc hiểu và tạo văn bản, nhưng nó không có khả năng xử lý hoặc phân tích hình ảnh với cùng mức độ thành thạo như các mô hình được thiết kế đặc biệt cho dữ liệu trực quan. Hạn chế này làm cho nó kém hiệu quả hơn đối với các ứng dụng yêu cầu diễn giải hoặc tạo nội dung trực quan.
Tương tự như các mô hình ngôn ngữ lớn khác, Claude 3 được thiết lập để cải tiến liên tục. Các cải tiến trong tương lai có thể sẽ tập trung vào các tác vụ thị giác tốt hơn như phát hiện hình ảnh và nhận dạng đối tượng, cũng như những tiến bộ trong các tác vụ xử lý ngôn ngữ tự nhiên. Điều này sẽ cho phép mô tả chính xác và chi tiết hơn về các đối tượng và cảnh vật trong số các tác vụ tương tự khác.
Cuối cùng, nghiên cứu đang diễn ra về Claude 3 sẽ ưu tiên tăng cường khả năng diễn giải, giảm thiểu sai lệch và cải thiện khả năng khái quát hóa trên các tập dữ liệu đa dạng. Những nỗ lực này sẽ đảm bảo hiệu suất mạnh mẽ của mô hình trong các ứng dụng khác nhau và thúc đẩy sự tin cậy và độ tin cậy trong các kết quả đầu ra của nó.
Model card của Claude 3 là một nguồn tài nguyên giá trị cho các nhà phát triển và các bên liên quan trong AI Thị giác, cung cấp thông tin chi tiết về kiến trúc, hiệu suất và các cân nhắc về mặt đạo đức của mô hình. Bằng cách thúc đẩy tính minh bạch và trách nhiệm giải trình, nó giúp đảm bảo việc sử dụng các công nghệ AI một cách có trách nhiệm và hiệu quả. Khi AI Thị giác tiếp tục phát triển, vai trò của các model card như của Claude 3 sẽ rất quan trọng trong việc định hướng sự phát triển và thúc đẩy niềm tin vào các hệ thống AI.
Tại Ultralytics Chúng tôi đam mê phát triển công nghệ AI. Để khám phá các giải pháp AI và cập nhật những cải tiến mới nhất, hãy truy cập kho lưu trữ GitHub của chúng tôi. Tham gia cộng đồng của chúng tôi trên Discord và khám phá cách chúng tôi đang chuyển đổi các ngành công nghiệp như Xe tự lái và sản xuất ! 🚀


