



Tìm hiểu cách Mask R-CNN có thể được sử dụng để chính xác segment các đối tượng trong hình ảnh và video cho nhiều ứng dụng khác nhau trong nhiều lĩnh vực khác nhau.

Tìm hiểu cách Mask R-CNN có thể được sử dụng để chính xác segment các đối tượng trong hình ảnh và video cho nhiều ứng dụng khác nhau trong nhiều lĩnh vực khác nhau.
Những đổi mới như robot trong nhà kho, xe tự lái di chuyển an toàn trên những con phố đông đúc, máy bay không người lái kiểm tra mùa màng và hệ thống AI kiểm tra sản phẩm trong nhà máy đang trở nên phổ biến hơn khi việc ứng dụng AI ngày càng tăng. Một công nghệ quan trọng thúc đẩy những đổi mới này là thị giác máy tính, một nhánh của AI cho phép máy móc hiểu và diễn giải dữ liệu trực quan.
Ví dụ: phát hiện đối tượng là một tác vụ thị giác máy tính giúp xác định và định vị các đối tượng trong hình ảnh bằng cách sử dụng bounding box. Mặc dù bounding box cung cấp thông tin hữu ích, nhưng chúng chỉ cung cấp ước tính sơ bộ về vị trí của một đối tượng và không thể nắm bắt hình dạng hoặc ranh giới chính xác của nó. Điều này làm cho chúng kém hiệu quả hơn trong các ứng dụng đòi hỏi nhận dạng chính xác.
Để giải quyết vấn đề này, các nhà nghiên cứu đã phát triển các mô hình phân đoạn nắm bắt chính xác đường viền của các đối tượng, cung cấp chi tiết ở cấp độ pixel để phát hiện và phân tích chính xác hơn.
Mask R-CNN là một trong những mô hình này. Được giới thiệu vào năm 2017 bởi Facebook AI Research (FAIR), nó được xây dựng dựa trên các mô hình trước đó như R-CNN , Fast R-CNN và Faster R-CNN. Là một cột mốc quan trọng trong lịch sử thị giác máy tính, Mask R-CNN đã mở đường cho các mô hình tiên tiến hơn, chẳng hạn như Ultralytics YOLO11 .
Trong bài viết này, chúng ta sẽ khám phá Mask R-CNN là gì, cách thức hoạt động, ứng dụng của nó và những cải tiến nào đã có sau đó, dẫn đến YOLO11 .
Mask R-CNN, viết tắt của Mask Region-based Convolutional Neural Network, là một mô hình deep learning được thiết kế cho các tác vụ thị giác máy tính như object detection (phát hiện đối tượng) và instance segmentation (phân vùng thể hiện).
Instance segmentation vượt xa object detection truyền thống bằng cách không chỉ xác định các đối tượng trong ảnh mà còn phác thảo chính xác từng đối tượng. Nó gán một nhãn duy nhất cho mọi đối tượng được phát hiện và nắm bắt hình dạng chính xác của nó ở cấp độ pixel. Cách tiếp cận chi tiết này giúp có thể phân biệt rõ ràng giữa các đối tượng chồng chéo và xử lý chính xác các hình dạng phức tạp.
Mask R-CNN được xây dựng dựa trên Faster R-CNN, mô hình này phát hiện và gắn nhãn các đối tượng nhưng không xác định hình dạng chính xác của chúng. Mask R-CNN cải thiện điều này bằng cách xác định các pixel chính xác tạo nên mỗi đối tượng, cho phép phân tích hình ảnh chi tiết và chính xác hơn nhiều.

Mask R-CNN thực hiện phương pháp tiếp cận từng bước để detect Và segment đối tượng một cách chính xác. Nó bắt đầu bằng cách trích xuất các đặc điểm chính bằng mạng nơ-ron sâu (một mô hình nhiều lớp học hỏi từ dữ liệu), sau đó xác định các khu vực đối tượng tiềm năng bằng mạng đề xuất vùng (một thành phần gợi ý các vùng đối tượng có khả năng xảy ra) và cuối cùng tinh chỉnh các khu vực này bằng cách tạo mặt nạ phân đoạn chi tiết (phác thảo chính xác các đối tượng) để nắm bắt hình dạng chính xác của từng đối tượng.
Tiếp theo, chúng ta sẽ xem xét từng bước để hiểu rõ hơn về cách Mask R-CNN hoạt động.
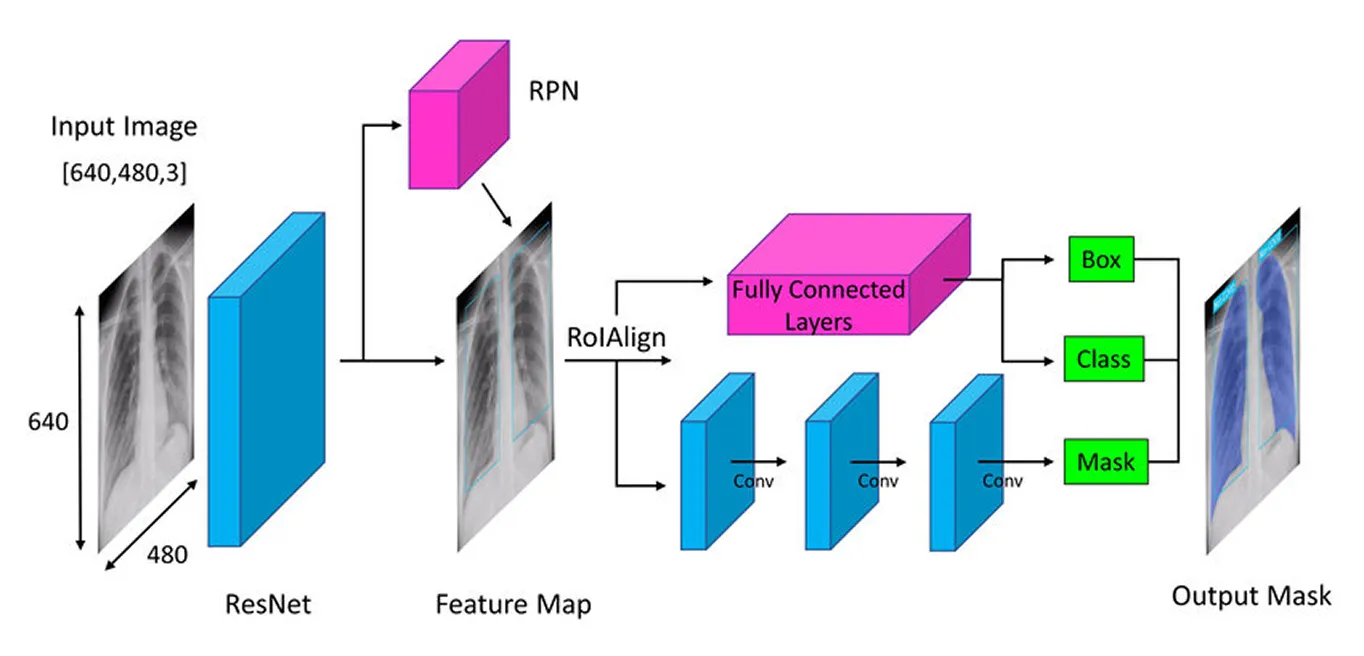
Bước đầu tiên trong kiến trúc của Mask R-CNN là chia hình ảnh thành các phần chính để mô hình có thể hiểu những gì trong đó. Hãy nghĩ về nó giống như khi bạn nhìn vào một bức ảnh và tự nhiên nhận thấy các chi tiết như hình dạng, màu sắc và cạnh. Mô hình thực hiện một điều tương tự bằng cách sử dụng một mạng nơ-ron sâu gọi là "backbone" (thường là ResNet-50 hoặc ResNet-101), hoạt động như đôi mắt của nó để quét hình ảnh và nhận ra các chi tiết chính.
Vì các đối tượng trong ảnh có thể rất nhỏ hoặc rất lớn, Mask R-CNN sử dụng Mạng lưới Kim tự tháp Đặc trưng (Feature Pyramid Network). Điều này giống như việc có các loại kính lúp khác nhau, cho phép mô hình nhìn thấy cả chi tiết nhỏ và bức tranh lớn hơn, đảm bảo rằng các đối tượng ở mọi kích thước đều được nhận diện.
Sau khi các đặc trưng quan trọng này được trích xuất, mô hình sẽ chuyển sang xác định vị trí các đối tượng tiềm năng trong ảnh, tạo tiền đề cho các phân tích tiếp theo.
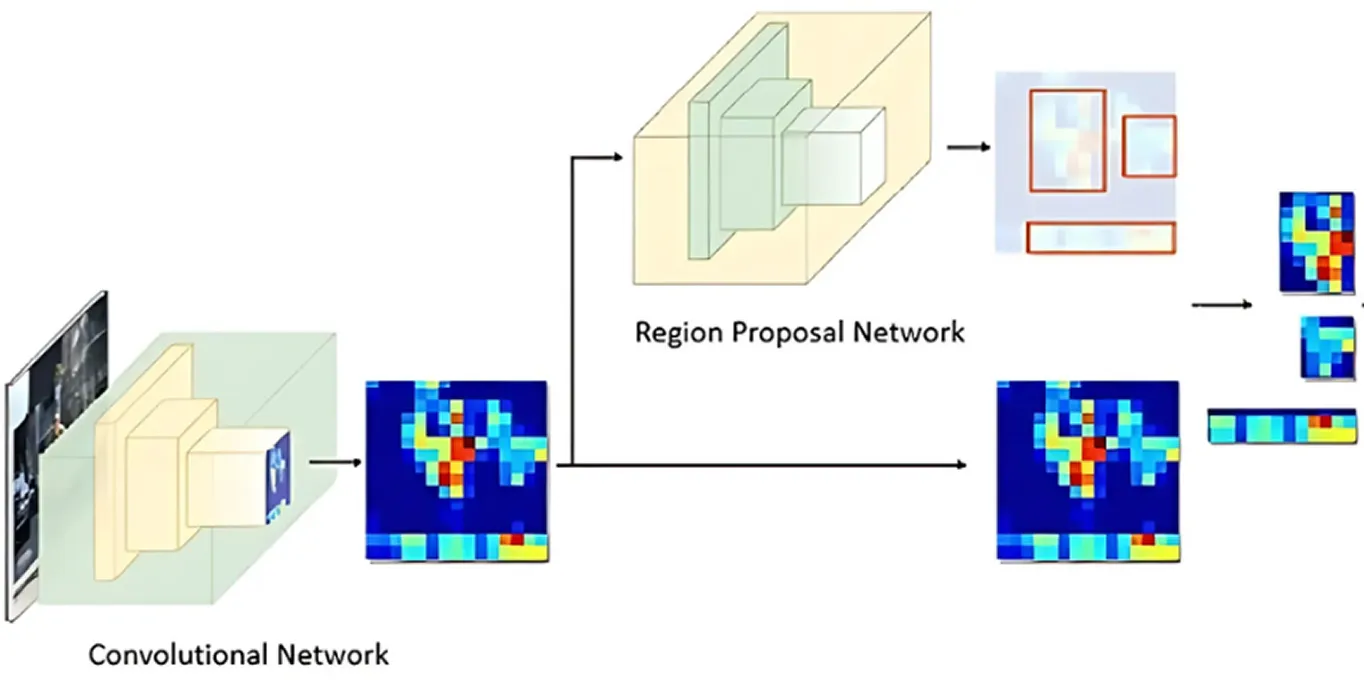
Sau khi hình ảnh được xử lý để trích xuất các đặc trưng chính, Mạng Đề xuất Vùng (Region Proposal Network) sẽ tiếp quản. Phần này của mô hình xem xét hình ảnh và đề xuất các khu vực có khả năng chứa các đối tượng.
Mạng thực hiện việc này bằng cách tạo ra nhiều vị trí đối tượng có thể có, được gọi là neo (anchors). Sau đó, mạng đánh giá các neo này và chọn ra những neo hứa hẹn nhất để phân tích thêm. Bằng cách này, mô hình chỉ tập trung vào các khu vực có khả năng thú vị nhất, thay vì kiểm tra mọi điểm duy nhất trong hình ảnh.
Khi các khu vực quan trọng đã được xác định, bước tiếp theo là tinh chỉnh các chi tiết được trích xuất từ các khu vực này. Các mô hình trước đây sử dụng một phương pháp gọi là ROI Pooling (Region of Interest Pooling) để lấy các đặc trưng từ mỗi khu vực, nhưng kỹ thuật này đôi khi dẫn đến sự sai lệch nhỏ khi thay đổi kích thước khu vực, làm cho nó kém hiệu quả hơn - đặc biệt đối với các đối tượng nhỏ hơn hoặc chồng chéo.
Mask R-CNN cải thiện điều này bằng cách sử dụng một kỹ thuật được gọi là ROI Align (Region of Interest Align). Thay vì làm tròn tọa độ như ROI Pooling, ROI Align sử dụng phép nội suy song tuyến tính để ước tính giá trị pixel chính xác hơn. Nội suy song tuyến tính là một phương pháp tính toán giá trị pixel mới bằng cách tính trung bình các giá trị của bốn điểm ảnh lân cận gần nhất, tạo ra các chuyển đổi mượt mà hơn. Điều này giúp các đặc trưng được căn chỉnh đúng với hình ảnh gốc, dẫn đến việc phát hiện và phân đoạn đối tượng chính xác hơn.
Ví dụ: trong một trận đấu bóng đá, hai cầu thủ đứng gần nhau có thể bị nhầm lẫn với nhau vì các hộp giới hạn của họ chồng lên nhau. ROI Align giúp phân tách chúng bằng cách giữ cho hình dạng của chúng khác biệt.
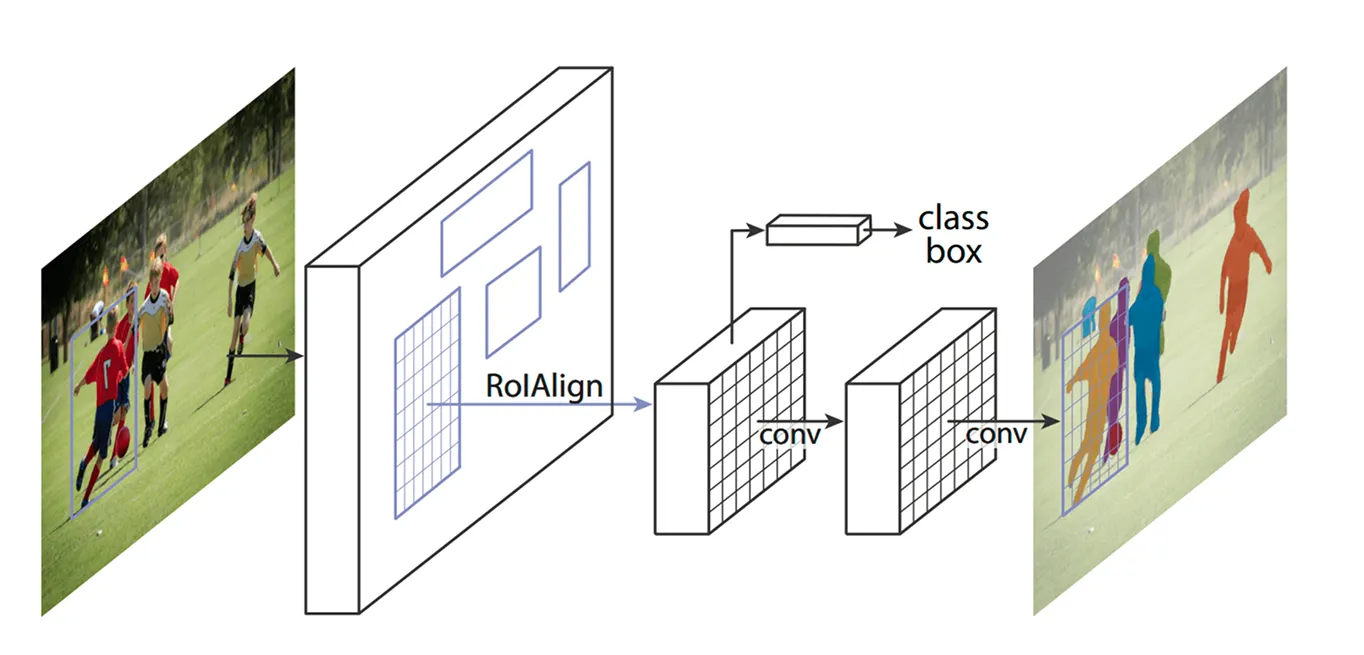
Sau khi ROI Align xử lý hình ảnh, bước tiếp theo là classify các đối tượng và tinh chỉnh vị trí của chúng. Mô hình sẽ xem xét từng vùng được trích xuất và quyết định xem vùng đó chứa đối tượng nào. Mô hình sẽ gán điểm xác suất cho các danh mục khác nhau và chọn ra kết quả phù hợp nhất.
Đồng thời, nó điều chỉnh các hộp giới hạn để phù hợp hơn với các đối tượng. Các hộp ban đầu có thể không được đặt ở vị trí lý tưởng, vì vậy điều này giúp cải thiện độ chính xác bằng cách đảm bảo rằng mỗi hộp bao quanh chặt chẽ đối tượng được phát hiện.
Cuối cùng, Mask R-CNN thực hiện thêm một bước: tạo ra mặt nạ phân đoạn chi tiết cho từng đối tượng song song.
Khi mô hình này ra đời, nó đã nhận được sự hưởng ứng nhiệt liệt từ cộng đồng AI và nhanh chóng được sử dụng trong nhiều ứng dụng khác nhau. Khả năng của nó detect Và segment các đối tượng theo thời gian thực đã tạo nên bước đột phá trong nhiều ngành công nghiệp khác nhau.
Ví dụ, việc theo dõi các loài động vật có nguy cơ tuyệt chủng trong tự nhiên là một nhiệm vụ đầy thách thức. Nhiều loài di chuyển qua các khu rừng rậm rạp, khiến các nhà bảo tồn khó có thể theo dõi. track Các phương pháp truyền thống sử dụng bẫy ảnh, máy bay không người lái và ảnh vệ tinh, nhưng việc phân loại thủ công tất cả dữ liệu này rất tốn thời gian. Việc nhận dạng sai và bỏ sót các loài có thể làm chậm nỗ lực bảo tồn.
Bằng cách nhận dạng các đặc điểm độc đáo như sọc hổ, đốm hươu cao cổ hoặc hình dạng tai voi, Mask R-CNN có thể detect Và segment Động vật trong hình ảnh và video với độ chính xác cao hơn. Ngay cả khi động vật bị cây che khuất một phần hoặc đứng gần nhau, mô hình vẫn có thể tách chúng ra và nhận dạng từng con riêng lẻ, giúp việc theo dõi động vật hoang dã nhanh hơn và đáng tin cậy hơn.

Mặc dù có ý nghĩa lịch sử trong object detection và segmentation, Mask R-CNN cũng đi kèm với một số hạn chế chính. Dưới đây là một số thách thức liên quan đến Mask R-CNN:
Mask R-CNN rất phù hợp cho các tác vụ phân đoạn, nhưng nhiều ngành công nghiệp đang tìm cách áp dụng thị giác máy tính trong khi vẫn ưu tiên tốc độ và hiệu suất thời gian thực. Yêu cầu này đã thúc đẩy các nhà nghiên cứu phát triển các mô hình một giai đoạn. detect các vật thể trong một lần, cải thiện đáng kể hiệu quả.
Không giống như quy trình nhiều bước của Mask R-CNN, các mô hình thị giác máy tính một giai đoạn như YOLO (Bạn chỉ nhìn một lần) tập trung vào các tác vụ thị giác máy tính thời gian thực. Thay vì xử lý phát hiện và phân đoạn riêng biệt, YOLO Các mô hình có thể phân tích hình ảnh chỉ trong một lần. Điều này làm cho nó trở nên lý tưởng cho các ứng dụng như xe tự hành, chăm sóc sức khỏe, sản xuất và robot, nơi việc ra quyết định nhanh chóng là rất quan trọng.
Đặc biệt, YOLO11 đưa điều này tiến thêm một bước nữa bằng cách vừa nhanh vừa chính xác. Nó sử dụng ít hơn 22% tham số so với YOLOv8m nhưng vẫn đạt được độ chính xác trung bình cao hơn ( mAP ) trên COCO bộ dữ liệu, nghĩa là nó phát hiện đối tượng chính xác hơn. Tốc độ xử lý được cải thiện khiến nó trở thành lựa chọn tốt cho các ứng dụng thời gian thực, nơi mà từng mili giây đều quan trọng.
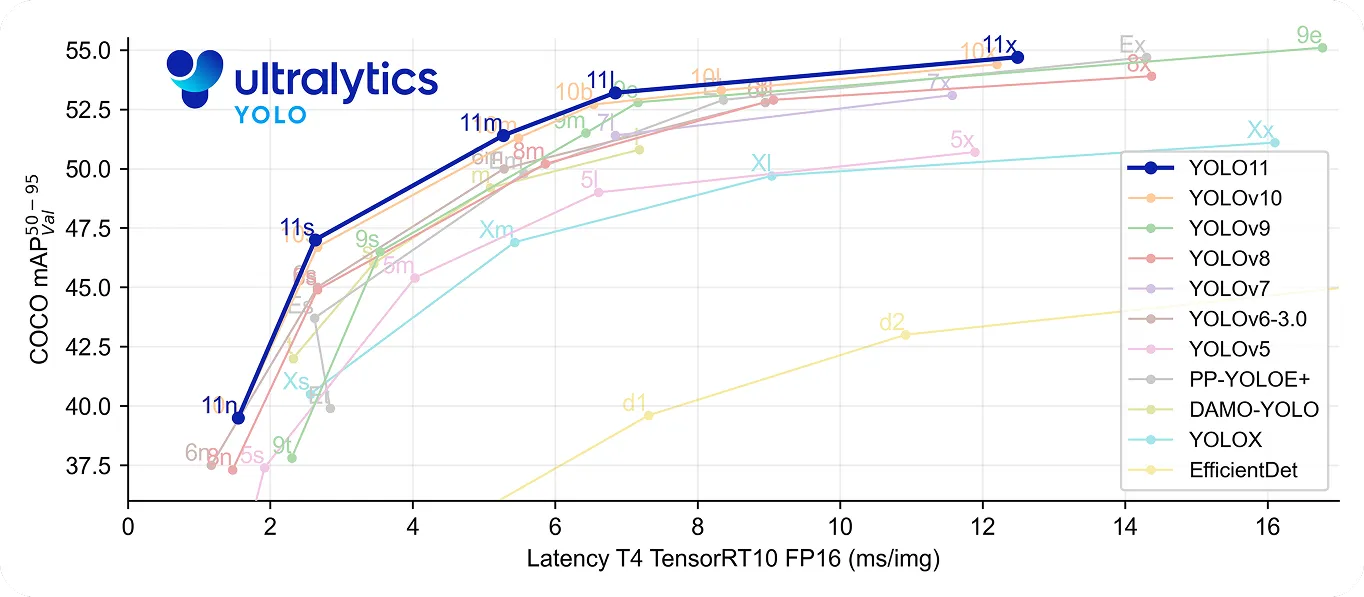
Nhìn lại lịch sử của thị giác máy tính, Mask R-CNN được công nhận là một bước đột phá lớn trong phát hiện và phân đoạn đối tượng. Nó mang lại kết quả rất chính xác ngay cả trong các cài đặt phức tạp, nhờ vào quy trình nhiều bước chi tiết của nó.
Tuy nhiên, quá trình này cũng làm cho nó chậm hơn so với các mô hình thời gian thực như YOLO . Khi nhu cầu về tốc độ và hiệu quả ngày càng tăng, nhiều ứng dụng hiện nay sử dụng các mô hình một giai đoạn như Ultralytics YOLO11 , cung cấp khả năng phát hiện vật thể nhanh chóng và chính xác. Mặc dù Mask R-CNN rất quan trọng trong việc hiểu rõ sự phát triển của thị giác máy tính, xu hướng hướng tới các giải pháp thời gian thực làm nổi bật nhu cầu ngày càng tăng về các giải pháp thị giác máy tính nhanh hơn và hiệu quả hơn.
Tham gia cộng đồng đang phát triển của chúng tôi! Khám phá kho lưu trữ GitHub của chúng tôi để tìm hiểu thêm về AI. Bạn đã sẵn sàng bắt đầu các dự án thị giác máy tính của riêng mình chưa? Hãy xem các tùy chọn cấp phép của chúng tôi. Khám phá AI trong nông nghiệp và Vision AI trong chăm sóc sức khỏe bằng cách truy cập các trang giải pháp của chúng tôi!


