



Tìm hiểu về RCNN và tác động của nó đến việc phát hiện đối tượng. Chúng tôi sẽ đề cập đến các thành phần chính, ứng dụng và vai trò của nó trong việc phát triển các kỹ thuật như Fast RCNN và YOLO .

Tìm hiểu về RCNN và tác động của nó đến việc phát hiện đối tượng. Chúng tôi sẽ đề cập đến các thành phần chính, ứng dụng và vai trò của nó trong việc phát triển các kỹ thuật như Fast RCNN và YOLO .
Phát hiện đối tượng là một nhiệm vụ thị giác máy tính có thể nhận dạng và định vị các đối tượng trong hình ảnh hoặc video cho các ứng dụng như lái xe tự động , giám sát và hình ảnh y tế . Các phương pháp phát hiện đối tượng trước đây, chẳng hạn như máy dò Viola-Jones và Histogram of Oriented Gradients (HOG) với Máy vectơ hỗ trợ (SVM), dựa trên các đặc điểm thủ công và cửa sổ trượt. Các phương pháp này thường gặp khó khăn trong việc xác định chính xác detect các vật thể trong các cảnh phức tạp với nhiều vật thể có hình dạng và kích thước khác nhau.
Mạng nơ-ron tích chập dựa trên vùng (R-CNN) đã thay đổi cách chúng ta xử lý phát hiện đối tượng. Đây là một cột mốc quan trọng trong lịch sử thị giác máy tính. Để hiểu cách các mô hình như YOLOv8 ra đời, trước tiên chúng ta cần hiểu các mô hình như R-CNN.
Được tạo bởi Ross Girshick và nhóm của ông, kiến trúc mô hình R-CNN tạo ra các đề xuất vùng, trích xuất các đặc trưng bằng Mạng nơ-ron tích chập (CNN) được huấn luyện trước, phân loại các đối tượng và tinh chỉnh các hộp giới hạn. Mặc dù điều đó có vẻ khó khăn, nhưng đến cuối bài viết này, bạn sẽ hiểu rõ về cách R-CNN hoạt động và tại sao nó lại có tác động lớn đến vậy. Hãy cùng xem nhé!
Quy trình phát hiện đối tượng của mô hình R-CNN bao gồm ba bước chính: tạo đề xuất vùng, trích xuất đặc trưng và phân loại đối tượng đồng thời tinh chỉnh các hộp giới hạn của chúng. Chúng ta hãy cùng xem xét từng bước.
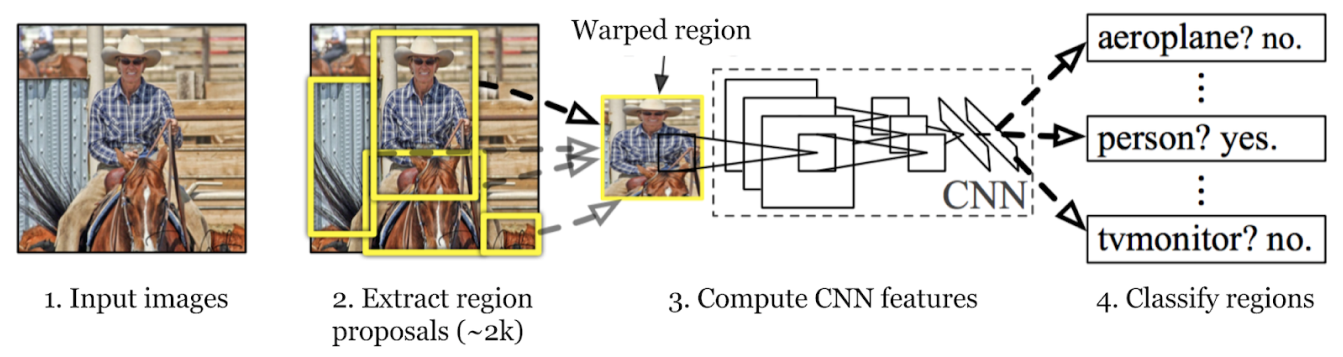
Trong bước đầu tiên, mô hình R-CNN quét hình ảnh để tạo ra nhiều đề xuất vùng. Đề xuất vùng là các khu vực tiềm năng có thể chứa các đối tượng. Các phương pháp như Tìm kiếm có chọn lọc được sử dụng để xem xét các khía cạnh khác nhau của hình ảnh, chẳng hạn như màu sắc, kết cấu và hình dạng, chia nó thành các phần khác nhau. Tìm kiếm có chọn lọc bắt đầu bằng cách chia hình ảnh thành các phần nhỏ hơn, sau đó hợp nhất các phần tương tự để tạo thành các khu vực quan tâm lớn hơn. Quá trình này tiếp tục cho đến khi khoảng 2.000 đề xuất vùng được tạo ra.
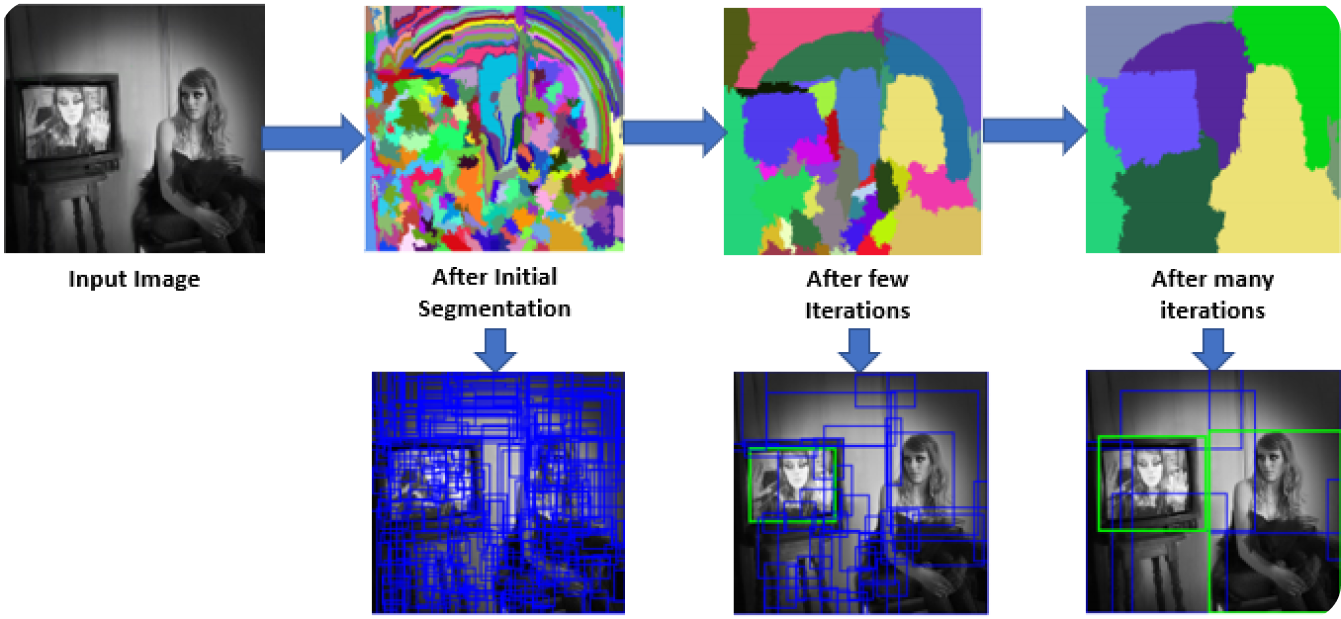
Các đề xuất khu vực này giúp xác định tất cả các vị trí có thể có nơi một đối tượng có thể xuất hiện. Trong các bước tiếp theo, mô hình có thể xử lý hiệu quả các khu vực liên quan nhất bằng cách tập trung vào các khu vực cụ thể này thay vì toàn bộ hình ảnh. Sử dụng các đề xuất khu vực cân bằng giữa tính kỹ lưỡng và hiệu quả tính toán.
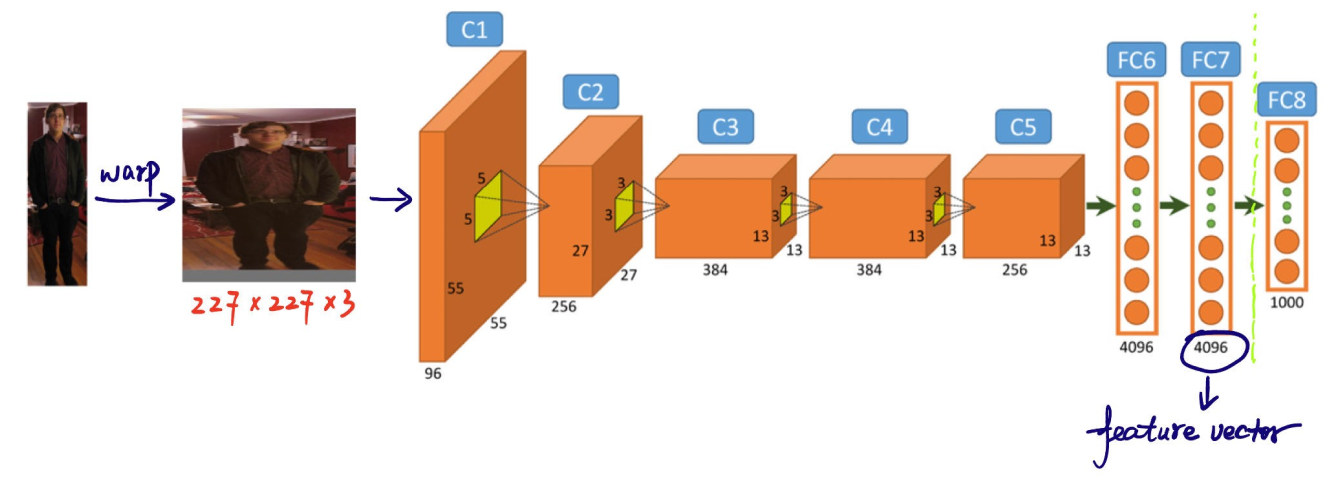
Bước tiếp theo trong quy trình phát hiện đối tượng của mô hình R-CNN là trích xuất đặc trưng từ các đề xuất vùng. Mỗi đề xuất vùng được thay đổi kích thước thành một kích thước nhất quán mà CNN yêu cầu (ví dụ: 224x224 pixel). Việc thay đổi kích thước giúp CNN xử lý từng đề xuất một cách hiệu quả. Trước khi biến dạng, kích thước của mỗi đề xuất vùng được mở rộng một chút để bao gồm thêm 16 pixel ngữ cảnh bổ sung xung quanh vùng để cung cấp thêm thông tin xung quanh nhằm trích xuất đặc trưng tốt hơn.
Sau khi thay đổi kích thước, các đề xuất khu vực này được đưa vào CNN như AlexNet, thường được đào tạo trước trên một tập dữ liệu lớn như ImageNet CNN xử lý từng vùng để trích xuất các vectơ đặc trưng đa chiều, nắm bắt các chi tiết quan trọng như cạnh, kết cấu và hoa văn. Các vectơ đặc trưng này cô đọng thông tin thiết yếu từ các vùng. Chúng chuyển đổi dữ liệu ảnh thô thành định dạng mà mô hình có thể sử dụng cho các phân tích sâu hơn. Việc phân loại và định vị chính xác các đối tượng trong các giai đoạn tiếp theo phụ thuộc vào quá trình chuyển đổi quan trọng này từ thông tin hình ảnh thành dữ liệu có ý nghĩa.
Bước thứ ba là classify Các đối tượng trong các vùng này. Điều này có nghĩa là xác định danh mục hoặc lớp của từng đối tượng được tìm thấy trong các đề xuất. Các vectơ đặc trưng được trích xuất sau đó được chuyển qua bộ phân loại học máy.
Trong trường hợp của R-CNN, Máy Vector Hỗ trợ (SVM) thường được sử dụng cho mục đích này. Mỗi SVM được huấn luyện để nhận ra một lớp đối tượng cụ thể bằng cách phân tích các vector đặc trưng và quyết định xem một vùng cụ thể có chứa một thể hiện của lớp đó hay không. Về cơ bản, đối với mỗi danh mục đối tượng, có một bộ phân loại chuyên dụng kiểm tra từng đề xuất vùng cho đối tượng cụ thể đó.
Trong quá trình huấn luyện, các bộ phân loại được cung cấp dữ liệu được gắn nhãn với các mẫu dương tính và âm tính:
Các bộ phân loại học cách phân biệt giữa các mẫu này. Hồi quy hộp giới hạn (Bounding box regression) tiếp tục tinh chỉnh vị trí và kích thước của các đối tượng được phát hiện bằng cách điều chỉnh các hộp giới hạn được đề xuất ban đầu để phù hợp hơn với ranh giới đối tượng thực tế. Mô hình R-CNN có thể xác định và định vị chính xác các đối tượng bằng cách kết hợp phân loại và hồi quy hộp giới hạn.
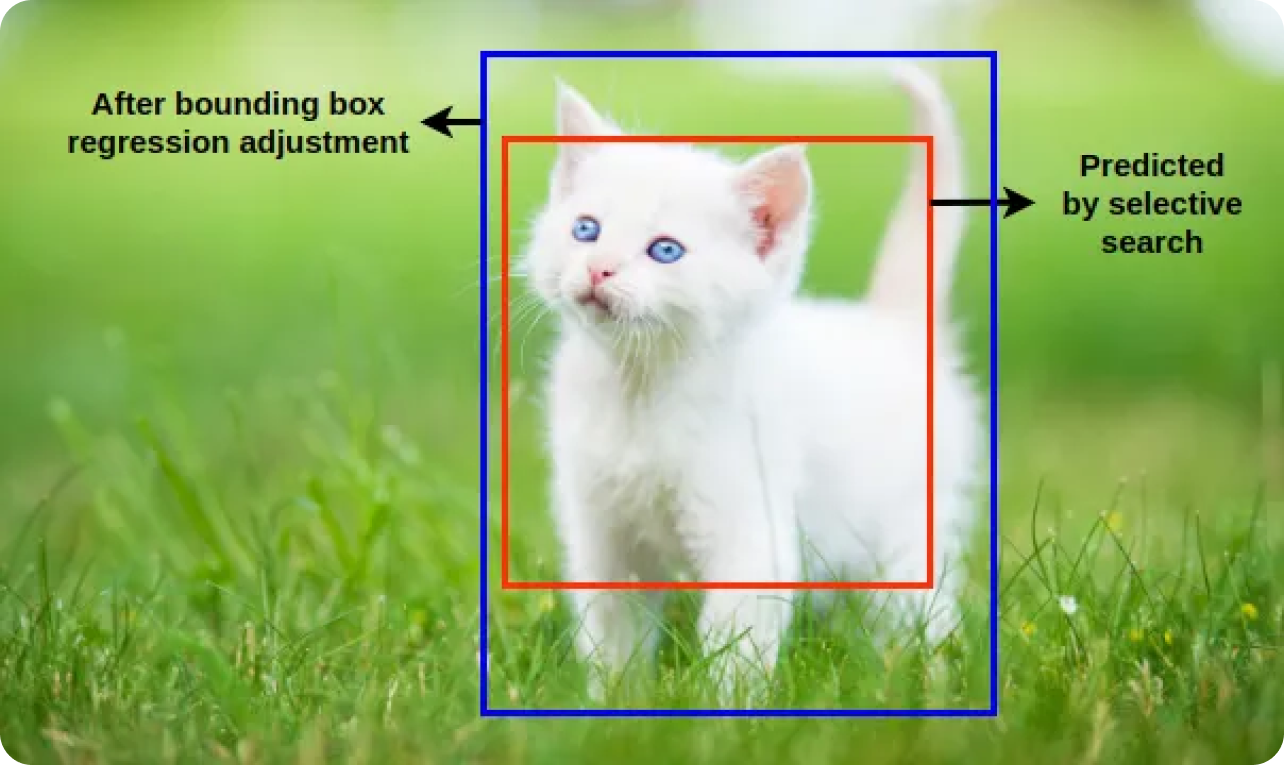
Sau các bước phân loại và hồi quy hộp giới hạn, mô hình thường tạo ra nhiều hộp giới hạn chồng lấn cho cùng một đối tượng. Loại bỏ không tối đa ( NMS ) được áp dụng để tinh chỉnh các phát hiện này, giữ lại các hộp chính xác nhất. Mô hình loại bỏ các hộp trùng lặp và dư thừa bằng cách áp dụng NMS và chỉ giữ lại những phát hiện đáng tin cậy nhất.
NMS hoạt động bằng cách đánh giá điểm tin cậy (chỉ ra khả năng thực sự có một vật thể được phát hiện) của tất cả các hộp giới hạn và loại bỏ những hộp có điểm cao hơn chồng chéo đáng kể.

Sau đây là sự phân tích các bước trong NMS :
Nói tóm lại, mô hình R-CNN phát hiện các đối tượng bằng cách tạo ra các đề xuất vùng, trích xuất các đặc điểm bằng CNN, phân loại các đối tượng và tinh chỉnh vị trí của chúng bằng hồi quy hộp giới hạn và sử dụng Non-Maximum Suppression ( NMS ) chỉ giữ lại những phát hiện chính xác nhất.
R-CNN là một mô hình mang tính bước ngoặt trong lịch sử nhận diện đối tượng vì nó giới thiệu một phương pháp mới giúp cải thiện đáng kể độ chính xác và hiệu suất. Trước R-CNN, các mô hình nhận diện đối tượng phải vật lộn để cân bằng giữa tốc độ và độ chính xác. Phương pháp tạo đề xuất vùng và sử dụng CNN để trích xuất đặc trưng của R-CNN cho phép định vị và xác định chính xác các đối tượng trong ảnh.
R-CNN đã mở đường cho các mô hình như Fast R-CNN, Faster R-CNN và Mask R-CNN, giúp nâng cao hơn nữa hiệu quả và độ chính xác. Bằng cách kết hợp học sâu với phân tích dựa trên vùng, R-CNN đã thiết lập một tiêu chuẩn mới trong lĩnh vực này và mở ra những khả năng cho các ứng dụng thực tế khác nhau.
Một trường hợp sử dụng thú vị của R-CNN là trong hình ảnh y tế . Các mô hình R-CNN đã được sử dụng để detect Và classify các loại khối u khác nhau, chẳng hạn như khối u não , trong các hình ảnh chụp cắt lớp y tế như MRI và CT. Việc sử dụng mô hình R-CNN trong chẩn đoán hình ảnh y tế giúp cải thiện độ chính xác chẩn đoán và giúp các bác sĩ X quang phát hiện các khối u ác tính ở giai đoạn sớm. Khả năng của R-CNN detect ngay cả những khối u nhỏ và giai đoạn đầu cũng có thể tạo ra sự khác biệt đáng kể trong việc điều trị và tiên lượng các bệnh như ung thư.
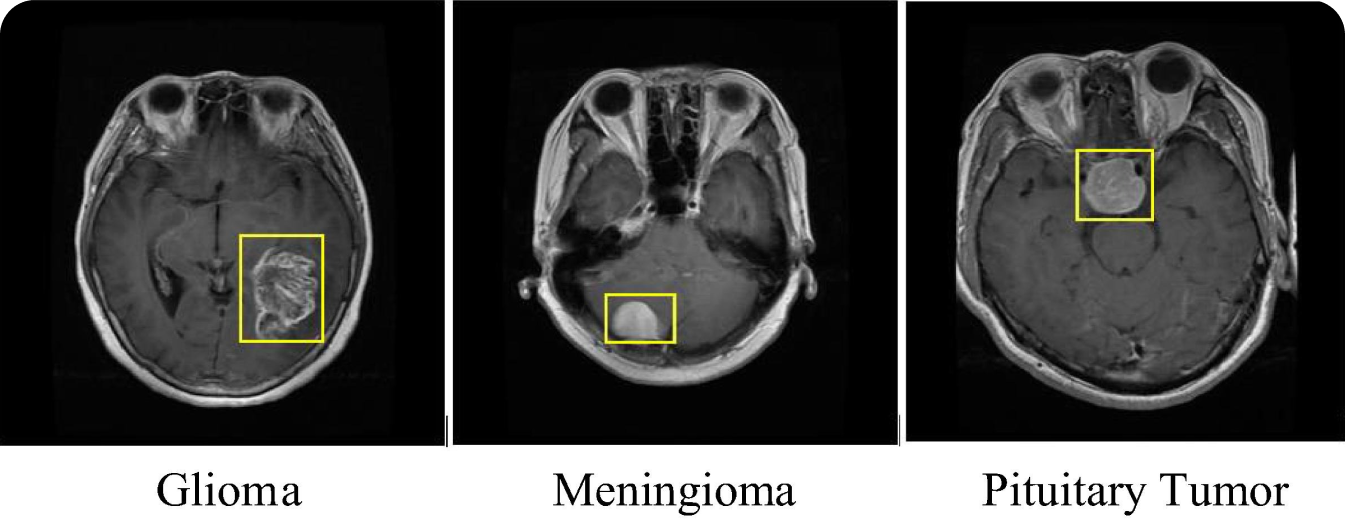
Mô hình R-CNN có thể được áp dụng cho các nhiệm vụ chụp ảnh y tế khác ngoài việc phát hiện khối u. Ví dụ, nó có thể xác định gãy xương, detect Các bệnh lý võng mạc trong chụp mắt và phân tích hình ảnh phổi để phát hiện các tình trạng như viêm phổi và COVID-19. Bất kể vấn đề y tế nào, việc phát hiện sớm có thể mang lại kết quả tốt hơn cho bệnh nhân . Bằng cách áp dụng độ chính xác của R-CNN trong việc xác định và định vị các bất thường, các nhà cung cấp dịch vụ chăm sóc sức khỏe có thể cải thiện độ tin cậy và tốc độ chẩn đoán y tế. Với việc phát hiện vật thể giúp đơn giản hóa quy trình chẩn đoán, bệnh nhân có thể được hưởng lợi từ các kế hoạch điều trị kịp thời và chính xác.
Mặc dù ấn tượng, R-CNN có một số nhược điểm nhất định, chẳng hạn như độ phức tạp tính toán cao và thời gian suy luận chậm. Những nhược điểm này làm cho mô hình R-CNN không phù hợp với các ứng dụng thời gian thực. Việc tách các đề xuất vùng và phân loại thành các bước riêng biệt có thể dẫn đến hiệu suất kém hiệu quả hơn.
Trong những năm qua, nhiều mô hình phát hiện đối tượng khác nhau đã ra đời để giải quyết những lo ngại này. Fast R-CNN kết hợp các đề xuất vùng và trích xuất đặc trưng CNN thành một bước duy nhất, giúp tăng tốc quá trình. Faster R-CNN giới thiệu Mạng đề xuất vùng (RPN) để hợp lý hóa việc tạo đề xuất, trong khi Mask R-CNN thêm phân đoạn cấp pixel để phát hiện chi tiết hơn.

Cùng thời điểm với Faster R-CNN, YOLO (Bạn chỉ nhìn một lần) bắt đầu phát triển công nghệ phát hiện vật thể theo thời gian thực. YOLO Các mô hình dự đoán các hộp giới hạn và xác suất lớp chỉ trong một lần chạy qua mạng. Ví dụ, Ultralytics YOLOv8 cung cấp độ chính xác và tốc độ được cải thiện với các tính năng tiên tiến cho nhiều tác vụ thị giác máy tính.
RCNN đã thay đổi cuộc chơi trong lĩnh vực thị giác máy tính, cho thấy học sâu có thể thay đổi khả năng phát hiện vật thể như thế nào. Thành công của nó đã truyền cảm hứng cho nhiều ý tưởng mới trong lĩnh vực này. Mặc dù các mô hình mới hơn như Faster R-CNN và YOLO đã đưa ra để khắc phục những sai sót của RCNN, đóng góp của họ là một cột mốc quan trọng cần ghi nhớ.
Khi nghiên cứu tiếp tục, chúng ta sẽ thấy các mô hình phát hiện đối tượng tốt hơn và nhanh hơn nữa. Những tiến bộ này sẽ không chỉ cải thiện cách máy móc hiểu thế giới mà còn dẫn đến tiến bộ trong nhiều ngành công nghiệp. Tương lai của phát hiện đối tượng có vẻ thú vị!
Bạn có muốn tiếp tục khám phá về AI không? Hãy trở thành một phần của Ultralytics Cộng đồng ! Khám phá kho lưu trữ GitHub của chúng tôi để xem những đổi mới trí tuệ nhân tạo mới nhất. Khám phá các giải pháp AI của chúng tôi trải dài trên nhiều lĩnh vực như nông nghiệp và sản xuất . Tham gia cùng chúng tôi để học hỏi và phát triển!


