



Join us as we explore how diffusion models can be used to create realistic content and redefine fields like design, music, and film with various applications.

Join us as we explore how diffusion models can be used to create realistic content and redefine fields like design, music, and film with various applications.
Using generative AI tools like Midjourney and Sora to create content is becoming increasingly common, and there is a rising interest in looking under the hood of these tools. In fact, a recent study shows that 94% of individuals are prepared to learn new skills to work with generative AI. Understanding how generative AI models work can help you use these tools more effectively and get the most out of them.
At the heart of tools like Midjourney and Sora are advanced diffusion models - generative AI models that can create images, videos, text, and audio for various applications. For example, diffusion models are a great option for producing short marketing videos for social media platforms like TikTok and YouTube Shorts. In this article, we’ll explore how diffusion models work and where they can be used. Let’s get started!
In physics, diffusion is the process by which molecules spread out from areas of higher concentration to areas of lower concentration. The concept of diffusion is closely related to Brownian motion, where particles move randomly as they collide with molecules in a fluid and gradually spread out over time.
These concepts inspired the development of diffusion models in generative AI. Diffusion models work by gradually adding noise to data and then learning to reverse that process to generate new, high-quality data like text, images, or sound. It is similar to the idea of reverse diffusion in physics. Theoretically, diffusion can be tracked backward to return particles to their original state. In the same way, diffusion models learn to reverse the added noise to create realistic new data from noisy inputs.

Generally, a diffusion model’s architecture involves two main steps. First, the model learns to add noise to the dataset gradually. Then, it’s trained to reverse this process and bring the data back to its original state. Let’s take a closer look at how this works.
Before we dive into the core of a diffusion model, it’s important to remember that any data the model is trained on should be preprocessed. For example, if you are training a diffusion model to generate images, the training dataset of images needs to be cleaned up first. Preprocessing image data can involve removing any outliers that could affect the results, normalizing the pixel values so that all the images are on the same scale, and using data augmentation to introduce more variety. Data preprocessing steps help guarantee the quality of training data, and this is true not just for diffusion models but any AI model.
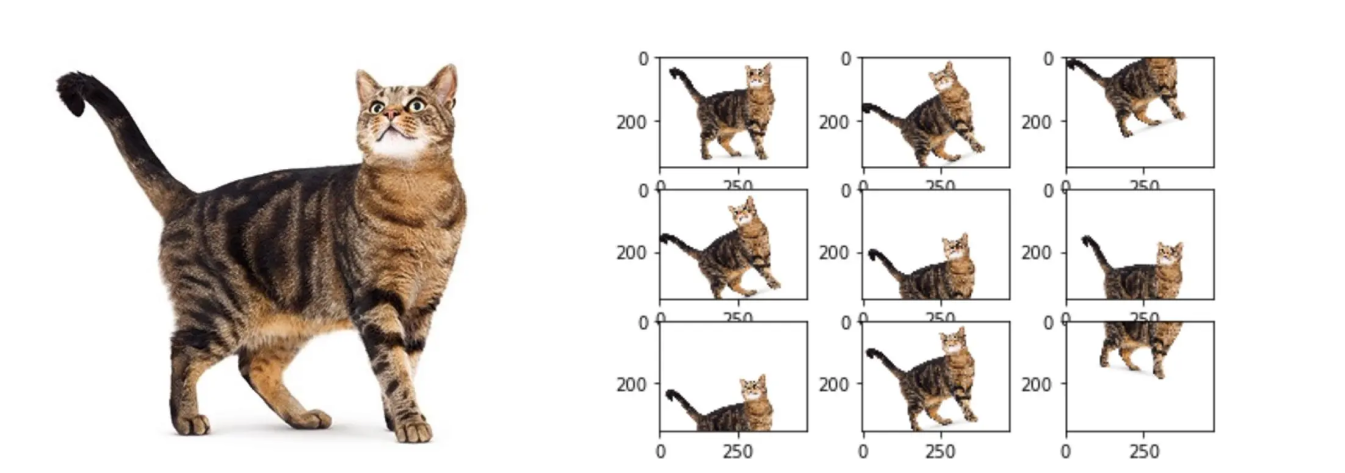
After data preprocessing, the next step is the forward diffusion process. Let’s focus on training a diffusion model to generate images. The process begins by sampling from a simple distribution, like a Gaussian distribution. In other words, some random noise is selected. As shown in the image below, the model gradually transforms the image in a series of steps. The image starts off clear and becomes increasingly noisy as it progresses through each step, eventually turning into almost complete noise by the end.

Each step builds on the previous one, and noise is added in a controlled, incremental way using a Markov Chain. A Markov chain is a mathematical model where the probability of the next state depends only on the current state. It's used to predict future outcomes based on present conditions. As each step adds complexity to the data, we can capture the most intricate patterns and details of the original image data distribution. The addition of Gaussian noise also generates diverse and realistic samples as the diffusion unfolds.
The reverse diffusion process begins once the forward diffusion process has transformed a sample into a noisy, complex state. It gradually maps the noisy sample back to its original state using a series of inverse transformations. The steps that reverse the noise-adding process are guided by a reverse Markov Chain.
.png)
During the reverse process, diffusion models learn to generate new data by starting with a random noise sample and gradually refining it into a clear, detailed output. The generated data ends up closely resembling the original dataset. This capability is what makes diffusion models great for tasks like image synthesis, data completion, and denoising. In the next section, we'll explore more applications of diffusion models.
The step-by-step diffusion process makes it possible for diffusion model to efficiently generate complex data distributions without being overwhelmed by the data's high dimensionality. Let’s take a look at some applications where diffusion models excel.
Diffusion models can be used to generate graphical visual content quickly. Human designers and artists can provide input sketches, layouts, or even some simple rough ideas of what they want, and the models can bring these ideas to life. It can speed up the entire design process, offer a wide range of new possibilities from the initial concept to the final product, and save a lot of valuable time for human designers.

Diffusion models can also be adapted to generate very unique soundscapes or music notes. It offers new ways for musicians and artists to visualize and create auditory experiences. Here are some of the use cases of diffusion models in the field of sound and music creation:
Another interesting use case of diffusion models is in creating film and animation clips. They can be used to generate characters, realistic backgrounds, and even dynamic elements within scenes. Using diffusion models can be a big advantage for production companies. It streamlines the overall workflow and makes way for more experimentation and creativity in visual storytelling. Some of the clips made using these models are comparable with actual animated or film clips. It is even possible to use these models to create entire movies.

Now that we've learned about some of the applications of diffusion models, let's look at some popular diffusion models that you can try using.
While diffusion models offer benefits across many industries, we should also keep in mind some of the challenges that come with them. One challenge is that the training process is very resource-intensive. While advancements in hardware acceleration can help, they can be costly. Another issue is the limited ability of diffusion models to generalize to unseen data. Adapting them to specific domains can require lots of fine-tuning or retraining.
Integrating these models into real-world tasks comes with its own set of challenges. It's key that what the AI generates actually matches what humans intend. There are also ethical concerns, like the risk of these models picking up and reflecting biases from the data they're trained on. On top of that, managing user expectations and constantly refining the models based on feedback can become an ongoing effort to make sure these tools are as effective and reliable as possible.
Diffusion models are a fascinating concept in generative AI that helps create high-quality images, videos, and sounds across many different fields. While they can present some implementation challenges, like computational demands and ethical concerns, the AI community is constantly working on improving their efficiency and impact. Diffusion models are all set to transform industries like film, music production, and digital content creation as they continue to evolve.
Let's learn and explore together! Check out our GitHub repository to see our contributions to AI. Discover how we are redefining industries like manufacturing and healthcare with cutting-edge AI technology.
Begin your journey with the future of machine learning


