



Explorez l'histoire, les réalisations, les défis et les orientations futures des modèles de vision.

Explorez l'histoire, les réalisations, les défis et les orientations futures des modèles de vision.
Imaginez entrer dans un magasin où une caméra identifie votre visage, analyse votre humeur et suggère des produits adaptés à vos préférences, le tout en temps réel. Ce n'est pas de la science-fiction, mais une réalité rendue possible par les modèles de vision modernes. Selon un rapport de Fortune Business Insight, la taille du marché mondial de la vision par ordinateur était évaluée à 20,31 milliards de dollars américains en 2023 et devrait passer de 25,41 milliards de dollars américains en 2024 à 175,72 milliards de dollars américains d'ici 2032, ce qui témoigne des progrès rapides et de l'adoption croissante de cette technologie dans divers secteurs.
Le domaine de la vision par ordinateur permet aux ordinateurs de detect, d'identifier et d'analyser des objets dans des images. À l'instar d'autres domaines liés à l'intelligence artificielle, la vision par ordinateur a connu une évolution rapide au cours des dernières décennies, réalisant des progrès remarquables.
L'histoire de la vision par ordinateur est vaste. Dans ses premières années, les modèles de vision par ordinateur étaient capables de détecter des formes et des contours simples, souvent limités à des tâches de base comme la reconnaissance de motifs géométriques ou la différenciation entre les zones claires et sombres. Cependant, les modèles d'aujourd'hui peuvent effectuer des tâches complexes telles que la détection d'objets en temps réel, la reconnaissance faciale et même l'interprétation des émotions à partir des expressions faciales avec une précision et une efficacité exceptionnelles. Cette progression spectaculaire met en évidence les incroyables progrès réalisés en matière de puissance de calcul, de sophistication algorithmique et de disponibilité de vastes quantités de données pour l'entraînement.
Dans cet article, nous explorerons les principales étapes de l'évolution de la vision par ordinateur. Nous voyagerons à travers ses débuts, nous plongerons dans l'impact transformateur des réseaux neuronaux convolutifs (CNN) et nous examinerons les avancées significatives qui ont suivi.
Comme pour les autres domaines de l'IA, le développement initial de la vision par ordinateur a commencé par des recherches fondamentales et des travaux théoriques. Une étape importante a été le travail de pionnier de Lawrence G. Roberts sur la reconnaissance d'objets 3D, documenté dans sa thèse "Machine Perception of Three-Dimensional Solids" au début des années 1960. Ses contributions ont jeté les bases des progrès futurs dans le domaine.
Les premières recherches sur la vision par ordinateur se sont concentrées sur les techniques de traitement d'images, telles que la détection des contours et l'extraction des caractéristiques. Des algorithmes tels que l'opérateur Sobel, développé à la fin des années 1960, ont été parmi les premiers à detect contours en calculant le gradient de l'intensité de l'image.

Des techniques comme les détecteurs de contours de Sobel et de Canny ont joué un rôle crucial dans l'identification des limites au sein des images, ce qui est essentiel pour la reconnaissance d'objets et la compréhension des scènes.
Dans les années 1970, la reconnaissance de formes est apparue comme un domaine clé de la vision par ordinateur. Les chercheurs ont développé des méthodes pour reconnaître les formes, les textures et les objets dans les images, ce qui a ouvert la voie à des tâches de vision plus complexes.

L'une des premières méthodes de reconnaissance de formes impliquait la correspondance de modèles, où une image est comparée à un ensemble de modèles pour trouver la meilleure correspondance. Cette approche était limitée par sa sensibilité aux variations d'échelle, de rotation et de bruit.
Les premiers systèmes de vision par ordinateur étaient limités par la puissance de calcul limitée de l'époque. Les ordinateurs des années 1960 et 1970 étaient volumineux, coûteux et avaient des capacités de traitement limitées.
L'apprentissage profond et les réseaux neuronaux convolutifs (CNN) ont marqué un tournant décisif dans le domaine de la vision par ordinateur. Ces avancées ont considérablement transformé la façon dont les ordinateurs interprètent et analysent les données visuelles, permettant ainsi un large éventail d'applications que l'on pensait auparavant impossibles.
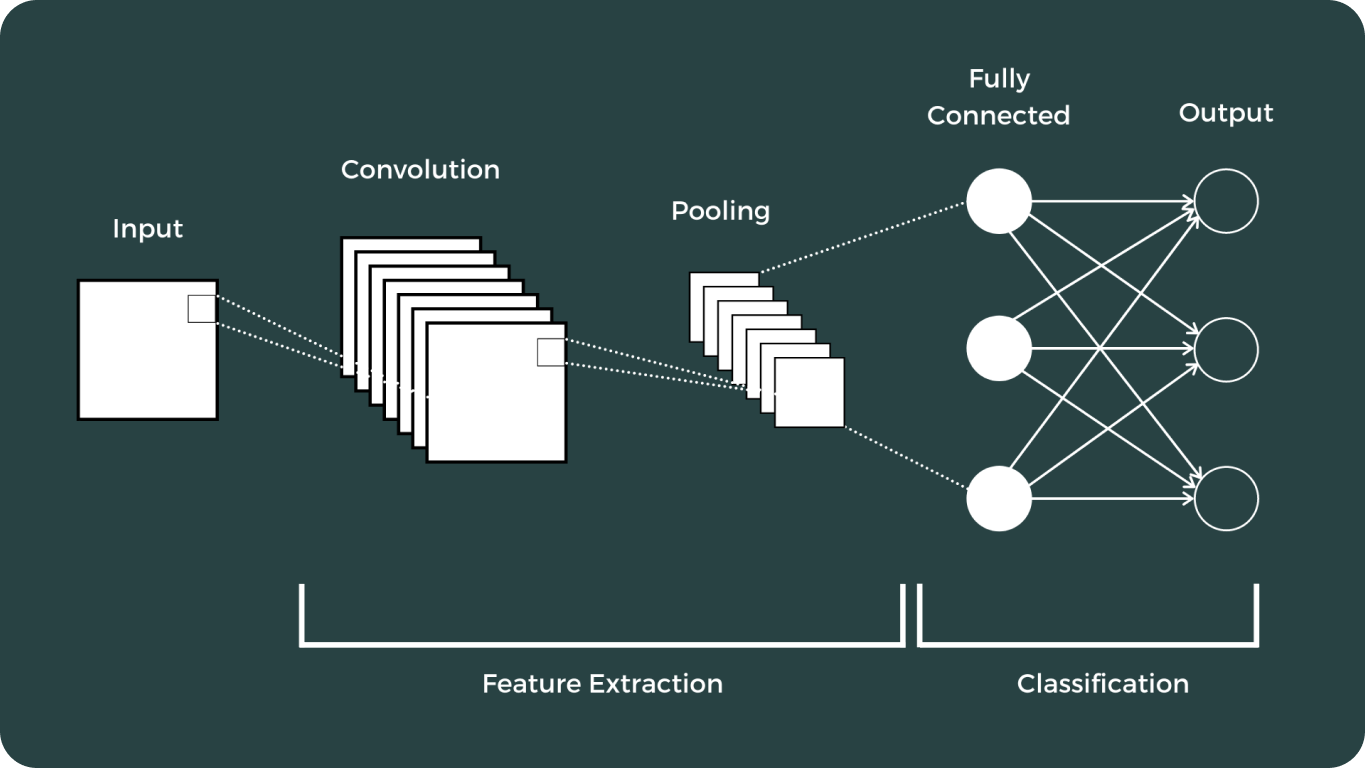
Le parcours des modèles de vision a été long, avec certains des plus notables :
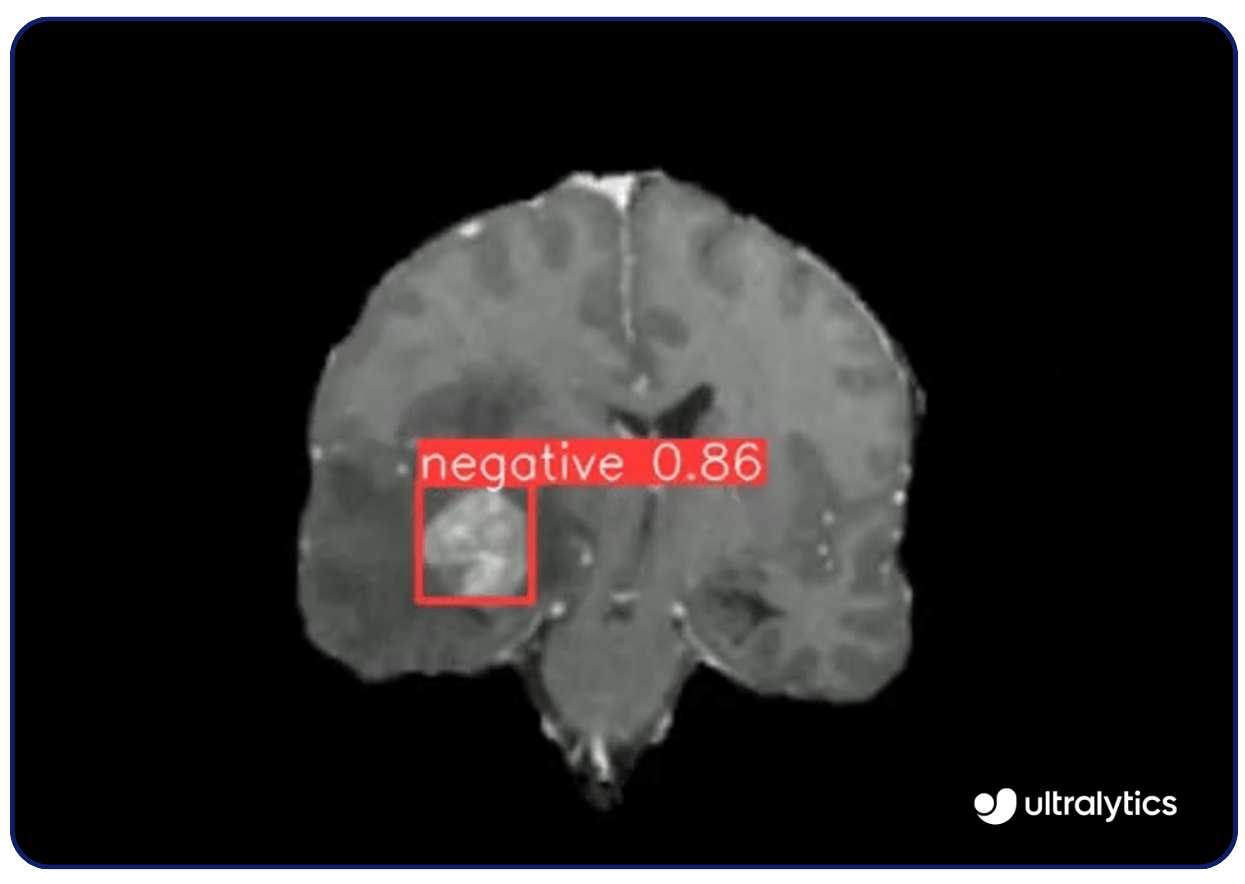
Lesutilisations de la vision par ordinateur sont nombreuses. Par exemple, des modèles de vision comme Ultralytics YOLOv8 sont utilisés en imagerie médicale pour detect maladies telles que le cancer et la rétinopathie diabétique. Ils analysent les rayons X, les IRM et les tomodensitogrammes avec une grande précision, identifiant rapidement les anomalies. Cette capacité de détection précoce permet d'intervenir à temps et d'améliorer les résultats pour les patients.
Les modèles de vision par ordinateur aident à surveiller et à protéger les espèces menacées en analysant les images et les vidéos des habitats de la faune. Ils identifient et track comportement des animaux, fournissant des données sur leur population et leurs mouvements. Cette technologie éclaire les stratégies de conservation et les décisions politiques visant à protéger des espèces telles que les tigres et les éléphants.
Grâce à l'IA de vision, d'autres menaces environnementales telles que les incendies de forêt et la déforestation peuvent être surveillées, assurant des temps de réponse rapides de la part des autorités locales.

Même s'ils ont déjà réalisé des progrès importants, en raison de leur extrême complexité et de la nature exigeante de leur développement, les modèles de vision sont confrontés à de nombreux défis qui nécessitent des recherches continues et des avancées futures.
Les modèles de vision, en particulier ceux d'apprentissage profond, sont souvent considérés comme des "boîtes noires" avec une transparence limitée. Cela est dû à la complexité de ces modèles. Le manque d'interprétabilité entrave la confiance et la responsabilité, en particulier dans les applications critiques comme les soins de santé, par exemple.
L'entraînement et le déploiement de modèles d'IA de pointe exigent des ressources de calcul importantes. Cela est particulièrement vrai pour les modèles de vision, qui nécessitent souvent le traitement de grandes quantités de données d'images et de vidéos. Les images et vidéos haute définition, qui figurent parmi les entrées d'entraînement les plus gourmandes en données, augmentent la charge de calcul. Par exemple, une seule image HD peut occuper plusieurs mégaoctets de stockage, ce qui rend le processus d'entraînement gourmand en ressources et chronophage.
Cela nécessite un matériel puissant et des algorithmes de vision par ordinateur optimisés pour traiter les données volumineuses et les calculs complexes impliqués dans le développement de modèles de vision efficaces. La recherche sur des architectures plus efficaces, la compression de modèles et les accélérateurs matériels tels que les GPU et les TPU sont des domaines clés qui feront progresser l'avenir des modèles de vision.
Ces améliorations visent à réduire les besoins de calcul et à accroître l'efficacité du traitement. En outre, l'utilisation de modèles avancés pré-entraînés tels que YOLOv8 peut réduire considérablement la nécessité d'une formation approfondie, rationalisant ainsi le processus de développement et améliorant l'efficacité.
Aujourd'hui, les applications des modèles de vision sont très répandues, allant des soins de santé, comme la détection de tumeurs, aux utilisations quotidiennes comme la surveillance du trafic. Ces modèles avancés ont apporté l'innovation à d'innombrables industries en fournissant une précision, une efficacité et des capacités améliorées qui étaient auparavant inimaginables.
À mesure que la technologie continue de progresser, le potentiel des modèles de vision pour innover et améliorer divers aspects de la vie et de l'industrie reste illimité. Cette évolution constante souligne l'importance de la poursuite de la recherche et du développement dans le domaine de la vision par ordinateur.
Curieux de connaître l'avenir de l'IA visionnaire ? Pour en savoir plus sur les dernières avancées, explorez les documents d'Ultralytics et consultez leurs projets sur Ultralytics GitHub et YOLOv8 GitHub. En outre, pour avoir un aperçu des applications de l'IA dans divers secteurs, les pages de solutions sur les voitures autonomes et la fabrication offrent des informations particulièrement utiles.


