


Exploration de la fiche descriptive du modèle Claude 3 : ce que cela signifie pour la vision IA

Découvrez la fiche de modèle Claude 3 et son impact sur le développement de l'IA de vision.

Découvrez la fiche de modèle Claude 3 et son impact sur le développement de l'IA de vision.
Ces dernières années, l'IA de vision a fait des progrès considérables, révolutionnant divers secteurs, de la santé au commerce de détail. La compréhension des modèles sous-jacents et de leur documentation est essentielle pour exploiter efficacement ces avancées. Un outil essentiel dans l'arsenal du développeur en intelligence artificielle (IA) est la fiche de modèle, qui offre une vue d'ensemble complète des caractéristiques et des performances d'un modèle d'IA.
Dans cet article, nous allons explorer la carte modèle Claude 3, développée par Anthropic, et ses implications pour le développement de Vision AI. Claude 3 est une nouvelle famille de grands modèles multimodaux comprenant trois variantes : Claude 3 Opus, le modèle le plus performant ; Claude 3 Sonnet, qui équilibre performance et vitesse ; et Claude 3 Haiku, l'option la plus rapide et la plus économique. Chaque modèle est nouvellement équipé de capacités de vision, ce qui leur permet de traiter et d'analyser des données d'image.
Qu'est-ce qu'une carte de modèle, exactement ? Une carte de modèle est un document détaillé qui fournit des informations sur le développement, l'entraînement et l'évaluation d'un modèle d'apprentissage automatique. Elle vise à promouvoir la transparence, la responsabilité et l'utilisation éthique de l'IA en présentant des informations claires sur la fonctionnalité du modèle, les cas d'utilisation prévus et les limitations potentielles. Ceci peut être réalisé en fournissant des données plus détaillées sur le modèle, telles que ses métriques d'évaluation, et sa comparaison avec les modèles précédents et d'autres concurrents.
Les métriques d'évaluation sont essentielles pour évaluer les performances du modèle. La fiche descriptive du modèle Claude 3 répertorie des métriques telles que la précision, la justesse, le rappel et le score F1, offrant une image claire des points forts du modèle et des domaines à améliorer. Ces métriques sont comparées aux normes de l'industrie, ce qui met en évidence les performances concurrentielles de Claude 3.
De plus, Claude 3 s'appuie sur les forces de ses prédécesseurs, intégrant des avancées en matière d'architecture et de techniques d'entraînement. La fiche du modèle compare Claude 3 avec les versions antérieures, soulignant les améliorations en termes de précision, d'efficacité et d'applicabilité à de nouveaux cas d'utilisation.
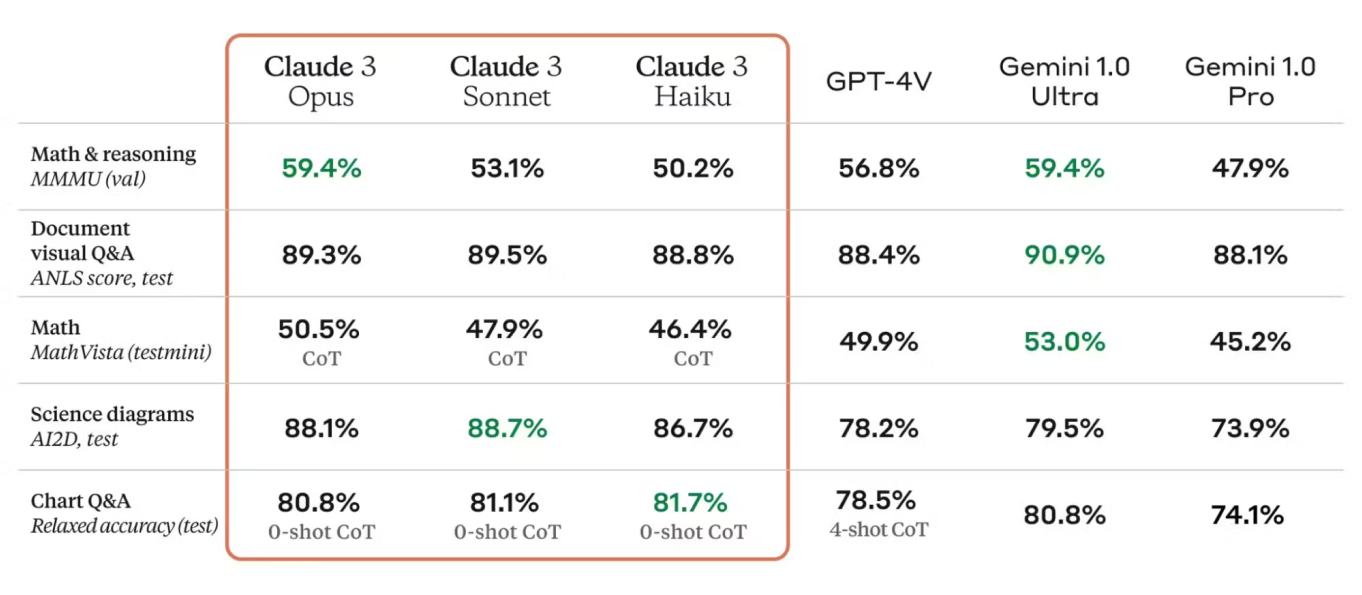
L'architecture et le processus d'entraînement de Claude 3 se traduisent par des performances fiables dans diverses tâches de traitement du langage naturel (TLN) et visuelles. Il obtient constamment d'excellents résultats dans les benchmarks, ce qui démontre sa capacité à effectuer efficacement des analyses linguistiques complexes.
L'entraînement de Claude 3 sur divers ensembles de données et l'utilisation de techniques d'augmentation des données garantissent sa robustesse et sa capacité à généraliser dans différents scénarios. Cela rend le modèle polyvalent et efficace dans un large éventail d'applications.
Bien que ses résultats soient remarquables, Claude 3 est fondamentalement un grand modèle de langage (LLM). Bien que les LLM comme Claude 3 puissent effectuer diverses tâches de vision par ordinateur, ils n'ont pas été spécifiquement conçus pour des tâches telles que la détection d'objets, la création de boîtes de délimitation et la segmentation d'images. Par conséquent, leur précision dans ces domaines peut ne pas correspondre à celle des modèles spécifiquement conçus pour la vision par ordinateur, tels que Ultralytics YOLOv8. Néanmoins, les LLM excellent dans d'autres domaines, en particulier dans le traitement du langage naturel (NLP), où Claude 3 démontre une force significative en fusionnant des tâches visuelles simples avec le raisonnement humain.

Les capacités de NLP (traitement automatique du langage naturel) font référence à la capacité d'un modèle d'IA à comprendre et à répondre au langage humain. Cette capacité est largement exploitée dans les applications de Claude 3 dans le domaine visuel, lui permettant de fournir des descriptions riches en contexte, d'interpréter des données visuelles complexes et d'améliorer les performances globales dans les tâches de Vision AI.
L'une des capacités impressionnantes de Claude 3, en particulier lorsqu'elle est exploitée pour des tâches de Vision IA, est sa capacité à traiter et à convertir en texte des images de faible qualité avec une écriture manuscrite difficile à lire. Cette fonctionnalité met en évidence la puissance de traitement avancée du modèle et ses capacités de raisonnement multimodal. Dans cette section, nous explorerons comment Claude 3 accomplit cette tâche, en soulignant les mécanismes sous-jacents et les implications pour le développement de la Vision IA.
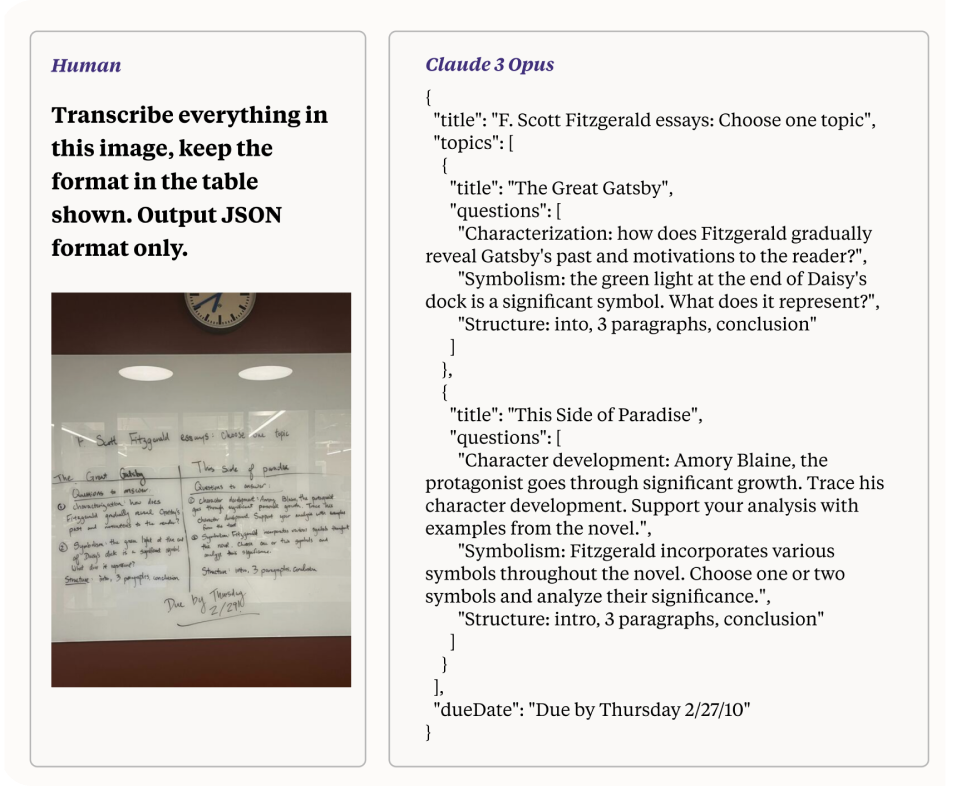
La conversion d'une photo de mauvaise qualité avec une écriture manuscrite difficile à lire en texte est une tâche complexe qui implique plusieurs défis :
Comme mentionné précédemment, les modèles Claude 3 relèvent ces défis grâce à une combinaison de techniques avancées en vision par ordinateur et en traitement du langage naturel (TLN).
L'architecture de Claude 3 lui permet d'effectuer des tâches de raisonnement complexes à l'aide d'entrées visuelles. Par exemple, comme le montre la figure 1, le modèle peut interpréter des graphiques et des diagrammes, comme l'identification des pays du G7 dans un graphique sur l'utilisation d'Internet, l'extraction de données pertinentes et l'exécution de calculs pour analyser les tendances. Ce raisonnement en plusieurs étapes, comme le calcul des différences statistiques dans l'utilisation d'Internet entre les groupes d'âge, améliore la précision et l'utilité du modèle dans les applications du monde réel.

Claude 3 excelle dans la transformation d'images en descriptions détaillées, démontrant ainsi ses puissantes capacités en matière de vision par ordinateur et de traitement du langage naturel. Lorsqu'on lui présente une image, Claude 3 utilise d'abord des réseaux neuronaux convolutifs (CNN) pour extraire les caractéristiques clés et identifier les objets, les motifs et les éléments contextuels dans les données visuelles.
Ensuite, les couches de transformateur analysent ces caractéristiques, en tirant parti des mécanismes d'attention pour comprendre les relations et le contexte entre les différents éléments de l'image. Cette approche multimodale permet à Claude 3 de générer des descriptions précises et riches en contexte en identifiant non seulement les objets, mais aussi en comprenant leurs interactions et leur signification dans la scène.

Les grands modèles de langage (LLM) comme Claude 3 excellent dans le traitement du langage naturel, pas dans la vision par ordinateur. Bien qu'ils puissent décrire des images, des tâches telles que la détection d'objets et la segmentation d'images sont mieux gérées par des modèles orientés vision comme YOLOv8. Ces modèles spécialisés sont optimisés pour les tâches visuelles et offrent de meilleures performances pour l'analyse des images. En outre, le modèle ne peut pas effectuer des tâches telles que la création de boîtes de délimitation.
La combinaison de Claude 3 avec des systèmes de vision par ordinateur peut être complexe et nécessiter des étapes de traitement supplémentaires pour combler le fossé entre le texte et les données visuelles.
Claude 3 est principalement entraîné sur de grandes quantités de données textuelles, ce qui signifie qu'il ne dispose pas des vastes ensembles de données visuelles nécessaires pour atteindre des performances élevées dans les tâches de vision par ordinateur. Par conséquent, bien que Claude 3 excelle dans la compréhension et la génération de texte, il n'a pas la capacité de traiter ou d'analyser des images avec le même niveau de compétence que les modèles spécialement conçus pour les données visuelles. Cette limitation le rend moins efficace pour les applications qui nécessitent l'interprétation ou la génération de contenu visuel.
Comme les autres grands modèles linguistiques, Claude 3 est conçu pour une amélioration continue. Les améliorations futures se concentreront probablement sur de meilleures tâches visuelles telles que la détection d'images et la reconnaissance d'objets, ainsi que sur les progrès des tâches de traitement du langage naturel. Cela permettra des descriptions plus précises et détaillées des objets et des scènes, entre autres tâches similaires.
Enfin, les recherches en cours sur Claude 3 viseront en priorité à améliorer l'interprétabilité, à réduire les biais et à améliorer la généralisation sur divers ensembles de données. Ces efforts garantiront la performance robuste du modèle dans diverses applications et favoriseront la confiance et la fiabilité de ses résultats.
La fiche de modèle Claude 3 est une ressource précieuse pour les développeurs et les parties prenantes de Vision AI, fournissant des informations détaillées sur l'architecture, les performances et les considérations éthiques du modèle. En promouvant la transparence et la responsabilité, elle contribue à garantir une utilisation responsable et efficace des technologies d'IA. Alors que Vision AI continue d'évoluer, le rôle des fiches de modèle comme celle de Claude 3 sera crucial pour guider le développement et favoriser la confiance dans les systèmes d'IA.
Chez Ultralytics, nous sommes passionnés par l'avancement de la technologie de l'IA. Pour explorer nos solutions d'IA et rester informé de nos dernières innovations, visitez notre dépôt GitHub. Rejoignez notre communauté sur Discord et découvrez comment nous transformons des industries telles que les voitures auto-conduites et la fabrication! 🚀


