



Rejoignez-nous pour examiner de plus près les nouveaux modèles de langage de vision de Google: PaliGemma 2. Ces modèles peuvent aider à comprendre et à analyser des images et du texte.

Rejoignez-nous pour examiner de plus près les nouveaux modèles de langage de vision de Google: PaliGemma 2. Ces modèles peuvent aider à comprendre et à analyser des images et du texte.
Le 5 décembre 2024, Google a présenté PaliGemma 2, la dernière version de son modèle vision-langage (VLM) de pointe. PaliGemma 2 est conçu pour traiter des tâches combinant images et texte, telles que la génération de légendes, la réponse à des questions visuelles et la détection d'objets dans des images.
S'appuyant sur le PaliGemma original, qui était déjà un outil puissant pour la légende multilingue et la reconnaissance d'objets, PaliGemma 2 apporte plusieurs améliorations clés. Il s'agit notamment de modèles de plus grande taille, de la prise en charge d'images à plus haute résolution et de meilleures performances sur des tâches visuelles complexes. Ces mises à niveau le rendent encore plus flexible et efficace pour un large éventail d'utilisations.
Dans cet article, nous examinerons de plus près PaliGemma 2, notamment son fonctionnement, ses principales caractéristiques et les applications dans lesquelles il excelle. Commençons !
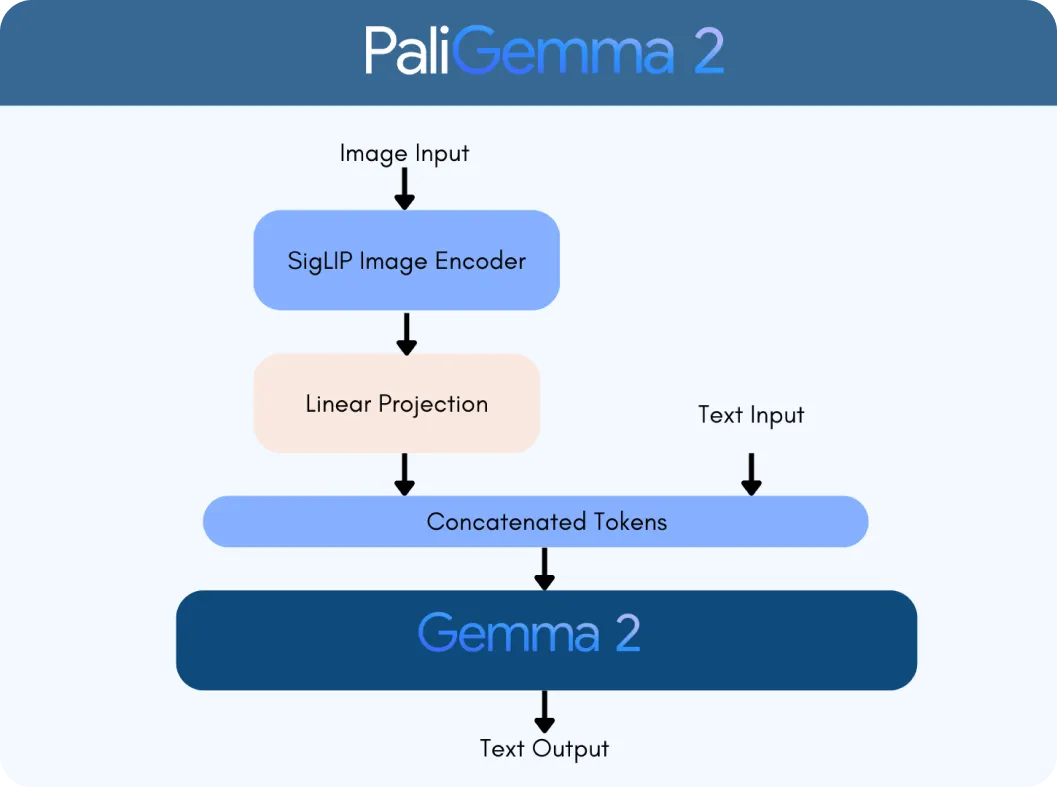
PaliGemma 2 repose sur deux technologies clés : l'encodeur de vision SigLIP et le modèle de langage Gemma 2. L'encodeur SigLIP traite les données visuelles, comme les images ou les vidéos, et les décompose en caractéristiques que le modèle peut analyser. Pendant ce temps, Gemma 2 gère le texte, permettant au modèle de comprendre et de générer un langage multilingue. Ensemble, ils forment un VLM, conçu pour interpréter et connecter de manière transparente les informations visuelles et textuelles.
Ce qui fait de PaliGemma 2 une avancée majeure, c'est son évolutivité et sa polyvalence. Contrairement à la version originale, PaliGemma 2 est disponible en trois tailles - 3 milliards (3B), 10 milliards (10B) et 28 milliards (28B) de paramètres. Ces paramètres sont comme les paramètres internes du modèle, l'aidant à apprendre et à traiter efficacement les données. Il prend également en charge différentes résolutions d'image (par exemple, 224 x 224 pixels pour les tâches rapides et 896 x 896 pour l'analyse détaillée), ce qui le rend adaptable à diverses applications.
L'intégration des capacités linguistiques avancées de Gemma 2 au traitement d'image de SigLIP rend PaliGemma 2 considérablement plus intelligent. Il peut gérer des tâches telles que :
PaliGemma 2 va au-delà du traitement séparé des images et du texte : il les rassemble de manière significative. Par exemple, il peut comprendre les relations dans une scène, comme reconnaître que « Le chat est assis sur la table », ou identifier des objets tout en ajoutant du contexte, comme reconnaître un monument célèbre.
Ensuite, nous allons passer en revue un exemple en utilisant le graphique illustré dans l'image ci-dessous pour mieux comprendre comment PaliGemma 2 traite les données visuelles et textuelles. Supposons que vous téléchargiez ce graphique et que vous demandiez au modèle : « Que représente ce graphique ? »

Le processus commence avec l'encodeur de vision SigLIP de PaliGemma 2 pour analyser les images et extraire les caractéristiques clés. Pour un graphique, il s'agit d'identifier les éléments tels que les axes, les points de données et les étiquettes. L'encodeur est formé pour capturer à la fois des modèles larges et des détails fins. Il utilise également la reconnaissance optique de caractères (OCR) pour detect et traiter tout texte intégré dans l'image. Ces caractéristiques visuelles sont converties en jetons, qui sont des représentations numériques que le modèle peut traiter. Ces jetons sont ensuite ajustés à l'aide d'une couche de projection linéaire, une technique qui permet de les combiner de manière transparente avec des données textuelles.
Parallèlement, le modèle de langage Gemma 2 traite la requête d'accompagnement pour déterminer sa signification et son intention. Le texte de la requête est converti en jetons, et ceux-ci sont combinés avec les jetons visuels de SigLIP pour créer une représentation multimodale, un format unifié qui relie les données visuelles et textuelles.
En utilisant cette représentation intégrée, PaliGemma 2 génère une réponse étape par étape grâce au décodage autorégressif, une méthode où le modèle prédit une partie de la réponse à la fois en fonction du contexte qu'il a déjà traité.
Maintenant que nous avons compris comment cela fonctionne, explorons les principales caractéristiques qui font de PaliGemma 2 un modèle de vision-langage fiable :
Examiner l'architecture de la première version de PaliGemma est un bon moyen de voir les améliorations de PaliGemma 2. L'un des changements les plus notables est le remplacement du modèle de langage Gemma original par Gemma 2, ce qui apporte des améliorations substantielles en termes de performances et d'efficacité.
Gemma 2, disponible en tailles de paramètres 9B et 27B, a été conçu pour offrir une précision et une vitesse de pointe tout en réduisant les coûts de déploiement. Il y parvient grâce à une architecture repensée, optimisée pour l'efficacité de l'inférence sur diverses configurations matérielles, des GPU puissants aux configurations plus accessibles.
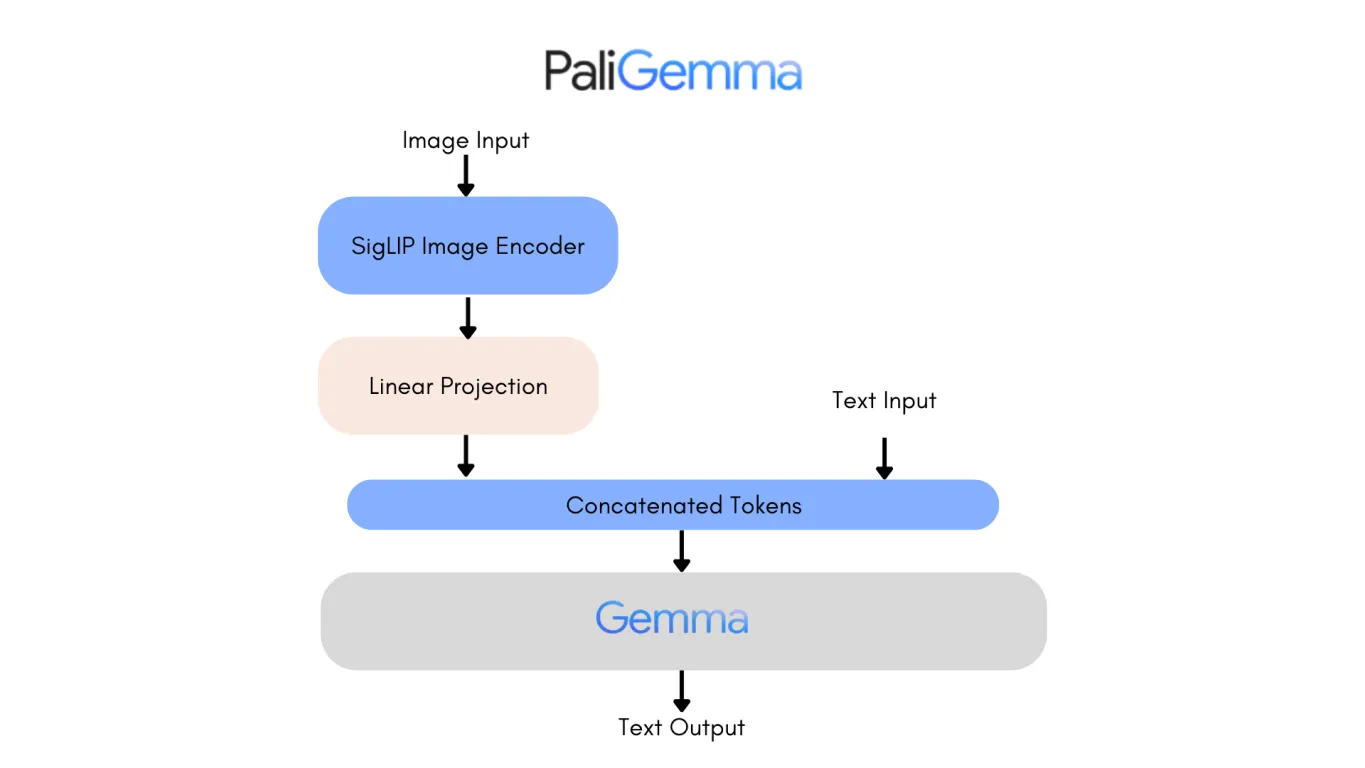
Par conséquent, PaliGemma 2 est un modèle très précis. La version 10B de PaliGemma 2 obtient un score NES (Non-Entailment Sentence) plus faible de 20,3, contre 34,3 pour le modèle original, ce qui signifie moins d'erreurs factuelles dans ses sorties. Ces avancées rendent PaliGemma 2 plus évolutif, précis et adaptable à un éventail plus large d'applications, de la légende détaillée à la réponse aux questions visuelles.
PaliGemma 2 a le potentiel de redéfinir les industries en combinant de manière transparente la compréhension visuelle et linguistique. Par exemple, en ce qui concerne l'accessibilité, il peut générer des descriptions détaillées d'objets, de scènes et de relations spatiales, fournissant une assistance cruciale aux personnes malvoyantes. Cette capacité aide les utilisateurs à mieux comprendre leur environnement, offrant une plus grande autonomie dans les tâches quotidiennes.

Outre l'accessibilité, PaliGemma 2 a un impact dans divers secteurs, notamment :
Pour essayer PaliGemma 2, vous pouvez commencer par la démo interactive de Hugging FaceElle vous permet d'explorer ses capacités dans des tâches telles que le sous-titrage d'images et la réponse à des questions visuelles. Il vous suffit de télécharger une image et de poser des questions au modèle ou de lui demander une description de la scène.
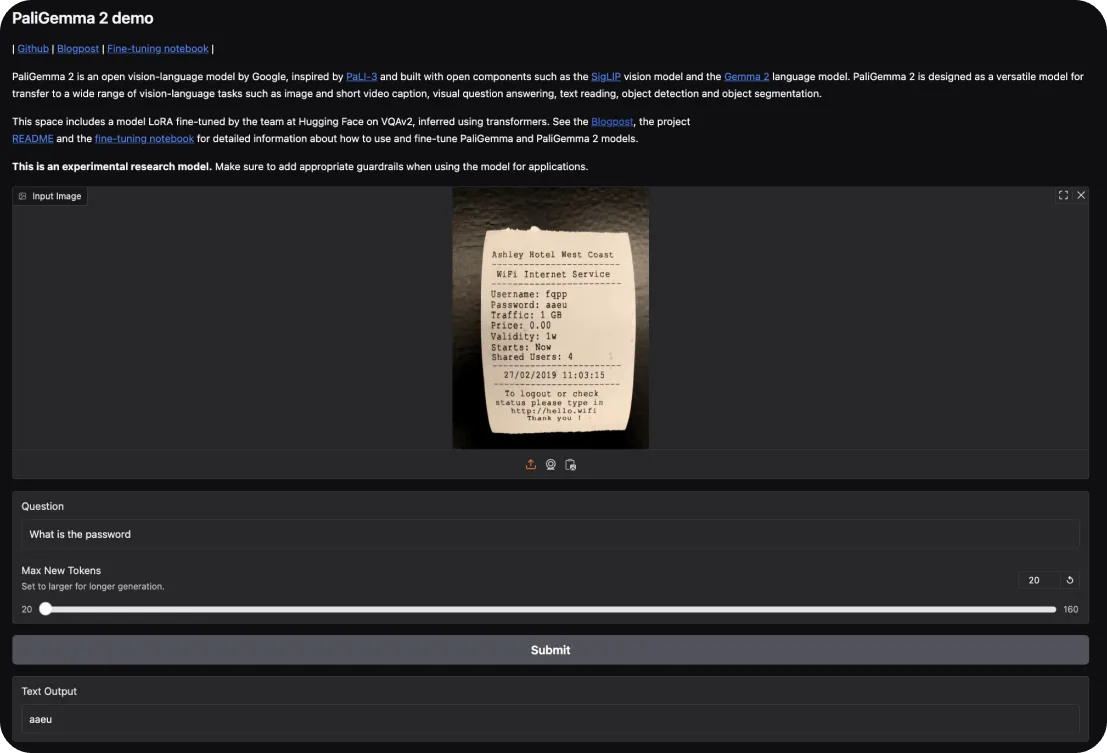
Si vous souhaitez approfondir, voici comment vous pouvez vous lancer :
Maintenant que vous avez compris comment démarrer avec PaliGemma 2, examinons de plus près ses principaux atouts et inconvénients à garder à l'esprit lors de l'utilisation de ces modèles.
Voici ce qui distingue PaliGemma 2 en tant que modèle de vision-langage :
En attendant, voici quelques domaines où PaliGemma 2 peut rencontrer des limitations :
PaliGemma 2 est une avancée fascinante dans la modélisation vision-langage, offrant une évolutivité, une flexibilité de réglage fin et une précision améliorées. Il peut servir d'outil précieux pour des applications allant des solutions d'accessibilité et du commerce électronique aux diagnostics de santé et à l'éducation.
Bien qu'il présente des limitations, telles que les exigences de calcul et la dépendance à des données de haute qualité, ses atouts en font un choix pratique pour aborder des tâches complexes qui intègrent des données visuelles et textuelles. PaliGemma 2 peut fournir une base solide aux chercheurs et aux développeurs pour explorer et étendre le potentiel de l'IA dans les applications multimodales.
Participez à la conversation sur l'IA en consultant notre dépôt GitHub et notre communauté. Découvrez comment l'IA fait des progrès dans l'agriculture et les soins de santé ! 🚀


