



Rejoignez-nous pour découvrir comment les modèles de diffusion peuvent être utilisés pour créer un contenu réaliste et redéfinir des domaines tels que le design, la musique et le cinéma avec diverses applications.

Rejoignez-nous pour découvrir comment les modèles de diffusion peuvent être utilisés pour créer un contenu réaliste et redéfinir des domaines tels que le design, la musique et le cinéma avec diverses applications.
L'utilisation d'outils d'IA générative comme Midjourney et Sora pour créer du contenu est de plus en plus courante, et l'intérêt pour l'exploration du fonctionnement interne de ces outils est croissant. En fait, une étude récente montre que 94 % des personnes sont prêtes à acquérir de nouvelles compétences pour travailler avec l'IA générative. Comprendre comment fonctionnent les modèles d'IA générative peut vous aider à utiliser ces outils plus efficacement et à en tirer le meilleur parti.
Au cœur d'outils comme Midjourney et Sora se trouvent des modèles de diffusion avancés : des modèles d'IA génératifs capables de créer des images, des vidéos, du texte et de l'audio pour diverses applications. Par exemple, les modèles de diffusion sont une excellente option pour produire de courtes vidéos marketing pour les plateformes de médias sociaux comme TikTok et YouTube Shorts. Dans cet article, nous allons explorer le fonctionnement des modèles de diffusion et où ils peuvent être utilisés. Commençons !
En physique, la diffusion est le processus par lequel les molécules se dispersent des zones de concentration plus élevée vers les zones de concentration plus faible. Le concept de diffusion est étroitement lié au mouvement brownien, où les particules se déplacent de manière aléatoire lorsqu'elles entrent en collision avec des molécules dans un fluide et se dispersent progressivement au fil du temps.
Ces concepts ont inspiré le développement de modèles de diffusion dans l'IA générative. Les modèles de diffusion fonctionnent en ajoutant progressivement du bruit aux données, puis en apprenant à inverser ce processus pour générer de nouvelles données de haute qualité comme du texte, des images ou du son. C'est similaire à l'idée de diffusion inverse en physique. Théoriquement, la diffusion peut être suivie à rebours pour ramener les particules à leur état d'origine. De la même manière, les modèles de diffusion apprennent à inverser le bruit ajouté pour créer de nouvelles données réalistes à partir d'entrées bruitées.

Généralement, l'architecture d'un modèle de diffusion comporte deux étapes principales. Tout d'abord, le modèle apprend à ajouter progressivement du bruit à l'ensemble de données. Ensuite, il est entraîné à inverser ce processus et à ramener les données à leur état d'origine. Examinons de plus près comment cela fonctionne.
Avant de nous plonger au cœur d'un modèle de diffusion, il est important de se rappeler que toutes les données sur lesquelles le modèle est entraîné doivent être prétraitées. Par exemple, si vous entraînez un modèle de diffusion pour générer des images, l'ensemble de données d'images d'entraînement doit d'abord être nettoyé. Le prétraitement des données d'image peut consister à supprimer toutes les valeurs aberrantes qui pourraient affecter les résultats, à normaliser les valeurs des pixels afin que toutes les images soient à la même échelle et à utiliser l'augmentation des données pour introduire plus de variété. Les étapes de prétraitement des données aident à garantir la qualité des données d'entraînement, et cela est vrai non seulement pour les modèles de diffusion, mais aussi pour tout modèle d'IA.
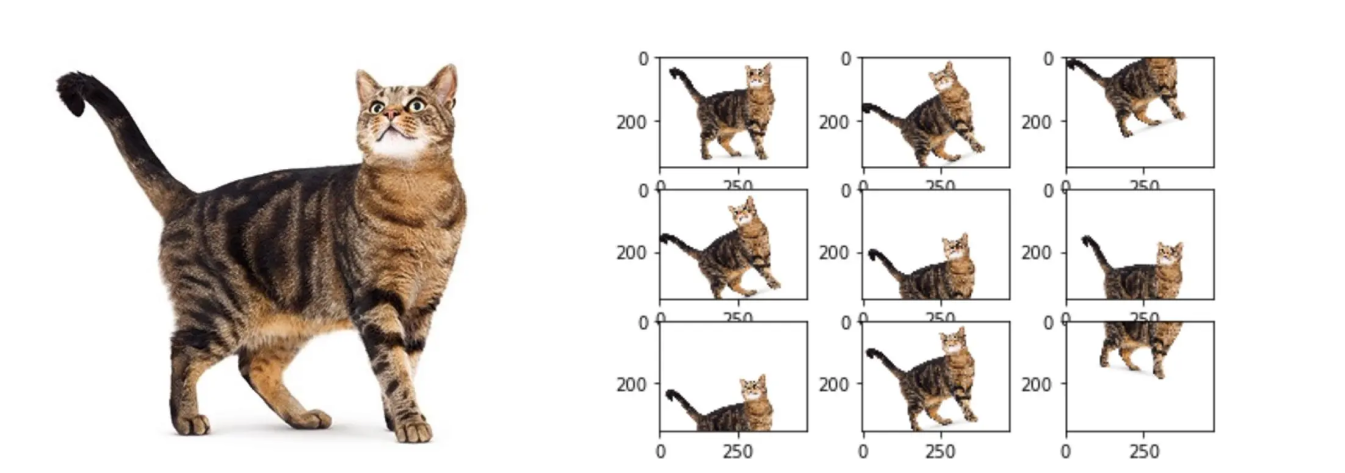
Après le prétraitement des données, l'étape suivante est le processus de diffusion directe. Concentrons-nous sur l'entraînement d'un modèle de diffusion pour générer des images. Le processus commence par un échantillonnage à partir d'une distribution simple, comme une distribution gaussienne. En d'autres termes, un bruit aléatoire est sélectionné. Comme le montre l'image ci-dessous, le modèle transforme progressivement l'image en une série d'étapes. L'image commence de manière claire et devient de plus en plus bruitée à mesure qu'elle progresse à chaque étape, pour finalement se transformer en un bruit presque complet à la fin.

Chaque étape s'appuie sur la précédente, et le bruit est ajouté de manière contrôlée et progressive à l'aide d'une chaîne de Markov. Une chaîne de Markov est un modèle mathématique dans lequel la probabilité de l'état suivant dépend uniquement de l'état actuel. Elle est utilisée pour prédire les résultats futurs en fonction des conditions actuelles. Au fur et à mesure que chaque étape ajoute de la complexité aux données, nous pouvons capturer les motifs et les détails les plus complexes de la distribution originale des données d'image. L'ajout de bruit gaussien génère également des échantillons divers et réalistes au fur et à mesure que la diffusion se déroule.
Le processus de diffusion inverse commence une fois que le processus de diffusion directe a transformé un échantillon en un état bruyant et complexe. Il remet progressivement l'échantillon bruyant dans son état d'origine en utilisant une série de transformations inverses. Les étapes qui inversent le processus d'ajout de bruit sont guidées par une chaîne de Markov inverse.
.png)
Pendant le processus inverse, les modèles de diffusion apprennent à générer de nouvelles données en partant d'un échantillon de bruit aléatoire et en l'affinant progressivement en une sortie claire et détaillée. Les données générées finissent par ressembler étroitement à l'ensemble de données original. Cette capacité est ce qui rend les modèles de diffusion excellents pour des tâches telles que la synthèse d'images, la complétion de données et la suppression du bruit. Dans la section suivante, nous explorerons d'autres applications des modèles de diffusion.
Le processus de diffusion étape par étape permet au modèle de diffusion de générer efficacement des distributions de données complexes sans être submergé par la haute dimensionnalité des données. Examinons quelques applications où les modèles de diffusion excellent.
Les modèles de diffusion peuvent être utilisés pour générer rapidement du contenu visuel graphique. Les concepteurs et les artistes peuvent fournir des croquis, des mises en page ou même quelques idées brutes de ce qu'ils veulent, et les modèles peuvent donner vie à ces idées. Cela peut accélérer l'ensemble du processus de conception, offrir un large éventail de nouvelles possibilités, du concept initial au produit final, et faire gagner beaucoup de temps précieux aux concepteurs.

Les modèles de diffusion peuvent également être adaptés pour générer des paysages sonores ou des notes de musique très uniques. Ils offrent de nouvelles façons pour les musiciens et les artistes de visualiser et de créer des expériences auditives. Voici quelques exemples d'utilisation des modèles de diffusion dans le domaine de la création sonore et musicale :
Un autre cas d'utilisation intéressant des modèles de diffusion est la création de clips de films et d'animation. Ils peuvent être utilisés pour générer des personnages, des arrière-plans réalistes et même des éléments dynamiques dans les scènes. L'utilisation de modèles de diffusion peut être un avantage considérable pour les sociétés de production. Elle rationalise le flux de travail global et ouvre la voie à plus d'expérimentation et de créativité dans la narration visuelle. Certains des clips réalisés à l'aide de ces modèles sont comparables à de véritables clips animés ou de films. Il est même possible d'utiliser ces modèles pour créer des films entiers.

Maintenant que nous avons découvert certaines des applications des modèles de diffusion, examinons quelques modèles de diffusion populaires que vous pouvez essayer d'utiliser.
Bien que les modèles de diffusion offrent des avantages dans de nombreux secteurs, il convient de garder à l'esprit certains défis qu'ils posent. L'un de ces défis est que le processus d'entraînement est très gourmand en ressources. Bien que les avancées en matière d'accélération matérielle puissent aider, elles peuvent être coûteuses. Un autre problème est la capacité limitée des modèles de diffusion à se généraliser à des données non vues. Leur adaptation à des domaines spécifiques peut nécessiter beaucoup de mise au point ou de réentraînement.
L'intégration de ces modèles dans des tâches du monde réel comporte son propre ensemble de défis. Il est essentiel que ce que l'IA génère corresponde réellement à ce que les humains attendent. Il existe également des préoccupations éthiques, comme le risque que ces modèles reprennent et reflètent les biais des données sur lesquelles ils sont entraînés. De plus, la gestion des attentes des utilisateurs et l'amélioration constante des modèles en fonction des commentaires peuvent devenir un effort continu pour s'assurer que ces outils sont aussi efficaces et fiables que possible.
Les modèles de diffusion sont un concept fascinant de l'IA générative qui aide à créer des images, des vidéos et des sons de haute qualité dans de nombreux domaines différents. Bien qu'ils puissent présenter certains défis de mise en œuvre, comme les exigences de calcul et les préoccupations éthiques, la communauté de l'IA travaille constamment à améliorer leur efficacité et leur impact. Les modèles de diffusion sont sur le point de transformer des industries comme le cinéma, la production musicale et la création de contenu numérique à mesure qu'ils continuent d'évoluer.
Apprenons et explorons ensemble ! Consultez notre dépôt GitHub pour voir nos contributions à l'IA. Découvrez comment nous redéfinissons des industries comme la fabrication et les soins de santé grâce à une technologie d'IA de pointe.


