


Explorando o cartão do modelo Claude 3: o que significa para a visão de IA

Descubra o model card do Claude 3 e seu impacto no desenvolvimento da Visão de IA.

Descubra o model card do Claude 3 e seu impacto no desenvolvimento da Visão de IA.
Nos últimos anos, a Visão de IA tem feito progressos significativos, revolucionando vários setores, desde a assistência médica até o varejo. Compreender os modelos subjacentes e sua documentação é crucial para aproveitar esses avanços de forma eficaz. Uma ferramenta essencial no arsenal do desenvolvedor de Inteligência Artificial (IA) é o cartão de modelo, que oferece uma visão geral abrangente das características e do desempenho de um modelo de IA.
Neste artigo, vamos explorar o modelo de cartão Claude 3, desenvolvido pela Anthropic, e as suas implicações para o desenvolvimento da IA de visão. O Claude 3 é uma nova família de modelos multimodais de grande dimensão, composta por três variantes: Claude 3 Opus, o modelo mais capaz; Claude 3 Sonnet, que equilibra desempenho e velocidade; e Claude 3 Haiku, a opção mais rápida e económica. Cada modelo foi recentemente equipado com capacidades de visão, permitindo-lhes processar e analisar dados de imagem.
O que exatamente é um model card? Um model card é um documento detalhado que fornece insights sobre o desenvolvimento, treinamento e avaliação de um modelo de machine learning. Ele visa promover a transparência, a responsabilidade e o uso ético da IA, apresentando informações claras sobre a funcionalidade do modelo, os casos de uso pretendidos e as limitações potenciais. Isso pode ser alcançado fornecendo dados mais detalhados sobre o modelo, como suas métricas de avaliação e sua comparação com modelos anteriores e outros concorrentes.
As métricas de avaliação são cruciais para avaliar o desempenho do modelo. O card do modelo Claude 3 lista métricas como acurácia, precisão, recall e F1-score, fornecendo uma imagem clara dos pontos fortes e áreas para melhoria do modelo. Essas métricas são comparadas com os padrões da indústria, mostrando o desempenho competitivo do Claude 3.
Além disso, o Claude 3 se baseia nos pontos fortes de seus antecessores, incorporando avanços em arquitetura e técnicas de treinamento. O model card compara o Claude 3 com versões anteriores, destacando melhorias em precisão, eficiência e aplicabilidade a novos casos de uso.
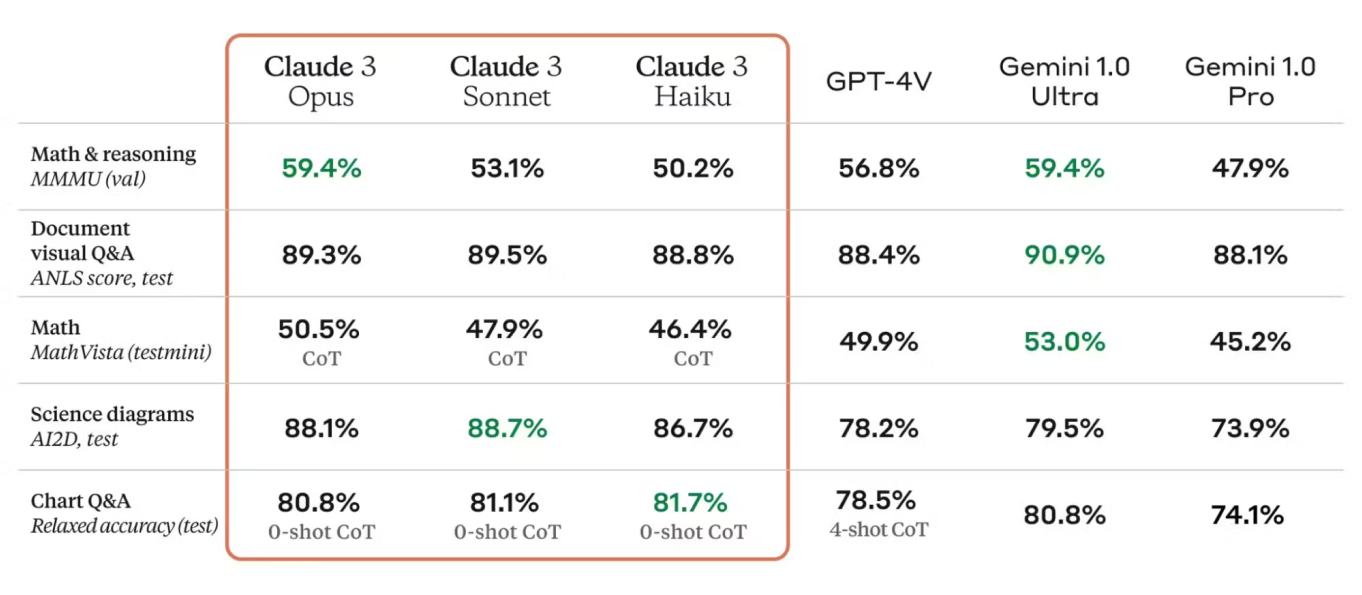
A arquitetura e o processo de treinamento do Claude 3 resultam em um desempenho confiável em várias tarefas de Processamento de Linguagem Natural (NLP) e visuais. Ele consistentemente alcança resultados fortes em benchmarks, demonstrando sua capacidade de realizar análises de linguagem complexas de forma eficaz.
O treinamento do Claude 3 em diversos conjuntos de dados e o uso de técnicas de aumento de dados garantem sua robustez e capacidade de generalizar em diferentes cenários. Isso torna o modelo versátil e eficaz em uma ampla gama de aplicações.
Embora os seus resultados sejam dignos de nota, o Claude 3 é fundamentalmente um modelo de linguagem grande (LLM). Embora os LLMs como o Claude 3 possam executar várias tarefas de visão computacional, não foram especificamente concebidos para tarefas como a deteção de objectos, a criação de caixas de limites e a segmentação de imagens. Como resultado, a sua precisão nestas áreas pode não corresponder à de modelos especificamente concebidos para a visão por computador, como o Ultralytics YOLOv8. No entanto, os LLMs destacam-se noutros domínios, nomeadamente no Processamento de Linguagem Natural (PLN), onde Claude 3 demonstra uma força significativa ao fundir tarefas visuais simples com raciocínio humano.

As capacidades de PNL referem-se à capacidade de um modelo de IA entender e responder à linguagem humana. Essa capacidade é amplamente utilizada nas aplicações do Claude 3 no campo visual, permitindo que ele forneça descrições contextualmente ricas, interprete dados visuais complexos e melhore o desempenho geral em tarefas de Visão de IA.
Uma das capacidades impressionantes do Claude 3, especialmente quando aproveitado para tarefas de Visão de IA, é sua capacidade de processar e converter imagens de baixa qualidade com caligrafia difícil de ler em texto. Este recurso demonstra o poder de processamento avançado do modelo e as habilidades de raciocínio multimodal. Nesta seção, exploraremos como o Claude 3 realiza esta tarefa, destacando os mecanismos subjacentes e as implicações para o desenvolvimento de Visão de IA.
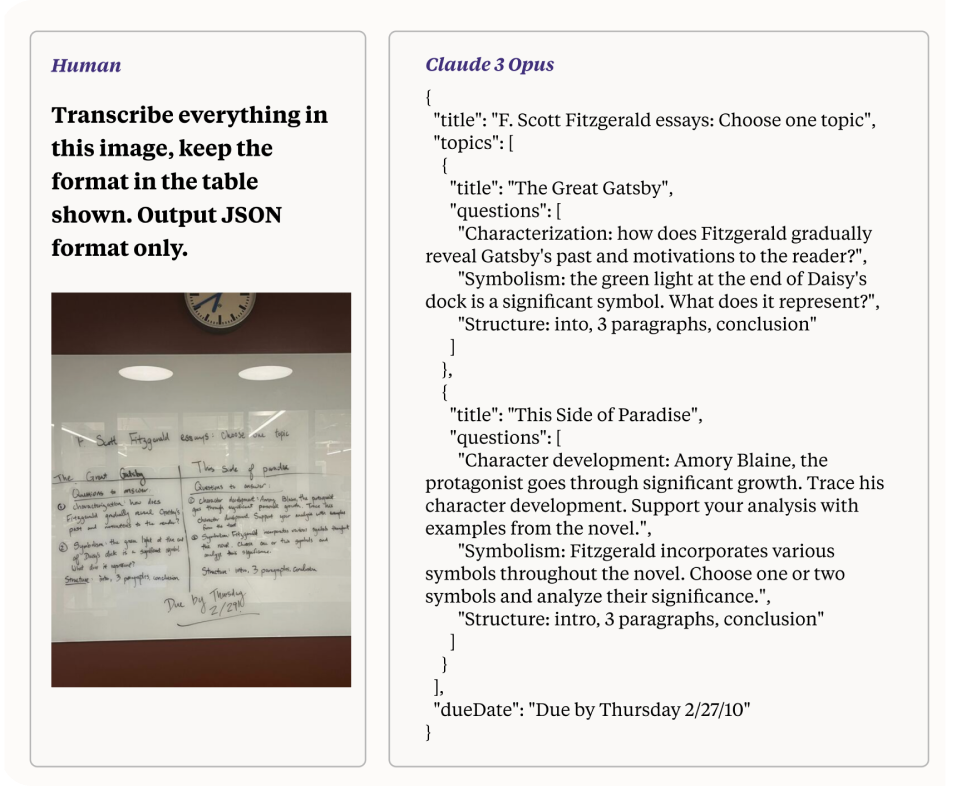
Converter uma foto de baixa qualidade com caligrafia difícil de ler em texto é uma tarefa complexa que envolve vários desafios:
Como mencionado anteriormente, os modelos Claude 3 abordam esses desafios através de uma combinação de técnicas avançadas em visão computacional e processamento de linguagem natural (PNL).
A arquitetura do Claude 3 permite que ele execute tarefas de raciocínio complexas usando entradas visuais. Por exemplo, como mostrado na Figura 1, o modelo pode interpretar gráficos e diagramas, como identificar países do G7 em um gráfico sobre o uso da internet, extrair dados relevantes e realizar cálculos para analisar tendências. Esse raciocínio de várias etapas, como calcular diferenças estatísticas no uso da internet entre grupos etários, aprimora a precisão e a utilidade do modelo em aplicações do mundo real.

O Claude 3 se destaca na transformação de imagens em descrições detalhadas, mostrando suas poderosas capacidades tanto em visão computacional quanto em processamento de linguagem natural. Ao receber uma imagem, o Claude 3 primeiro emprega redes neurais convolucionais (CNNs) para extrair características-chave e identificar objetos, padrões e elementos contextuais dentro dos dados visuais.
Em seguida, as camadas transformer analisam essas características, aproveitando os mecanismos de atenção para entender as relações e o contexto entre diferentes elementos da imagem. Essa abordagem multimodal permite que o Claude 3 gere descrições precisas e contextualmente ricas, não apenas identificando objetos, mas também compreendendo suas interações e significado dentro da cena.

Os modelos de grande linguagem (LLM), como o Claude 3, destacam-se no processamento de linguagem natural e não na visão computacional. Embora possam descrever imagens, tarefas como a deteção de objectos e a segmentação de imagens são melhor tratadas por modelos orientados para a visão, como o YOLOv8. Estes modelos especializados são optimizados para tarefas visuais e proporcionam um melhor desempenho na análise de imagens. Além disso, o modelo não pode executar tarefas como a criação de caixas delimitadoras.
Combinar o Claude 3 com sistemas de visão computacional pode ser complexo e pode exigir etapas de processamento adicionais para preencher a lacuna entre texto e dados visuais.
O Claude 3 é treinado principalmente em vastas quantidades de dados textuais, o que significa que ele carece dos extensos conjuntos de dados visuais necessários para alcançar alto desempenho em tarefas de visão computacional. Como resultado, embora o Claude 3 se destaque na compreensão e geração de texto, ele não tem a capacidade de processar ou analisar imagens com o mesmo nível de proficiência encontrado em modelos especificamente projetados para dados visuais. Essa limitação o torna menos eficaz para aplicações que exigem a interpretação ou geração de conteúdo visual.
Semelhante a outros modelos de linguagem grandes, o Claude 3 está definido para melhoria contínua. Aprimoramentos futuros provavelmente se concentrarão em melhores tarefas visuais, como detecção de imagem e reconhecimento de objetos, bem como avanços em tarefas de processamento de linguagem natural. Isso permitirá descrições mais precisas e detalhadas de objetos e cenas, entre outras tarefas semelhantes.
Por fim, a pesquisa contínua sobre o Claude 3 priorizará o aprimoramento da interpretabilidade, a redução do viés e a melhoria da generalização em diversos conjuntos de dados. Esses esforços garantirão o desempenho robusto do modelo em várias aplicações e promoverão a confiança e a confiabilidade em seus resultados.
O card do modelo Claude 3 é um recurso valioso para desenvolvedores e stakeholders em Visão de IA, fornecendo insights detalhados sobre a arquitetura, desempenho e considerações éticas do modelo. Ao promover a transparência e a responsabilidade, ajuda a garantir o uso responsável e eficaz das tecnologias de IA. À medida que a Visão de IA continua a evoluir, o papel dos cards de modelo como o de Claude 3 será crucial para orientar o desenvolvimento e promover a confiança nos sistemas de IA.
Na Ultralytics, somos apaixonados pelo avanço da tecnologia de IA. Para explorar nossas soluções de IA e manter-se atualizado com nossas inovações mais recentes, visite nosso repositório GitHub. Junte-se à nossa comunidade no Discord e descubra como estamos transformando indústrias como carros autônomos e manufatura! 🚀


