Ao clicar em “Aceitar todos os cookies”, concorda com o armazenamento de cookies no seu dispositivo para melhorar a navegação no site, analisar a utilização do site e ajudar nos nossos esforços de marketing. Mais informações
Definições de cookies
Ao clicar em “Aceitar todos os cookies”, concorda com o armazenamento de cookies no seu dispositivo para melhorar a navegação no site, analisar a utilização do site e ajudar nos nossos esforços de marketing. Mais informações
Explore a nova família de modelos de código aberto Llama 3.1 da Meta, apresentando o versátil 8B, o completo 70B e o carro-chefe 405B, seu maior e mais avançado modelo até o momento.
Em 23 de julho de 2024, a Meta lançou a nova família de modelos de código aberto Llama 3.1, apresentando os modelos versátil 8B, o capaz 70B e o Llama 3.1 405B, com o último se destacando como o maior modelo de linguagem grande (LLM) de código aberto até o momento.
Você deve estar se perguntando o que diferencia esses novos modelos de seus antecessores. Bem, ao nos aprofundarmos neste artigo, você descobrirá que o lançamento dos modelos Llama 3.1 marca um marco significativo na tecnologia de IA. Os modelos recém-lançados oferecem melhorias significativas no processamento de linguagem natural; além disso, eles introduzem novos recursos e aprimoramentos não encontrados em versões anteriores. Este lançamento promete mudar a forma como aproveitamos a IA para tarefas complexas, fornecendo um poderoso conjunto de ferramentas para pesquisadores e desenvolvedores.
Neste artigo, exploraremos a família de modelos Llama 3.1, investigando sua arquitetura, principais melhorias, usos práticos e uma comparação detalhada de seu desempenho.
O que é o Llama 3.1?
O mais recente modelo de linguagem de grande dimensão da Meta, o Llama 3.1, está a dar passos significativos no panorama da IA, rivalizando com as capacidades de modelos de topo como o Chat GPT-4o da OpenAI e o Claude 3.5 Sonnet da Anthropic.
Mesmo que possa ser considerado uma atualização menor do modelo Llama 3 anterior, a Meta deu mais um passo à frente ao introduzir algumas melhorias importantes na nova família de modelos, oferecendo:
Suporte a oito idiomas: Incluindo English, alemão, francês, italiano, português, hindi, espanhol e tailandês, expandindo seu alcance para um público global.
128.000 tokens de janela de contexto: Permitindo que os modelos lidem com entradas muito mais longas e mantenham o contexto em conversas ou documentos estendidos.
Melhores capacidades de raciocínio: Permitindo que os modelos sejam mais versáteis e capazes de gerenciar tarefas complexas de forma eficaz.
Segurança rigorosa: Testes foram implementados para mitigar riscos, reduzir preconceitos e evitar saídas prejudiciais, promovendo o uso responsável da IA.
Para além de tudo o que foi referido, a nova família de modelos Llama 3.1 destaca um grande avanço com o seu impressionante modelo de 405 mil milhões de parâmetros. Este número substancial de parâmetros representa um salto significativo no desenvolvimento da IA, melhorando consideravelmente a capacidade do modelo para compreender e gerar texto complexo. O modelo 405B inclui um vasto conjunto de parâmetros, sendo que cada parâmetro se refere aos weights and biases às weights and biases da rede neural que o modelo aprende durante o treino. Isto permite que o modelo capte padrões linguísticos mais complexos, estabelecendo um novo padrão para modelos linguísticos de grande dimensão e demonstrando o potencial futuro da tecnologia de IA. Este modelo de grande escala não só melhora o desempenho numa vasta gama de tarefas, como também alarga os limites do que a IA pode alcançar em termos de geração e compreensão de texto.
Arquitetura do modelo
O Llama 3.1 aproveita a arquitetura de modelo transformer somente decodificador, uma pedra angular para modelos de linguagem grandes modernos. Esta arquitetura é conhecida por sua eficiência e eficácia no tratamento de tarefas de linguagem complexas. O uso de transformers permite que o Llama 3.1 se destaque na compreensão e geração de texto semelhante ao humano, proporcionando uma vantagem significativa sobre modelos que usam arquiteturas mais antigas, como LSTMs e GRUs.
Além disso, a família de modelos Llama 3.1 utiliza a arquitetura Mixture of Experts (MoE), que aumenta a eficiência e a estabilidade do treinamento. Evitar a arquitetura MoE garante um processo de treinamento mais consistente e confiável, pois o MoE às vezes pode introduzir complexidades que podem impactar a estabilidade e o desempenho do modelo.
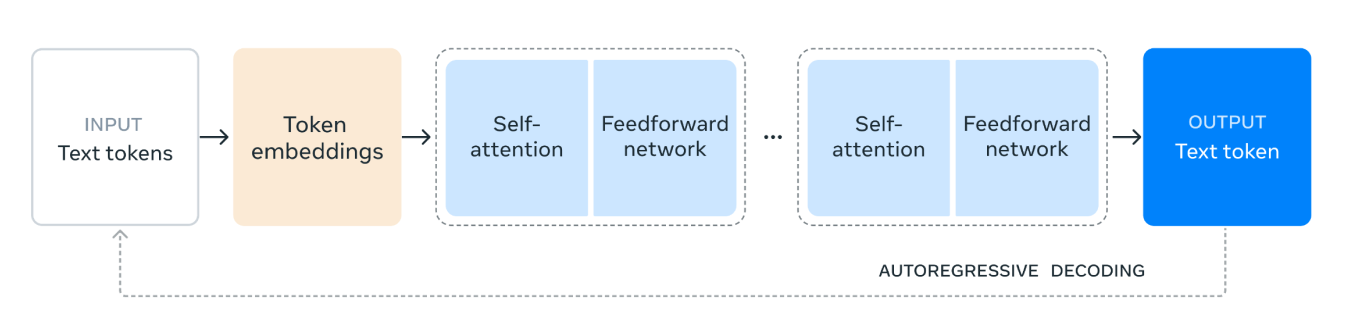
Fig 1. Um diagrama ilustrando a arquitetura do modelo transformer Llama 3.1.
A arquitetura do modelo Llama 3.1 funciona da seguinte forma:
1. Tokens de texto de entrada: O processo começa com a entrada, consistindo em tokens de texto. Esses tokens são unidades individuais de texto, como palavras ou subpalavras, que o modelo processará.
2. Incorporações de tokens: Os tokens de texto são então convertidos em incorporações de tokens. As incorporações são representações vetoriais densas dos tokens que capturam seu significado semântico e relacionamentos dentro do texto. Essa transformação é crucial, pois permite que o modelo trabalhe com dados numéricos.
3. Mecanismo de autoatenção: A autoatenção permite que o modelo pondere a importância de diferentes tokens na sequência de entrada ao codificar cada token. Este mecanismo ajuda o modelo a entender o contexto e as relações entre os tokens, independentemente de suas posições na sequência. No mecanismo de autoatenção, cada token na sequência de entrada é representado como um vetor de números. Esses vetores são usados para criar três tipos diferentes de representações: consultas, chaves e valores.
O modelo calcula quanta atenção cada token deve dar a outros tokens, comparando os vetores de consulta com os vetores de chave. Esta comparação resulta em pontuações que indicam a relevância de cada token em relação aos outros.
4. Rede de alimentação: Após o processo de auto-atenção, os dados passam por uma rede feedforward. Esta rede é uma rede neural totalmente conectada que aplica transformações não lineares aos dados, ajudando o modelo a reconhecer e aprender padrões complexos.
5. Camadas Repetidas: As camadas de autoatenção e rede feedforward são empilhadas várias vezes. Essa aplicação repetida permite que o modelo capture dependências e padrões mais complexos nos dados.
6. Token de Texto de Saída: Finalmente, os dados processados são usados para gerar o token de texto de saída. Este token é a previsão do modelo para a próxima palavra ou subpalavra na sequência, com base no contexto de entrada.
Desempenho e comparações do modelo da família LLama 3.1 com outros modelos
Testes de benchmark revelam que o Llama 3.1 não apenas se mantém competitivo em relação a esses modelos de última geração, mas também os supera em certas tarefas, demonstrando seu desempenho superior.
Llama 3.1 405B: Alta capacidade
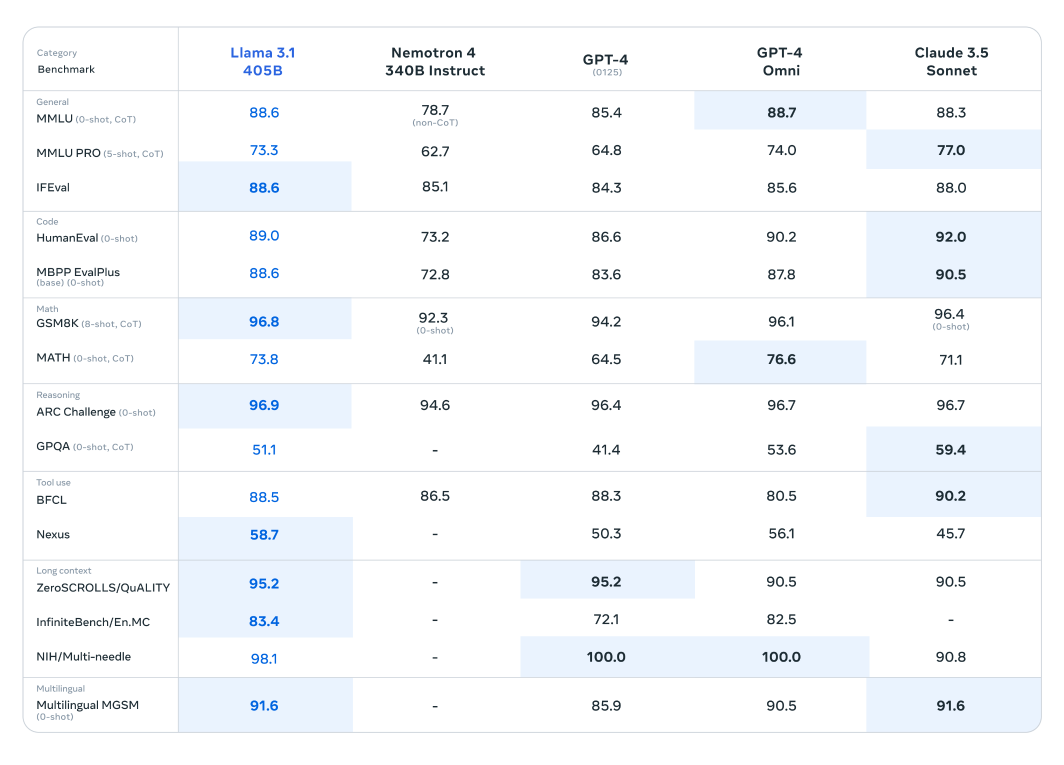
O modelo Llama 3.1 passou por uma extensa avaliação em mais de 150 conjuntos de dados de benchmark, onde foi rigorosamente comparado a outros modelos de linguagem grandes líderes. O modelo Llama 3.1 405B, reconhecido como o mais capaz da série recém-lançada, foi comparado com titãs da indústria como o GPT-4 da OpenAI e o Claude 3.5 Sonnet. Os resultados dessas comparações revelam que o Llama 3.1 demonstra uma vantagem competitiva, mostrando seu desempenho e capacidades superiores em várias tarefas.
Fig 2. Uma tabela comparando o desempenho do modelo Llama 3.1 405B com modelos semelhantes.
A impressionante contagem de parâmetros e a arquitetura avançada deste modelo permitem que ele se destaque na compreensão complexa e na geração de texto, muitas vezes superando seus concorrentes em benchmarks específicos. Essas avaliações destacam o potencial do Llama 3.1 para estabelecer novos padrões no campo de modelos de linguagem grandes, fornecendo aos pesquisadores e desenvolvedores uma ferramenta poderosa para diversas aplicações.
Llama 3.1 70B: Gama média
Os modelos Llama menores e mais leves também demonstram um desempenho notável quando comparados aos seus equivalentes. O modelo Llama 3.1 70B foi avaliado em relação a modelos maiores, como o Mistral 8x22B e o GPT-3.5 Turbo. Por exemplo, o modelo Llama 3.1 70B demonstra consistentemente um desempenho superior em conjuntos de dados de raciocínio, como o conjunto de dados ARC Challenge, e em conjuntos de dados de codificação, como os conjuntos de dados HumanEval. Esses resultados destacam a versatilidade e a robustez da série Llama 3.1 em diferentes tamanhos de modelo, tornando-o uma ferramenta valiosa para uma ampla gama de aplicações.
Llama 3.1 8B: Leve
Além disso, o modelo Llama 3.1 8B foi comparado com modelos de tamanho semelhante, incluindo o Gemma 2 9B e o Mistral 7B. Essas comparações revelam que o modelo Llama 3.1 8B supera seus concorrentes em vários conjuntos de dados de benchmark em diferentes gêneros, como o conjunto de dados GPQA para raciocínio e o MBPP EvalPlus para codificação, mostrando sua eficiência e capacidade, apesar de sua menor contagem de parâmetros.
Fig 3. Uma tabela comparando o desempenho dos modelos Llama 3.1 70B e 8B com modelos semelhantes.
Como você pode se beneficiar dos modelos da família Llama 3.1?
A Meta permitiu que os novos modelos fossem aplicados de várias maneiras práticas e benéficas para os usuários:
Ajuste Fino
Os usuários agora podem ajustar os modelos Llama 3.1 mais recentes para casos de uso específicos. Este processo envolve treinar o modelo em novos dados externos aos quais ele não foi exposto anteriormente, melhorando assim seu desempenho e adaptabilidade para aplicações direcionadas. O ajuste fino oferece ao modelo uma vantagem significativa, permitindo que ele entenda e gere melhor o conteúdo relevante para domínios ou tarefas específicos.
Integração em um sistema RAG
Os modelos Llama 3.1 agora podem ser integrados perfeitamente em sistemas de Geração Aumentada por Recuperação (RAG). Essa integração permite que o modelo aproveite fontes de dados externas dinamicamente, melhorando sua capacidade de fornecer respostas precisas e contextualmente relevantes. Ao recuperar informações de grandes conjuntos de dados e incorporá-las ao processo de geração, o Llama 3.1 melhora significativamente seu desempenho em tarefas intensivas em conhecimento, oferecendo aos usuários resultados mais precisos e informados.
Geração de dados sintéticos
Você também pode utilizar o modelo de 405 bilhões de parâmetros para gerar dados sintéticos de alta qualidade, melhorando o desempenho de modelos especializados para casos de uso específicos. Esta abordagem aproveita as extensas capacidades do Llama 3.1 para produzir dados direcionados e relevantes, melhorando assim a precisão e a eficiência de aplicações de IA personalizadas.
As conclusões
O lançamento do Llama 3.1 representa um avanço significativo no campo de modelos de linguagem grandes, mostrando o compromisso da Meta em promover a tecnologia de IA.
Com sua contagem substancial de parâmetros, treinamento extensivo em diversos conjuntos de dados e foco em processos de treinamento robustos e estáveis, o Llama 3.1 estabelece novos benchmarks para desempenho e capacidade no processamento de linguagem natural. Seja na geração de texto, sumarização ou tarefas conversacionais complexas, o Llama 3.1 demonstra uma vantagem competitiva sobre outros modelos líderes. Este modelo não apenas ultrapassa os limites do que a IA pode alcançar hoje, mas também prepara o terreno para futuras inovações no cenário em constante evolução da inteligência artificial.
Na Ultralytics, dedicamo-nos a ultrapassar os limites da tecnologia de IA. Para explorar nossas soluções de IA de ponta e acompanhar nossas inovações mais recentes, confira nosso repositório do GitHub. Junte-se à nossa vibrante comunidade no Discord e veja como estamos revolucionando setores como carros autônomos e manufatura! 🚀