



تم إصدار Llama 3 من Meta مؤخرًا وقوبل بحماس كبير من مجتمع الذكاء الاصطناعي. لنتعرف على المزيد حول Llama 3 - أحدث التطورات في Meta AI.

تم إصدار Llama 3 من Meta مؤخرًا وقوبل بحماس كبير من مجتمع الذكاء الاصطناعي. لنتعرف على المزيد حول Llama 3 - أحدث التطورات في Meta AI.
عندما جمعنا ابتكارات الذكاء الاصطناعي (AI) للربع الأول من عام 2024، رأينا أن LLMs، أو نماذج اللغة الكبيرة، كانت يتم إصدارها يمينًا ويسارًا من قبل منظمات مختلفة. واستمرارًا لهذا الاتجاه، في 18 أبريل 2024، أصدرت Meta Llama 3، وهو جيل جديد من أحدث نماذج LLM مفتوحة المصدر.
قد تفكر: إنه مجرد نموذج LLM آخر. لماذا مجتمع الذكاء الاصطناعي متحمس جدًا بشأنه؟
في حين أنه يمكنك ضبط النماذج مثل GPT-3 أو Gemini للحصول على استجابات مخصصة، إلا أنها لا توفر شفافية كاملة فيما يتعلق بأعمالها الداخلية، مثل بيانات التدريب أو معلمات النموذج أو الخوارزميات. في المقابل، فإن Llama 3 من Meta أكثر شفافية، حيث تتوفر بنيته وأوزانه للتنزيل. بالنسبة لمجتمع الذكاء الاصطناعي، هذا يعني حرية أكبر في التجربة.
في هذه المقالة، سنتعلم ما يمكن أن يفعله Llama 3، وكيف نشأ، وتأثيره على مجال الذكاء الاصطناعي. هيا بنا نبدأ!
قبل أن نتعمق في Llama 3، دعنا نلقي نظرة على الإصدارات السابقة.
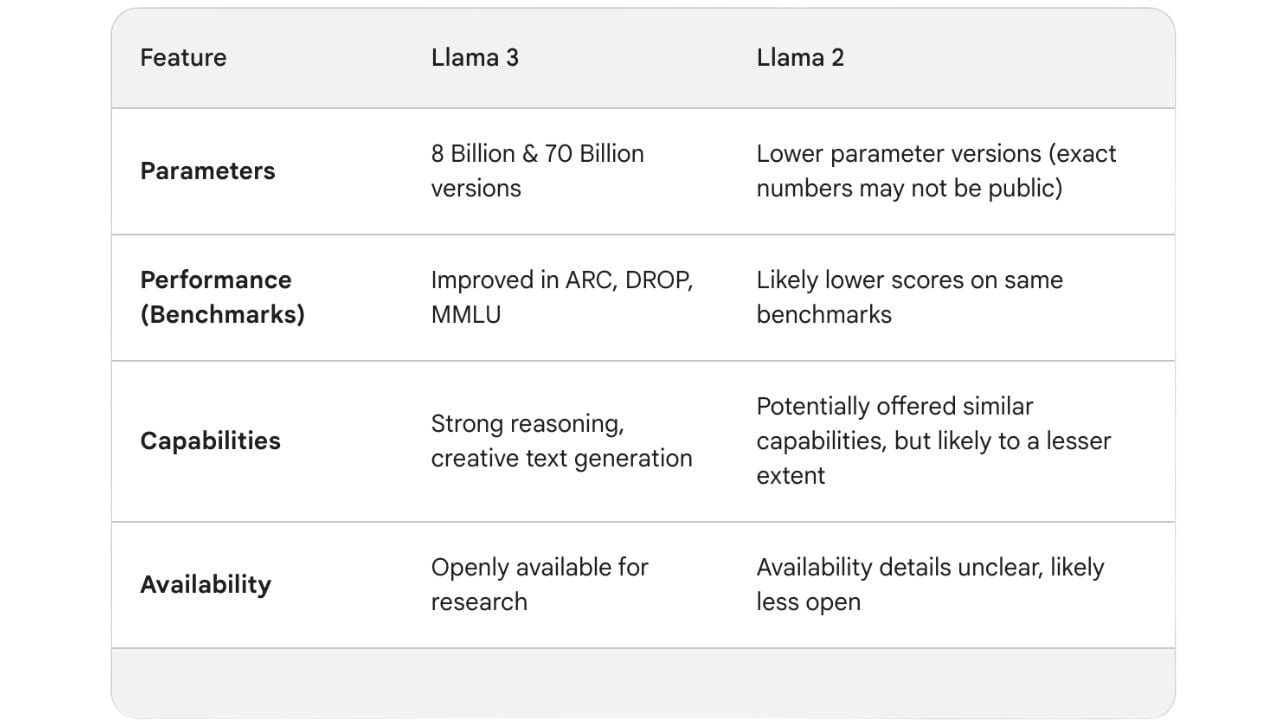
أطلقت Meta Llama 1 في فبراير 2023، والتي جاءت في أربعة متغيرات بمعلمات تتراوح من 7 مليارات إلى 64 مليار. في التعلم الآلي، تشير "المعلمات" إلى عناصر النموذج التي يتم تعلمها من بيانات التدريب. نظرًا لعدد المعلمات الأصغر، واجه Llama 1 أحيانًا صعوبة في الفهم الدقيق وقدم استجابات غير متسقة.
بعد فترة وجيزة من Llama 1، أطلقت Meta Llama 2 في يوليو 2023. تم تدريبه على 2 تريليون رمز. يمثل الرمز جزءًا من النص، مثل كلمة أو جزء من كلمة، يستخدم كوحدة بيانات أساسية للمعالجة في النموذج. كما تضمن النموذج تحسينات مثل مضاعفة نافذة السياق لتصل إلى 4096 رمزًا لفهم المقاطع الأطول وأكثر من مليون تعليق توضيحي بشري لتقليل الأخطاء. على الرغم من هذه التحسينات، كان Llama 2 لا يزال بحاجة إلى الكثير من قوة الحوسبة، وهو ما هدفت Meta إلى إصلاحه باستخدام Llama 3.
يأتي Llama 3 بأربعة متغيرات تم تدريبها على 15 تريليون رمز مذهل. أكثر من 5٪ من بيانات التدريب هذه (حوالي 800 مليون رمز) تمثل بيانات بـ 30 لغة مختلفة. يمكن تشغيل جميع متغيرات Llama 3 على أنواع مختلفة من أجهزة المستهلكين ولها طول سياق يبلغ 8 آلاف رمز.

تأتي متغيرات النموذج بحجمين: 8B و 70B، مما يشير إلى 8 مليارات و 70 مليار معلمة، على التوالي. هناك أيضًا إصداران، أساسي وتعليمي. تشير كلمة "أساسي" إلى الإصدار القياسي المدرب مسبقًا. "تعليمي" هو إصدار مضبوط بدقة ومُحسَّن لتطبيقات أو مجالات معينة من خلال تدريب إضافي على البيانات ذات الصلة.
هذه هي متغيرات نموذج Llama 3:
كما هو الحال مع أي تطورات أخرى في Meta AI، تم وضع تدابير صارمة لمراقبة الجودة للحفاظ على سلامة البيانات وتقليل التحيزات أثناء تطوير Llama 3. لذلك، المنتج النهائي هو نموذج قوي تم إنشاؤه بمسؤولية.
تتميز بنية نموذج Llama 3 بتركيزها على الكفاءة والأداء في مهام معالجة اللغة الطبيعية. استنادًا إلى إطار عمل قائم على المحولات، فإنه يؤكد على الكفاءة الحسابية، خاصة أثناء إنشاء النصوص، باستخدام بنية فك التشفير فقط.
ينتج النموذج مخرجات بناءً على السياق السابق فقط دون وجود أداة ترميز لترميز المدخلات مما يجعله أسرع بكثير.

تتميز نماذج Llama 3 بأداة ترميز ذات مفردات مكونة من 128 ألف رمز. تعني المفردات الأكبر أن النماذج يمكنها فهم النصوص ومعالجتها بشكل أفضل. أيضًا، تستخدم النماذج الآن الانتباه إلى الاستعلام المجمع (GQA) لتحسين كفاءة الاستدلال. GQA هي تقنية يمكنك اعتبارها بمثابة بقعة ضوء تساعد النماذج على التركيز على الأجزاء ذات الصلة من بيانات الإدخال لإنشاء استجابات أسرع وأكثر دقة.
فيما يلي بعض التفاصيل الأخرى المثيرة للاهتمام حول بنية نموذج Llama 3:
لتدريب أكبر نماذج Llama 3، تم دمج ثلاثة أنواع من الموازاة: موازاة البيانات، وموازاة النماذج، وموازاة خطوط المعالجة.
يقسم توازي البيانات بيانات التدريب على وحدات معالجة رسومات متعددة، بينما يقسم توازي النماذج بنية النموذج لاستخدام القوة الحسابية لكل GPU. تقسم موازاة خط الأنابيب عملية التدريب إلى مراحل متسلسلة، مما يؤدي إلى تحسين الحوسبة والاتصالات.
حقق التطبيق الأكثر كفاءة استخدامًا ملحوظًا في الحوسبة، حيث تجاوز 400 TFLOPS لكل GPU رسومات عند التدريب على 16,000 وحدة معالجة رسومات في وقت واحد. أُجريت عمليات التدريب هذه على مجموعتين مخصصتين لوحدات معالجة GPU تضم كل منهما 24,000 وحدة معالجة رسومات. وقد وفرت هذه البنية التحتية الحاسوبية الكبيرة القوة اللازمة لتدريب نماذج Llama 3 واسعة النطاق بكفاءة.
ولزيادة وقت تشغيل GPU إلى أقصى حد، تم تطوير مكدس تدريب جديد متقدم، مما أدى إلى أتمتة اكتشاف الأخطاء ومعالجتها وصيانتها. تم تحسين موثوقية الأجهزة وآليات الكشف بشكل كبير للتخفيف من مخاطر تلف البيانات الصامتة. أيضًا، تم تطوير أنظمة تخزين جديدة قابلة للتطوير لتقليل نفقات التحقق والتراجع.
أدت هذه التحسينات إلى وقت تدريب فعال بشكل عام يزيد عن 95%. مجتمعة، زادت كفاءة تدريب Llama 3 بمقدار ثلاثة أضعاف تقريبًا مقارنة بـ Llama 2. هذه الكفاءة ليست مجرد مثيرة للإعجاب؛ إنها تفتح إمكانيات جديدة لطرق تدريب الذكاء الاصطناعي.
نظرًا لأن Llama 3 مفتوح المصدر، يمكن للباحثين والطلاب دراسة رموزه وإجراء التجارب والمشاركة في مناقشات حول المخاوف والتحيزات الأخلاقية. ومع ذلك، فإن Llama 3 ليس مخصصًا للجمهور الأكاديمي فقط. إنه يحدث طفرة في التطبيقات العملية أيضًا. إنه يصبح العمود الفقري لواجهة Meta AI Chat، حيث يتكامل بسلاسة في منصات مثل Facebook و Instagram و WhatsApp و Messenger. باستخدام Meta AI، يمكن للمستخدمين المشاركة في محادثات باللغة الطبيعية، والوصول إلى توصيات مخصصة، وتنفيذ المهام، والتواصل مع الآخرين بسهولة.

يقدم Llama 3 أداءً جيدًا بشكل استثنائي في العديد من المعايير الرئيسية التي تقيّم فهم اللغة المعقدة وقدرات الاستدلال. فيما يلي بعض المعايير التي تختبر جوانب مختلفة من قدرات Llama 3:
إن نتائج Llama 3 المتميزة في هذه الاختبارات تميزه بوضوح عن منافسيه مثل Gemma 7B من GoogleوMistral 7B من Mistral، وClaude 3 Sonnet من Anthropic. ووفقًا للإحصائيات المنشورة، لا سيما الطراز 70B، يتفوق Llama 3 على هذه النماذج في جميع المعايير المذكورة أعلاه.

تقوم Meta بتوسيع نطاق وصول Llama 3 من خلال إتاحته عبر مجموعة متنوعة من المنصات لكل من المستخدمين العامين والمطورين. بالنسبة للمستخدمين اليوميين، يتم دمج Llama 3 في منصات Meta الشائعة مثل WhatsApp و Instagram و Facebook و Messenger. يمكن للمستخدمين الوصول إلى ميزات متقدمة مثل البحث في الوقت الفعلي والقدرة على إنشاء محتوى إبداعي مباشرة داخل هذه التطبيقات.
يتم دمج Llama 3 أيضًا في التقنيات القابلة للارتداء مثل النظارات الذكية Ray-Ban Meta وسماعة الرأس Meta Quest VR لتجارب تفاعلية.
يتوفر Llama 3 على مجموعة متنوعة من المنصات للمطورين، بما في ذلك AWS وDatabricks Google Cloud Hugging Face وKaggle وIBM WatsonX Microsoft Azure NVIDIA NIM وSnowflake. يمكنك أيضاً الوصول إلى هذه النماذج مباشرةً من Meta. تجعل المجموعة الواسعة من الخيارات من السهل على المطورين دمج إمكانات نماذج الذكاء الاصطناعي المتقدمة هذه في مشاريعهم، سواء كانوا يفضلون العمل مباشرةً مع Meta أو من خلال منصات أخرى شائعة.
تستمر التطورات في تعلم الآلة في تغيير الطريقة التي نتفاعل بها مع التكنولوجيا كل يوم. يوضح Llama 3 من Meta أن LLMs لم تعد مجرد إنشاء نصوص بعد الآن. تعالج LLMs مشكلات معقدة وتتعامل مع لغات متعددة. بشكل عام، يجعل Llama 3 الذكاء الاصطناعي أكثر قابلية للتكيف وسهولة الوصول إليه من أي وقت مضى. بالنظر إلى المستقبل، تعد التحديثات المخطط لها لـ Llama 3 بمزيد من الإمكانات، مثل التعامل مع نماذج متعددة وفهم سياقات أكبر.
تحقق من مستودع GitHub الخاص بنا وانضم إلى مجتمعنا لمعرفة المزيد حول الذكاء الاصطناعي. قم بزيارة صفحات الحلول الخاصة بنا لمعرفة كيف يتم تطبيق الذكاء الاصطناعي في مجالات مثل التصنيع و الزراعة.



{kind=link}
{kind=link}
{kind=link}