



تعلّم كيف يمكن استخدام Mask R-CNN segment الكائنات بدقة في الصور ومقاطع الفيديو لمختلف التطبيقات في مختلف القطاعات.

تعلّم كيف يمكن استخدام Mask R-CNN segment الكائنات بدقة في الصور ومقاطع الفيديو لمختلف التطبيقات في مختلف القطاعات.
أصبحت الابتكارات مثل الروبوتات في المستودعات، والسيارات ذاتية القيادة التي تتحرك بأمان في الشوارع المزدحمة، والطائرات بدون طيار التي تتحقق من المحاصيل، وأنظمة الذكاء الاصطناعي التي تفحص المنتجات في المصانع أكثر شيوعًا مع زيادة اعتماد الذكاء الاصطناعي. إحدى التقنيات الرئيسية التي تدفع هذه الابتكارات هي الرؤية الحاسوبية (computer vision)، وهي فرع من فروع الذكاء الاصطناعي التي تمكن الآلات من فهم البيانات المرئية وتفسيرها.
على سبيل المثال، اكتشاف الأجسام هو مهمة رؤية حاسوبية تساعد في تحديد وتحديد مواقع الأجسام في الصور باستخدام مربعات إحاطة. في حين أن مربعات الإحاطة تقدم معلومات مفيدة، إلا أنها توفر تقديرًا تقريبيًا لموقع الجسم ولا يمكنها التقاط شكله أو حدوده الدقيقة. وهذا يجعلها أقل فعالية في التطبيقات التي تتطلب تحديدًا دقيقًا.
لحل هذه المشكلة، طور الباحثون نماذج تجزئة تلتقط الخطوط العريضة الدقيقة للكائنات، مما يوفر تفاصيل على مستوى البكسل لتحليل واكتشاف أكثر دقة.
Mask R-CNN هو أحد هذه النماذج. تم تقديمه في عام 2017 من قِبل شركة فيسبوك لأبحاث الذكاء الاصطناعي (FAIR)، وهو يعتمد على نماذج سابقة مثل R-CNN وR-CNN السريع وFaster R-CNN. وباعتبارها علامة فارقة مهمة في تاريخ الرؤية الحاسوبية، فقد مهدت Mask R-CNN الطريق لنماذج أكثر تقدمًا، مثل Ultralytics YOLO11.
في هذه المقالة، سنستكشف في هذه المقالة ما هو قناع R-CNN، وكيفية عمله، وتطبيقاته، والتحسينات التي طرأت عليه بعد ذلك، وصولاً إلى YOLO11.
Mask R-CNN، الذي يرمز إلى Mask Region-based Convolutional Neural Network، هو نموذج للتعلم العميق مصمم لمهام رؤية الكمبيوتر مثل اكتشاف الكائنات وتقسيم المثيلات.
يتجاوز تجزئة المثيل اكتشاف الكائنات التقليدي من خلال عدم تحديد الكائنات في الصورة فحسب، بل أيضًا تحديد كل كائن بدقة. يقوم بتعيين تسمية فريدة لكل كائن يتم اكتشافه ويلتقط شكله الدقيق على مستوى البكسل. هذا النهج التفصيلي يجعل من الممكن التمييز بوضوح بين الكائنات المتداخلة والتعامل بدقة مع الأشكال المعقدة.
يعتمد Mask R-CNN على Faster R-CNN، الذي يكتشف الكائنات ويضع عليها علامات تعريفية ولكنه لا يحدد أشكالها الدقيقة. يقوم Mask R-CNN بتحسين ذلك من خلال تحديد وحدات البكسل الدقيقة التي تشكل كل كائن، مما يسمح بتحليل صور أكثر تفصيلاً ودقة.

يتّبع Mask R-CNN نهجًا تدريجيًا detect الأجسام segment بدقة. ويبدأ باستخراج الميزات الرئيسية باستخدام شبكة عصبية عميقة (نموذج متعدد الطبقات يتعلم من البيانات)، ثم يحدد مناطق الأجسام المحتملة باستخدام شبكة اقتراح المناطق (مكون يقترح مناطق الأجسام المحتملة)، وأخيراً ينقح هذه المناطق عن طريق إنشاء أقنعة تجزئة مفصلة (مخططات دقيقة للأجسام) تلتقط الشكل الدقيق لكل جسم.
بعد ذلك، سوف نستعرض كل خطوة للحصول على فكرة أفضل عن كيفية عمل Mask R-CNN.
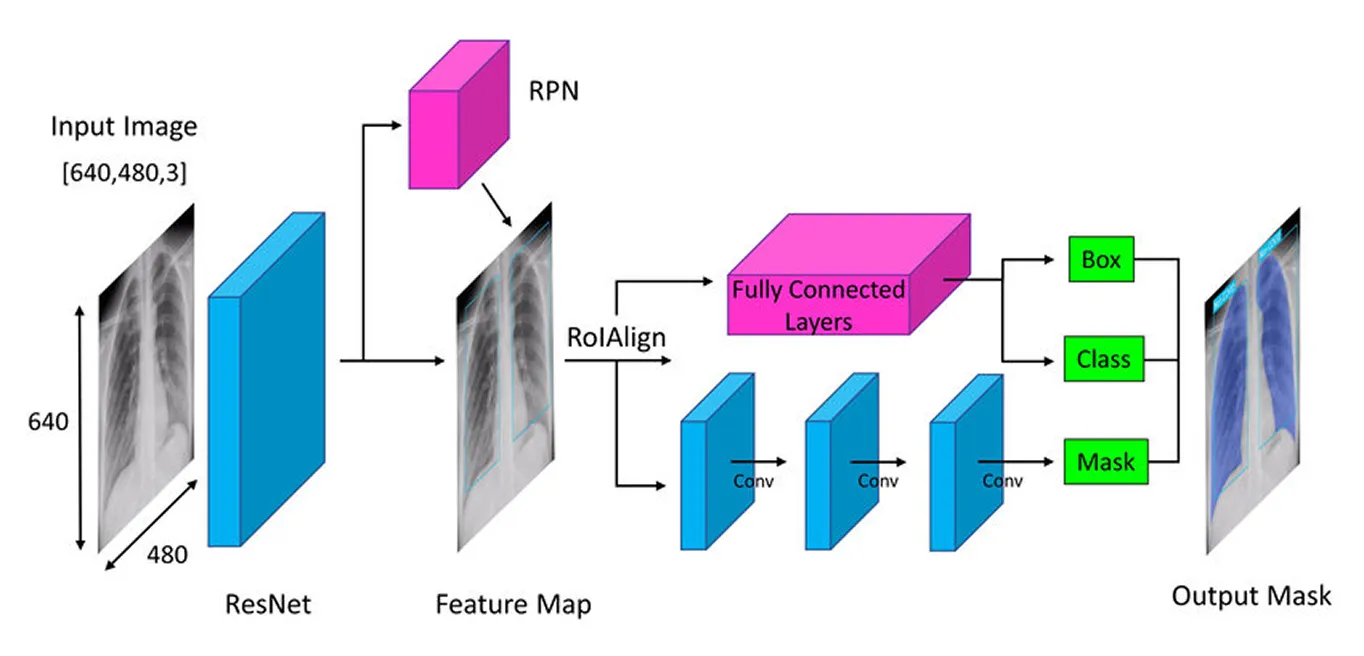
تتمثل الخطوة الأولى في بنية Mask R-CNN في تقسيم الصورة إلى أجزائها الرئيسية حتى يتمكن النموذج من فهم محتواها. فكر في الأمر كما لو كنت تنظر إلى صورة وتلاحظ بشكل طبيعي تفاصيل مثل الأشكال والألوان والحواف. يفعل النموذج شيئًا مشابهًا باستخدام شبكة عصبية عميقة تسمى "العمود الفقري" (غالبًا ResNet-50 أو ResNet-101)، والتي تعمل كعيونه لمسح الصورة والتقاط التفاصيل الرئيسية.
نظرًا لأن الكائنات الموجودة في الصور يمكن أن تكون صغيرة جدًا أو كبيرة جدًا، فإن Mask R-CNN يستخدم شبكة Feature Pyramid Network. هذا يشبه وجود عدسات مكبرة مختلفة تتيح للنموذج رؤية التفاصيل الدقيقة والصورة الأكبر، مما يضمن ملاحظة الكائنات بجميع أحجامها.
بمجرد استخلاص هذه الميزات المهمة، ينتقل النموذج بعد ذلك لتحديد مواقع الكائنات المحتملة في الصورة، مما يمهد الطريق لمزيد من التحليل.
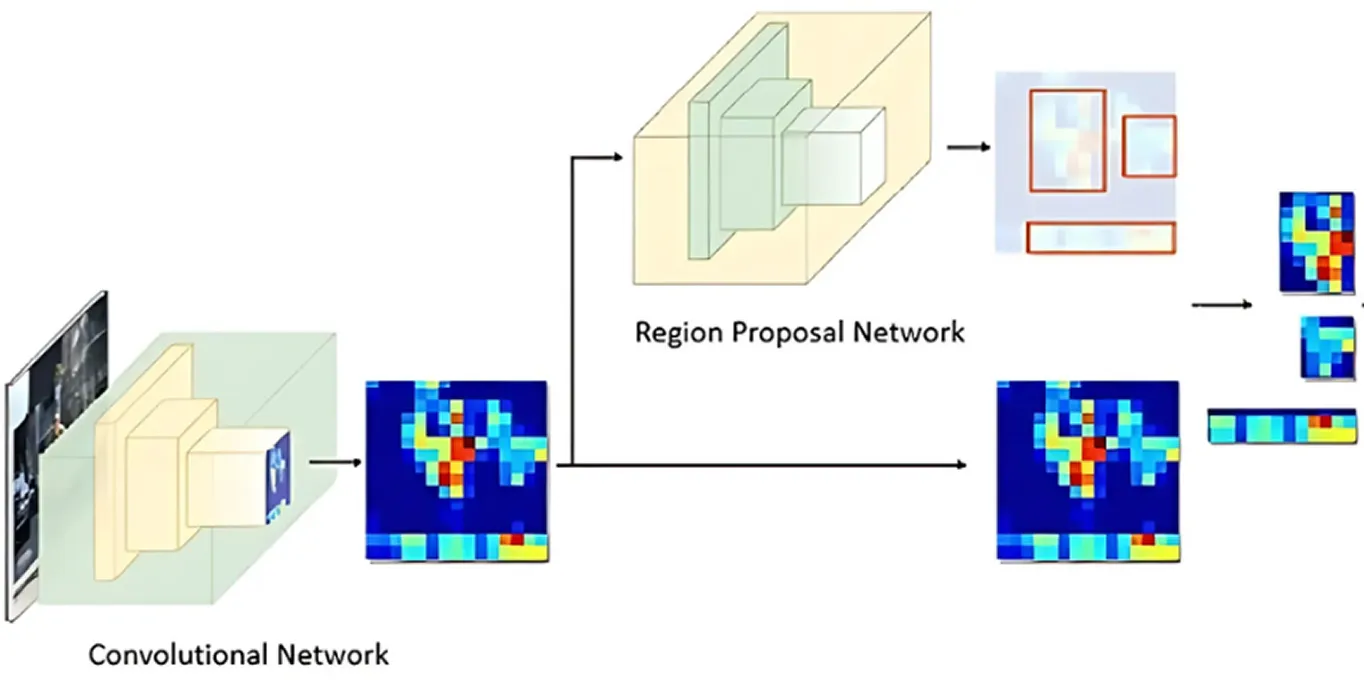
بعد معالجة الصورة بحثًا عن الميزات الرئيسية، تتولى شبكة اقتراح المنطقة المسؤولية. ينظر هذا الجزء من النموذج إلى الصورة ويقترح المناطق التي من المحتمل أن تحتوي على كائنات.
يقوم بذلك عن طريق إنشاء مواقع كائنات محتملة متعددة تسمى المرتكزات (anchors). ثم تقوم الشبكة بتقييم هذه المرتكزات وتحديد أكثرها واعدة لمزيد من التحليل. بهذه الطريقة، يركز النموذج فقط على المناطق التي من المرجح أن تكون مثيرة للاهتمام، بدلاً من التحقق من كل بقعة في الصورة.
مع تحديد المجالات الرئيسية، فإن الخطوة التالية هي تحسين التفاصيل المستخرجة من هذه المناطق. استخدمت النماذج السابقة طريقة تسمى ROI Pooling (تجميع مناطق الاهتمام) للحصول على ميزات من كل منطقة، ولكن هذه التقنية أدت أحيانًا إلى اختلالات طفيفة عند تغيير حجم المناطق، مما يجعلها أقل فعالية - خاصة بالنسبة للكائنات الأصغر أو المتداخلة.
يقوم Mask R-CNN بالتحسين على ذلك باستخدام تقنية تسمى ROI Align (محاذاة منطقة الاهتمام). بدلاً من تقريب الإحداثيات كما تفعل ROI Pooling، تستخدم ROI Align الاستيفاء الثنائي لتقدير قيم البكسل بدقة أكبر. الاستيفاء الثنائي هو طريقة تحسب قيمة بكسل جديدة عن طريق حساب متوسط قيم أقرب أربعة جيران لها، مما يخلق انتقالات أكثر سلاسة. يحافظ هذا على ميزات محاذية بشكل صحيح مع الصورة الأصلية، مما يؤدي إلى اكتشاف وتقسيم أكثر دقة للكائنات.
على سبيل المثال، في مباراة كرة قدم، قد يتم الخلط بين لاعبين يقفان بالقرب من بعضهما البعض بسبب تداخل مربعاتهما المحيطة. يساعد ROI Align على فصلهما عن طريق الحفاظ على أشكالهما مميزة.
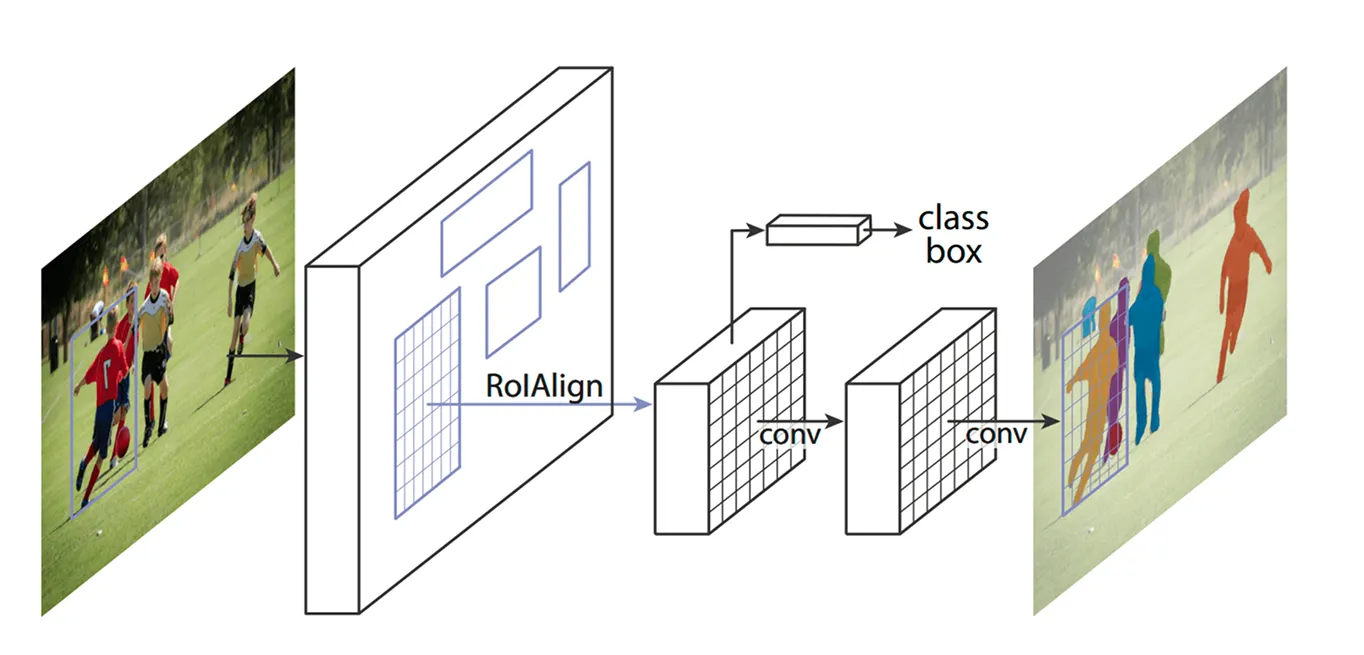
بمجرد أن يقوم ROI Align بمعالجة الصورة، فإن الخطوة التالية هي classify الكائنات وضبط مواقعها. ينظر النموذج إلى كل منطقة مستخرجة ويقرر ما هو الكائن الذي تحتوي عليه. يقوم بتعيين درجة احتمالية للفئات المختلفة ويختار أفضل تطابق.
في الوقت نفسه، فإنه يضبط مربعات الإحاطة لتناسب الكائنات بشكل أفضل. قد لا يتم وضع المربعات الأولية في مكان مثالي، لذلك يساعد ذلك على تحسين الدقة من خلال التأكد من أن كل مربع يحيط بإحكام بالكائن المكتشف.
أخيرًا، تتخذ Mask R-CNN خطوة إضافية: فهي تنشئ قناع تجزئة مفصل لكل كائن بالتوازي.
عندما ظهر هذا النموذج، قوبل بالكثير من الحماس من مجتمع الذكاء الاصطناعي وسرعان ما تم استخدامه في تطبيقات مختلفة. فقدرته على detect الأشياء segment في الوقت الفعلي جعلته يغير قواعد اللعبة في مختلف الصناعات.
على سبيل المثال، يعد تعقب الحيوانات المهددة بالانقراض في البرية مهمة صعبة. فالعديد من الأنواع تتنقل عبر الغابات الكثيفة، مما يجعل من الصعب على دعاة الحفاظ على البيئة track . وتستخدم الطرق التقليدية مصائد الكاميرات والطائرات بدون طيار وصور الأقمار الصناعية، لكن فرز كل هذه البيانات يدوياً يستغرق وقتاً طويلاً. يمكن أن يؤدي الخطأ في تحديد الهوية والمشاهدات المفقودة إلى إبطاء جهود الحفاظ على البيئة.
من خلال التعرف على السمات الفريدة مثل خطوط النمر أو بقع الزرافة أو شكل أذني الفيل، يمكن لنموذج Mask R-CNN detect الحيوانات في الصور ومقاطع الفيديو segment بدقة أكبر. حتى عندما تكون الحيوانات مخفية جزئيًا بالأشجار أو تقف بالقرب من بعضها البعض، يمكن للنموذج فصلها وتحديد كل منها على حدة، مما يجعل مراقبة الحياة البرية أسرع وأكثر موثوقية.

على الرغم من أهميته التاريخية في اكتشاف الكائنات وتجزئتها، إلا أن Mask R-CNN يأتي أيضًا مع بعض العيوب الرئيسية. فيما يلي بعض التحديات المتعلقة بـ Mask R-CNN:
كانت شبكة R-CNN ذات القناع رائعة لمهام التجزئة، ولكن العديد من الصناعات كانت تتطلع إلى اعتماد الرؤية الحاسوبية مع إعطاء الأولوية للسرعة والأداء في الوقت الحقيقي. قاد هذا المطلب الباحثين إلى تطوير نماذج من مرحلة واحدة detect الأجسام في مسار واحد، مما أدى إلى تحسين الكفاءة بشكل كبير.
على عكس عملية Mask R-CNN متعددة الخطوات، تركز نماذج الرؤية الحاسوبية ذات المرحلة الواحدة مثل YOLO (أنت تنظر مرة واحدة فقط) على مهام الرؤية الحاسوبية في الوقت الفعلي. بدلاً من التعامل مع الاكتشاف والتجزئة بشكل منفصل، يمكن لنماذج YOLO تحليل الصورة دفعة واحدة. وهذا ما يجعلها مثالية لتطبيقات مثل القيادة الذاتية والرعاية الصحية والتصنيع والروبوتات، حيث يكون اتخاذ القرارات السريعة أمرًا بالغ الأهمية.
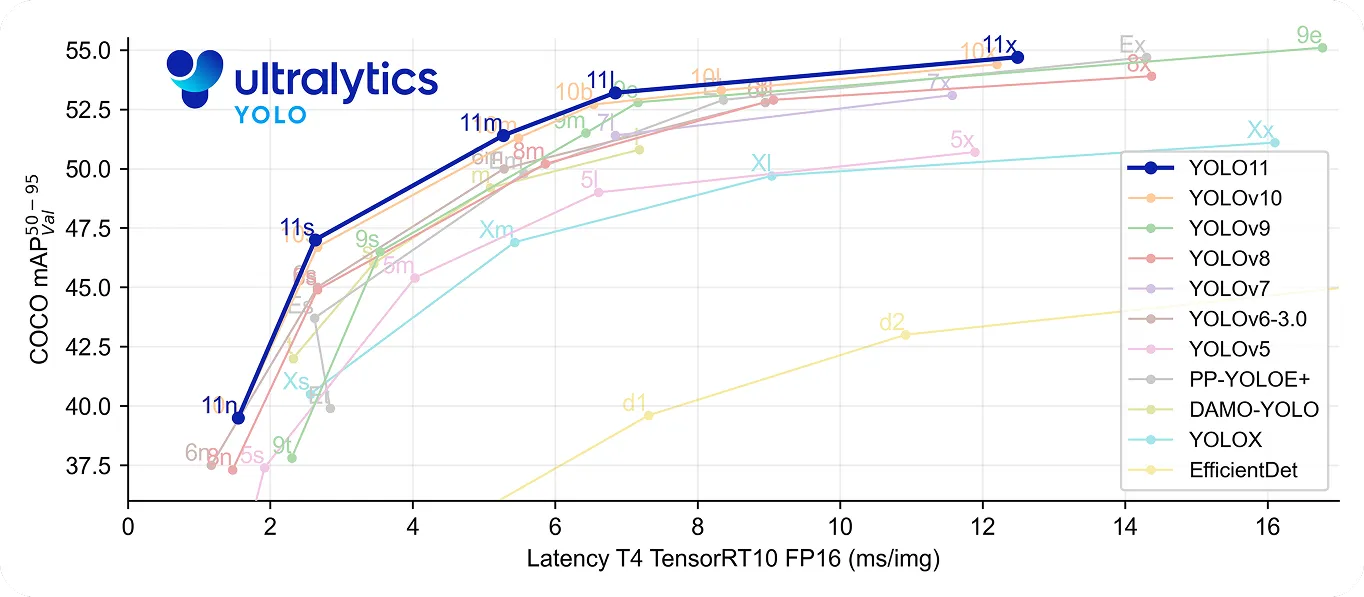
على وجه الخصوص، يأخذ YOLO11 هذا الأمر خطوة إلى الأمام من خلال كونه سريعًا ودقيقًا في آنٍ واحد. فهو يستخدم معلمات أقل بنسبة 22% أقل من YOLOv8m ولكنه لا يزال يحقق متوسط دقة أعلى في مجموعة بيانات COCO mAP يعني أنه يكتشف الأجسام بدقة أكبر. تجعله سرعة معالجته المحسّنة خيارًا جيدًا للتطبيقات في الوقت الفعلي حيث يكون كل جزء من الثانية مهمًا.
بالنظر إلى تاريخ رؤية الكمبيوتر، يُعتبر Mask R-CNN بمثابة إنجاز كبير في الكشف عن الكائنات وتجزئتها. فهو يقدم نتائج دقيقة للغاية حتى في الإعدادات المعقدة، وذلك بفضل عمليته التفصيلية متعددة الخطوات.
ومع ذلك، فإن هذه العملية نفسها تجعلها أبطأ مقارنةً بنماذج الوقت الحقيقي مثل YOLO. مع تنامي الحاجة إلى السرعة والكفاءة، تستخدم العديد من التطبيقات الآن نماذج ذات مرحلة واحدة مثل Ultralytics YOLO11 والتي توفر اكتشافًا سريعًا ودقيقًا للأجسام. في حين أن قناع R-CNN مهم فيما يتعلق بفهم تطور رؤية الكمبيوتر، فإن الاتجاه نحو حلول الوقت الحقيقي يسلط الضوء على الطلب المتزايد على حلول رؤية الكمبيوتر الأسرع والأكثر كفاءة.
انضم إلى مجتمعنا المتنامي! استكشف مستودع GitHub الخاص بنا لمعرفة المزيد عن الذكاء الاصطناعي. هل أنت مستعد لبدء مشاريع رؤية الكمبيوتر الخاصة بك؟ تحقق من خيارات الترخيص الخاصة بنا. اكتشف الذكاء الاصطناعي في الزراعة و Vision AI في الرعاية الصحية من خلال زيارة صفحات الحلول الخاصة بنا!


