



探索 Claude 3 模型卡及其对视觉 AI 开发的影响。

探索 Claude 3 模型卡及其对视觉 AI 开发的影响。
近年来,视觉 AI 取得了显著进展,彻底改变了从 医疗保健 到 零售业 的各个行业。 了解底层模型及其文档对于有效利用这些进步至关重要。 模型卡是人工智能 (AI) 开发者工具库中一种重要的工具,它提供了 AI 模型的特性和性能的全面概述。
本文将探讨Anthropic 开发的 克劳德 3 模型卡及其对视觉人工智能开发的影响。 Claude 3是一个全新的大型多模态模型系列,由三个变体组成:Claude 3 Opus 是功能最强大的型号;Claude 3 Sonnet 兼顾了性能和速度;Claude 3 Haiku 是速度最快、成本效益最高的选择。每种型号都配备了新的视觉功能,使它们能够处理和分析图像数据。
什么是模型卡?模型卡是一份详细的文档,提供了关于机器学习模型的开发、训练和评估的深入信息。 它旨在通过提供关于模型的功能、预期用例和潜在局限性的清晰信息,来提高透明度、问责制和 AI 的道德使用。 这可以通过提供关于模型的更详细的数据来实现,例如其评估指标,以及其与以前的模型和其他竞争对手的比较。
评估指标对于评估模型性能至关重要。 Claude 3 模型卡列出了诸如准确率、精确率、召回率和 F1 分数等指标,从而清晰地展示了模型的优势和需要改进的领域。 这些指标以行业标准为基准,展示了 Claude 3 的竞争性能。
此外,Claude 3 在其前身的基础上,融合了架构和训练技术的进步。 该模型卡将 Claude 3 与早期版本进行了比较,突出了在准确性、效率以及对新用例的适用性方面的改进。
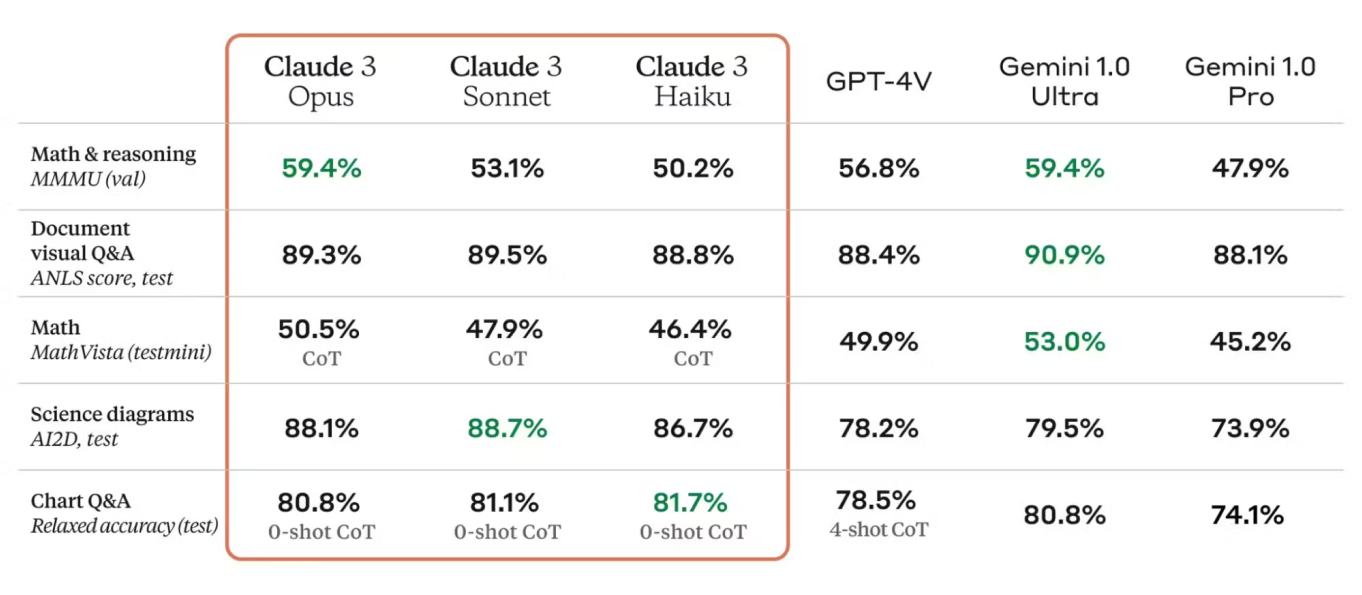
Claude 3 的架构和训练过程使其在各种自然语言处理 (NLP) 和视觉任务中都能实现可靠的性能。 它在基准测试中始终取得优异的成绩,展示了其有效执行复杂语言分析的能力。
Claude 3 在各种 数据集 上的训练以及数据增强技术的使用确保了其稳健性以及在不同场景中进行泛化的能力。 这使得该模型在广泛的应用中具有通用性和有效性。
虽然克劳德 3 的成果值得一提,但从根本上说,它只是一个大型语言模型(LLM)。虽然像克劳德 3 这样的大型语言模型可以执行各种计算机视觉任务,但它们并不是专门为物体检测、边界框创建和图像分割等任务而设计的。因此,它们在这些领域的准确性可能无法与专门为计算机视觉设计的模型相媲美,例如 Ultralytics YOLOv8.不过,LLM 在其他领域,尤其是自然语言处理 (NLP) 领域表现出色,其中 Claude 3 将简单的视觉任务与人类推理相结合,显示出强大的优势。

NLP 功能是指 AI 模型理解和响应人类语言的能力。 这种能力在 Claude 3 在视觉领域的应用中得到了高度利用,使其能够提供上下文丰富的描述、解释复杂的视觉数据,并增强视觉 AI 任务的整体性能。
Claude 3 的一项令人印象深刻的功能是,尤其是在用于视觉 AI 任务时,它能够处理并将具有难以辨认的手写体的低质量图像转换为文本。 此功能展示了该模型先进的处理能力和多模态推理能力。 在本节中,我们将探讨 Claude 3 如何完成此任务,重点介绍其底层机制以及对视觉 AI 开发的影响。
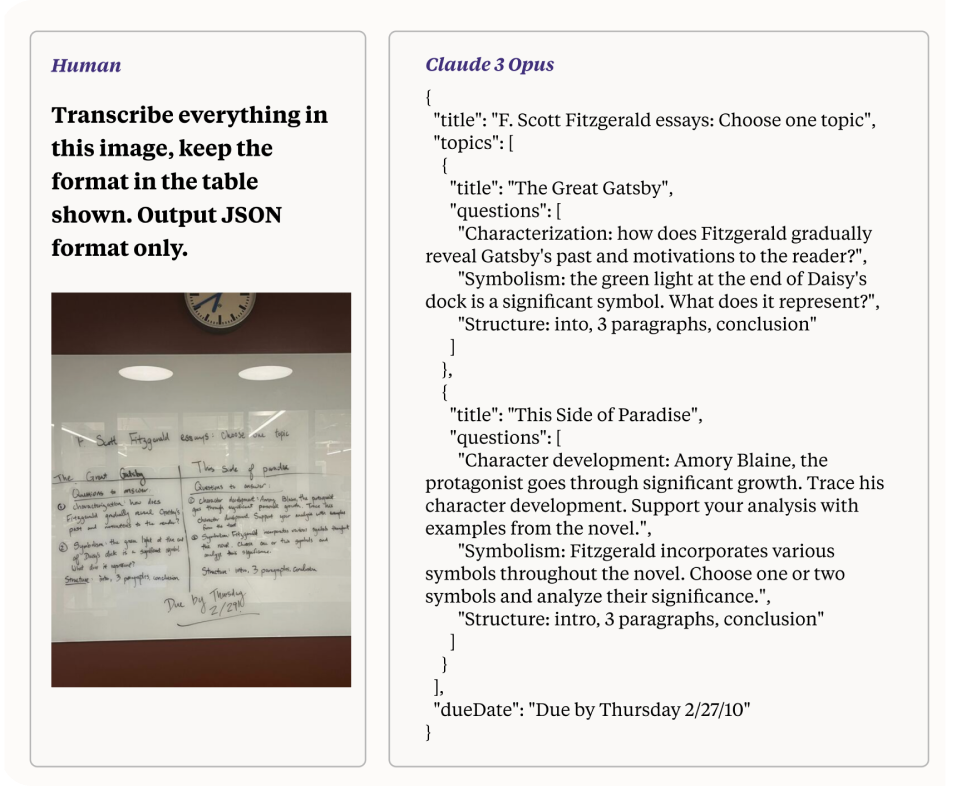
将低质量、手写字迹难以辨认的照片转换为文本是一项复杂的任务,涉及多重挑战:
如前所述,Claude 3 模型通过结合计算机视觉和自然语言处理 (NLP) 的先进技术来应对这些挑战。
Claude 3 的架构使其能够使用视觉输入执行复杂的推理任务。例如,如图 1 所示,该模型可以解释图表,例如识别关于互联网使用情况的图表中 G7 国家,提取相关数据,并执行计算以分析趋势。这种多步骤推理(如计算不同年龄组互联网使用情况的统计差异)提高了模型在实际应用中的准确性和实用性。

Claude 3 擅长将图像转换为详细的描述,展示了其在计算机视觉和自然语言处理方面的强大能力。当给定一个图像时,Claude 3 首先采用卷积神经网络 (CNN) 来提取关键特征,并识别视觉数据中的对象、模式和上下文元素。
随后,transformer 层对这些特征进行分析,利用注意力机制来理解图像中不同元素之间的关系和上下文。这种多模态方法使克劳德 3 不仅能识别物体,还能理解它们在场景中的相互作用和意义,从而生成准确、语境丰富的描述。

像 Claude 3 这样的大型语言模型(LLM)擅长自然语言处理,而不是计算机视觉。虽然它们可以描述图像,但对象检测和图像分割等任务最好由YOLOv8 等面向视觉的模型来处理。这些专业模型针对视觉任务进行了优化,在分析图像时性能更佳。此外,该模型不能执行创建边界框等任务。
将 Claude 3 与计算机视觉系统结合可能很复杂,并且可能需要额外的处理步骤来弥合文本和视觉数据之间的差距。
Claude 3 主要是在大量的文本数据上进行训练的,这意味着它缺乏在计算机视觉任务中实现高性能所需的广泛的视觉数据集。因此,虽然 Claude 3 擅长理解和生成文本,但它不具备处理或分析图像的能力,其熟练程度与专门为视觉数据设计的模型相同。这种限制使其在需要解释或生成视觉内容的应用中效果较差。
与其他大型语言模型类似,Claude 3 将不断改进。未来的增强功能可能会侧重于更好的视觉任务,例如图像检测和目标识别,以及自然语言处理任务的进步。这将能够对物体和场景进行更准确和详细的描述,以及其他类似的任务。
最后,对 Claude 3 的持续研究将优先考虑提高可解释性、减少偏差以及改善跨不同数据集的泛化能力。这些努力将确保模型在各种应用中的稳健性能,并促进对其输出的信任和可靠性。
Claude 3 模型卡是 Vision AI 领域的开发人员和利益相关者的宝贵资源,它提供了对模型架构、性能和伦理考量的详细见解。通过提高透明度和问责制,它有助于确保 AI 技术的负责任和有效使用。随着 Vision AI 的不断发展,像 Claude 3 这样的模型卡将在指导开发和促进对 AI 系统的信任方面发挥关键作用。
在Ultralytics,我们热衷于推动人工智能技术的发展。要探索我们的人工智能解决方案并了解我们的最新创新,请访问我们的GitHub 存储库。加入我们的Discord社区,了解我们如何改变自动驾驶汽车和制造业等行业!🚀


