



了解YOLO,这是一种创新的对象检测模型,可通过文本提示识别对象。探索YOLO 的工作原理及其应用,并通过一个快速代码示例进行实际操作。

了解YOLO,这是一种创新的对象检测模型,可通过文本提示识别对象。探索YOLO 的工作原理及其应用,并通过一个快速代码示例进行实际操作。
计算机视觉项目通常需要花费大量时间标注数据和训练对象检测模型。不过,这可能很快就会成为过去。腾讯人工智能实验室于 2024 年 1 月 31 日发布了实时、开放词汇的物体检测模型YOLO。YOLO 是一个零镜头模型,这意味着你可以在图像上运行物体检测推断,而无需对其进行训练。
零镜头模型有可能改变我们处理计算机视觉应用的方式。在本博客中,我们将探讨YOLO 的工作原理及其潜在用途,并分享一个实用的代码示例,帮助您开始使用。
您可以通过YOLO 模型传递图片和文本提示,说明您要查找的对象。例如,如果您想在一张照片中找到 "一个穿红色衬衫的人",YOLO 就会接收这一输入并开始工作。
该模型独特的架构结合了三个主要元素:
YOLO 检测器会扫描输入图像,以识别潜在的物体。文本编码器将您的描述转换成模型可以理解的格式。然后,通过 RepVL-PAN 使用多级跨模态融合将这两股信息流合并。这样,YOLO 就能在图像中精确地detect 和定位您在提示中描述的物体。

使用YOLO 的最大优势之一是,您无需针对特定类别训练模型。它已经从成对的图像和文本中学习过,因此知道如何根据描述找到对象。您可以免去数小时的数据收集、数据注释、昂贵的 GPU 训练等工作。
以下是使用YOLO 的其他一些好处:
YOLO 模型的应用范围非常广泛。让我们来探讨其中的一些应用。
在装配线上制造的产品在包装前会进行目视检查,以发现缺陷。缺陷检测通常由人工完成,这既耗时又容易出错。这些错误可能会导致高成本以及维修或召回的需求等问题。为了解决这个问题,已经创建了专门的机器视觉相机和AI系统来进行这些检查。
YOLO 模型是这一领域的一大进步。即使没有针对特定问题接受过培训,它们也能利用其零拍能力发现产品中的缺陷。例如,一家生产水瓶的工厂可以利用YOLO 轻松识别出瓶盖密封良好的水瓶与漏盖或有缺陷的水瓶。

YOLO 模型允许机器人与陌生环境进行交互。虽然没有接受过关于房间内可能存在的特定物体的训练,但它们仍能识别出房间内存在的物体。因此,假设一个机器人进入了一个它从未进入过的房间。有了 "YOLO模型,尽管它没有接受过关于椅子、桌子或台灯等物品的专门训练,但仍能识别和辨认这些物品。
除了物体检测外,YOLO 还能利用其 "先detect后检测 "功能确定这些物体的状况。例如,在农业 机器人技术中,它可以通过detect 机器人进行编程来识别成熟水果和未成熟水果。
汽车行业涉及许多活动部件,YOLO 可用于不同的汽车应用。例如,在汽车维护方面,YOLO 无需人工标记或大量预培训就能识别各种物体的能力非常有用。YOLO 可以用来识别需要更换的汽车零部件。它甚至可以自动执行质量检查、发现新车缺陷或缺件等任务。
另一项应用是自动驾驶汽车中的零镜头物体检测。YOLO 的零镜头检测功能可以提高自动驾驶汽车实时detect 和classify 路上行人、交通标志和其他车辆等物体的能力。这样,它就能帮助detect 障碍物,防止事故发生,从而实现更安全的旅程。
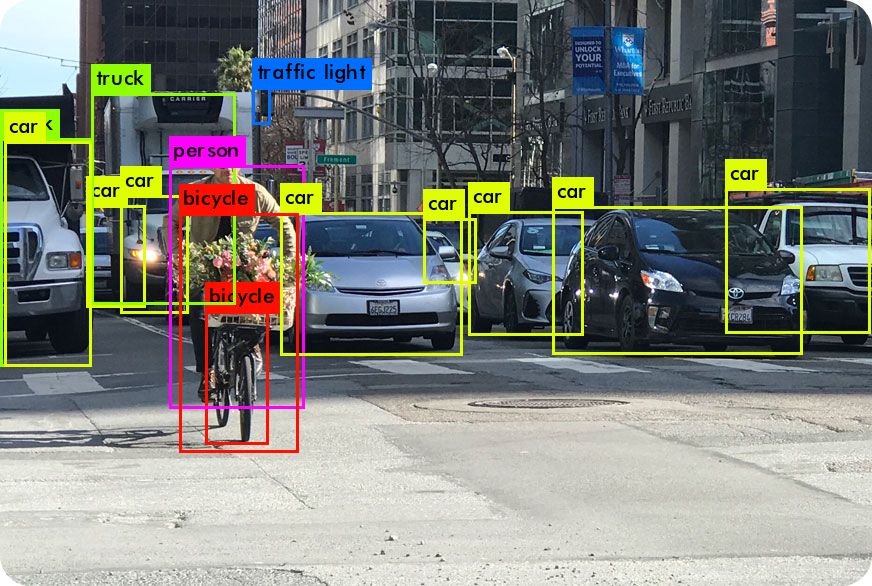
识别零售商店货架上的物品是跟踪库存、维护库存和自动化流程的重要组成部分。Ultralytics YOLO 能够识别各种物品,无需人工标记或大量的预培训,这对库存管理非常有用。
例如,在库存管理方面,YOLO 可以迅速发现货架上的商品并进行分类,如不同品牌的能量饮料。零售店可以保持准确的库存,有效地管理库存水平,使供应链运作更加顺畅。
所有应用程序都独一无二,展示了YOLO 的广泛应用。接下来,让我们亲手操作一下YOLO,看看一个编码示例。
正如我们之前提到的,YOLO 可用于detect 汽车需要维修的不同部位。检测是否需要维修的计算机视觉应用程序包括拍摄汽车照片、识别汽车部件、检查汽车各部件是否损坏以及提出维修建议。该系统的每个部分都将使用不同的人工智能技术和方法。在本代码演练中,让我们重点讨论检测汽车部件的部分。
使用YOLO,您可以在 5 分钟内识别图像中的不同汽车零件。你还可以扩展这段代码,使用YOLO 尝试不同的应用!要开始使用,我们需要如下所示安装Ultralytics 软件包。
有关安装过程的更多说明和最佳实践,请查阅我们的Ultralytics 安装指南。在安装YOLOv8所需的软件包时,如果遇到任何困难,请查看我们的常见问题指南,了解解决方案和技巧。
安装所需的软件包后,我们可以从Internet下载图像以运行我们的推理。我们将使用下面的图像。

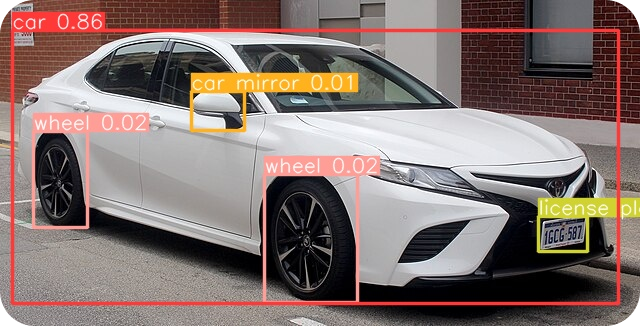
然后,我们将导入所需的软件包,初始化我们的模型,并设置我们在输入图像中要查找的类别。在这里,我们对以下类别感兴趣:汽车、车轮、车门、汽车后视镜和车牌。
然后,我们将使用预测方法,提供图像路径、最大检测次数参数以及交集大于联合IoU)和置信度(conf)阈值,对图像进行推理。最后,检测到的对象会被保存到一个名为 "result.jpg "的文件中。
以下输出图像将保存到您的文件中。
如果您想看看YOLO 在不编写代码的情况下能做些什么,可以访问YOLO 演示页面,上传输入图片并输入自定义类。
请阅读我们在YOLO 上的文档页面,了解如何保存带有自定义类的模型,以便以后可以直接使用,而无需重复输入自定义类。
如果您再看看输出图像,就会发现自定义类 "车门 "没有被检测到。尽管YOLO 取得了巨大的成就,但它也有一定的局限性。要克服这些限制并有效使用YOLO 模型,使用正确的文本提示类型非常重要。
以下是一些见解:
总之,YOLO 模型凭借其先进的物体检测功能,可以成为一个强大的工具,它提供了极高的效率和准确性,并有助于在各种应用中自动执行不同的任务,比如我们实际讨论过的识别汽车零件的例子。
欢迎访问我们的GitHub 存储库,了解我们在计算机视觉和人工智能方面的更多贡献。如果您对人工智能如何重塑医疗保健 技术等领域感到好奇,请查看我们的解决方案页面。像YOLO 这样的创新似乎有无限可能!
.webp)

.webp)