



与我们一起回顾物体检测的发展历程。我们将重点关注YOLO (只看一次)模型在过去几年中的发展。

与我们一起回顾物体检测的发展历程。我们将重点关注YOLO (只看一次)模型在过去几年中的发展。
计算机视觉是人工智能 (AI) 的一个子领域,专注于教机器像人类感知现实世界一样,看到和理解图像和视频。 虽然识别物体或识别动作对人类来说是第二天性,但对于机器来说,这些任务需要特定且专业的计算机视觉技术。 例如,计算机视觉中的一项关键任务是对象检测,它涉及识别和定位图像或视频中的对象。
自 20 世纪 60 年代以来,研究人员一直致力于改进计算机detect 物体的方法。早期的方法,如模板匹配法,是在图像上滑动预定义的模板来寻找匹配对象。这些方法虽然具有创新性,但却难以应对物体大小、方向和光照的变化。如今,我们有了先进的模型,比如 Ultralytics YOLO11这样的先进模型,甚至可以detect 小的和部分隐藏的物体,即所谓的遮挡物体,其准确性令人印象深刻。
随着计算机视觉的不断发展,回顾这些技术的发展历程显得尤为重要。在本文中,我们将探讨物体检测的演变,并揭示YOLO (只看一次)模型的转变。让我们开始吧!
在深入研究物体检测之前,让我们先来了解一下计算机视觉是如何起步的。计算机视觉的起源可以追溯到 20 世纪 50 年代末和 60 年代初,当时科学家们开始探索大脑是如何处理视觉信息的。研究人员戴维-胡贝尔(David Hubel)和托斯滕-维塞尔(Torsten Wiesel)在对猫进行实验时发现,大脑会对边缘和线条等简单图案做出反应。这为特征提取--视觉系统先detect 并识别图像中的基本特征(如边缘),然后再识别更复杂的图案--的概念奠定了基础。

大约在同一时间,出现了一种可以将物理图像转换为数字格式的新技术,这激发了人们对机器如何处理视觉信息的兴趣。 1966 年,麻省理工学院 (MIT) 的夏季视觉项目进一步推动了这一进程。 虽然该项目没有完全成功,但其目标是创建一个可以将图像中的前景与背景分离的系统。 对于 视觉 AI 社区中的许多人来说,该项目标志着计算机视觉作为一门科学领域的正式开始。
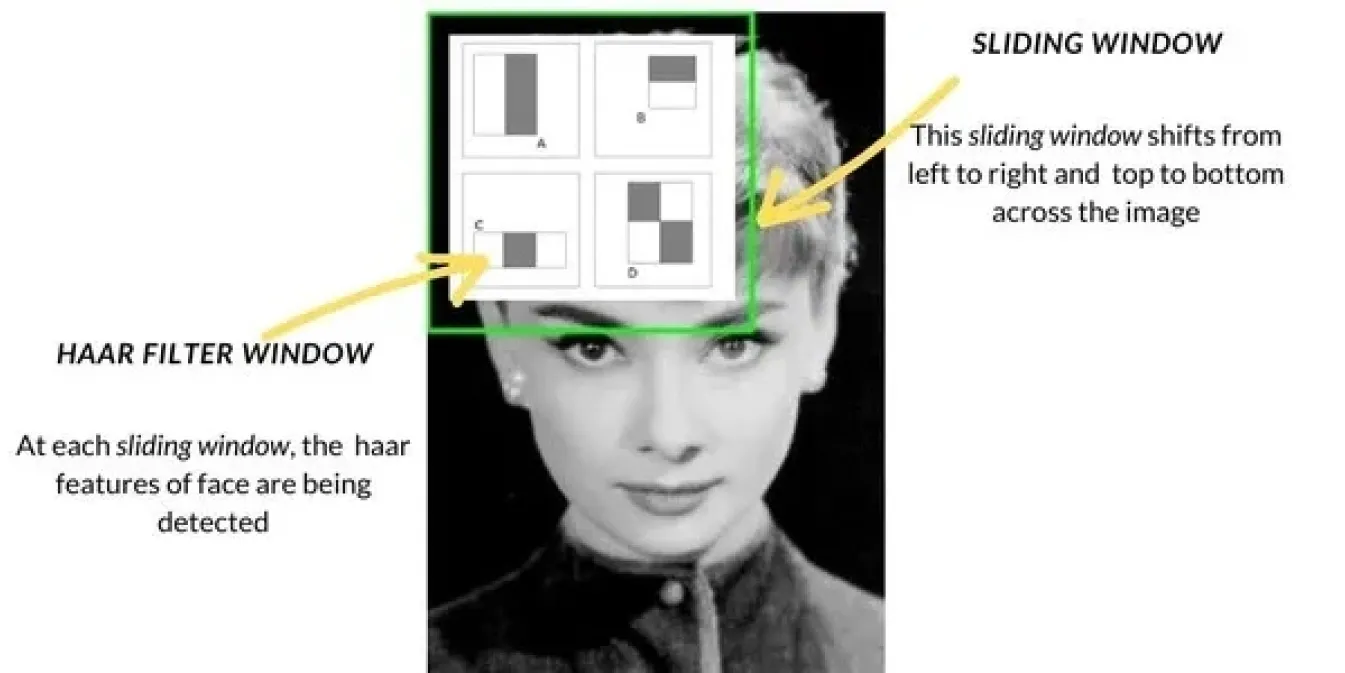
20 世纪 90 年代末和 21 世纪初,随着计算机视觉技术的发展,物体检测方法也从模板匹配等基本技术转向更先进的方法。Haar Cascade 是一种流行的方法,被广泛用于人脸检测等任务。它的工作原理是用滑动窗口扫描图像,检查图像每个部分的边缘或纹理等特定特征,然后将这些特征组合起来detect 人脸等物体。Haar Cascade 比以前的方法要快得多。
与此同时,还引入了诸如方向梯度直方图(HOG)和支持向量机(SVM)之类的方法。HOG 使用滑动窗口技术来分析图像小区域中光线和阴影的变化,从而帮助识别物体的形状。然后,SVM 对这些特征进行分类,以确定物体的身份。这些方法提高了准确性,但仍然在实际环境中表现不佳,并且与当今的技术相比速度较慢。
在 2010 年代,深度学习和卷积神经网络 (CNN)的兴起给目标检测带来了重大转变。CNN 使计算机能够自动从大量数据中学习重要特征,从而大大提高了检测的准确性。
像 R-CNN(基于区域的卷积神经网络)这样的早期模型在精度方面有了很大的改进,与旧方法相比,可以更准确地识别物体。
然而,这些模型速度很慢,因为它们分多个阶段处理图像,这使得它们不适用于自动驾驶汽车或视频监控等领域的实时应用。
为了加快速度,开发了更高效的模型。像 Fast R-CNN 和 Faster R-CNN 这样的模型通过改进感兴趣区域的选择方式并减少检测所需的步骤来提供帮助。虽然这使得目标检测速度更快,但对于许多需要即时结果的实际应用来说,速度仍然不够快。对实时检测日益增长的需求推动了更快、更高效的解决方案的开发,这些解决方案可以平衡速度和准确性。

YOLO是一种物体检测模型,通过对图像和视频中的多个物体进行实时检测,重新定义了计算机视觉,使其与以往的检测方法截然不同。YOLO的架构将物体检测作为一项单一任务来处理,而不是单独分析每个检测到的物体,它利用 CNN 一次预测物体的位置和类别。
该模型的工作原理是将图像分成一个网格,每个部分负责检测其各自区域中的目标。它对每个部分进行多次预测,并过滤掉不太可信的结果,只保留准确的结果。

在计算机视觉应用中引入YOLO 后,物体检测的速度和效率大大超过了早期的模型。由于速度快、精度高,YOLO 很快成为制造、医疗保健和机器人等行业实时解决方案的热门选择。
值得注意的另一点是,由于YOLO 是开源的,因此开发人员和研究人员能够不断改进它,从而开发出更先进的版本。
随着时间的推移,YOLO 型号在每个版本的基础上都在稳步改进。在提高性能的同时,这些改进也使具有不同技术经验的人更容易使用这些模型。
例如,当 Ultralytics YOLOv5推出后,使用PyTorch使更多用户能够使用高级人工智能。它将准确性和可用性结合在一起,让更多人能够实现物体检测,而无需成为编码专家。
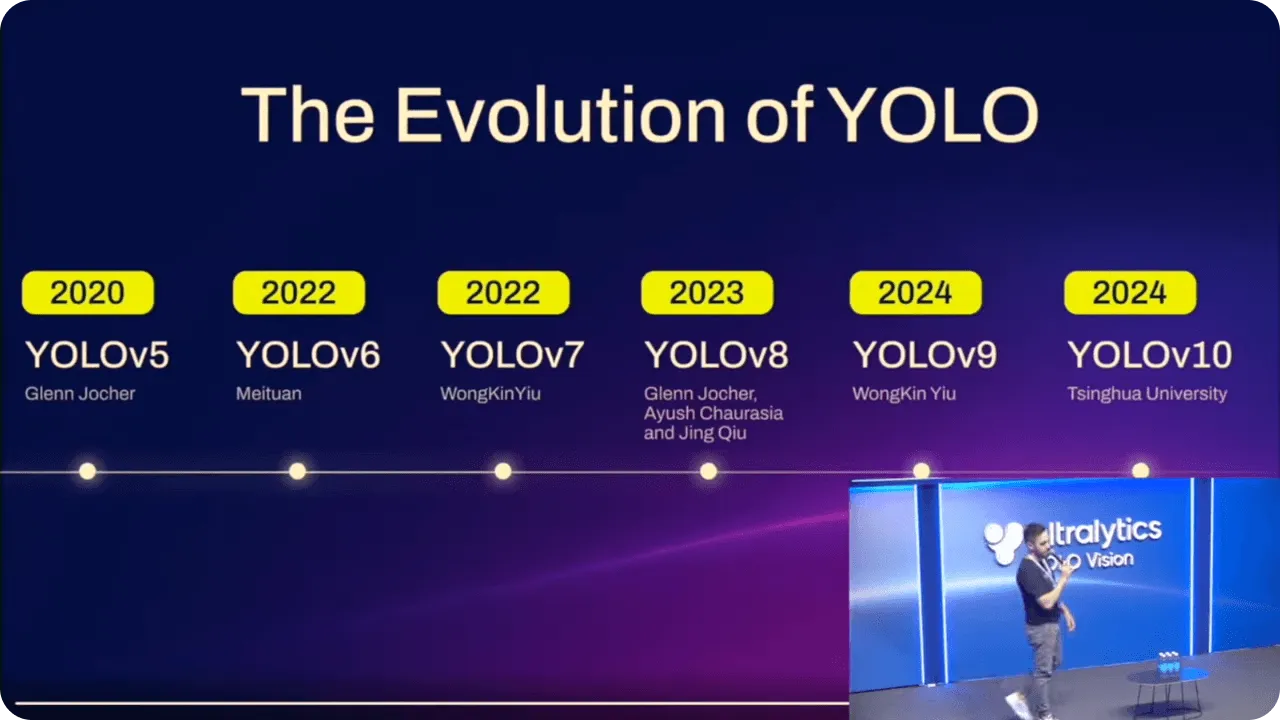
Ultralytics YOLOv8 Ultralytics YOLOv8 通过增加对实例分割等任务的支持,使模型更加灵活,从而延续了这一进步。无论是基本应用还是更复杂的应用,使用YOLO 都变得更加容易,使其在各种应用场景中都能发挥作用。
最新型号 Ultralytics YOLO11进行了进一步优化。通过减少参数数量,同时提高准确性,它现在可以更高效地完成实时任务。无论您是经验丰富的开发人员,还是人工智能领域的新手,YOLO11 都能为您提供先进的物体检测方法。
在Ultralytics的年度混合活动YOLO Vision 2024(YV24)上发布的YOLO11 支持与YOLOv8 相同的计算机视觉任务,如对象检测、实例分割、图像分类和姿势估计 。因此,用户无需调整工作流程,即可轻松切换到这一新模式。此外,YOLO11的升级架构使预测更加精确。事实上,与YOLOv8m 相比,YOLO11m 在COCO 数据集上实现了更高的平均精度mAP),而参数数量却减少了 22%。
YOLO11 还可在从智能手机和其他边缘设备到更强大的云系统等一系列平台上高效运行。这种灵活性确保了实时应用在不同硬件设置下的流畅性能。此外,YOLO11 的速度更快、效率更高,从而降低了计算成本,加快了推理时间。无论是使用Ultralytics Python 软件包还是无代码的Ultralytics HUB,都可以轻松地将YOLO11 集成到现有的工作流程中。
各行各业都已感受到高级物体检测对实时应用和边缘人工智能的影响。随着石油和天然气、医疗保健和零售等行业越来越依赖人工智能,对快速、精确的物体检测的需求不断增加。YOLO11 满足这一需求,即使在计算能力有限的设备上也能实现高性能检测。
随着边缘人工智能的发展,像YOLO11 这样的物体检测模型在对速度和准确性要求极高的环境中进行实时决策时可能会变得更加重要。随着设计和适应性的不断改进,未来的物体检测将在各种应用中带来更多创新。
物体检测已经走过了漫长的道路,从简单的方法发展到今天的先进深度学习技术。YOLO 模型是这一进步的核心,为不同行业提供了更快、更准确的实时检测。YOLO11 在此基础上提高了效率、降低了计算成本并增强了准确性,使其成为各种实时应用的可靠选择。随着人工智能和计算机视觉技术的不断进步,物体检测的前景一片光明,在速度、精度和适应性方面还有更大的提升空间。
对人工智能感到好奇吗?请与我们的 社区 保持联系,继续学习!查看我们的 GitHub 仓库,了解我们如何使用人工智能在 制造业 和 医疗保健 等行业创建创新解决方案。🚀
.webp)

.webp)